
Machine Learning Ontology Clojure Python Digital Transformation Artificial Intelligence Probabilistic Generative Model Web Technology Knowledge Information Processing Technology Natural Language Processing Deep Learning Technology Online Learning Chatbot and Q&A UI Technology Reasoning Technology Zen and AI Navigation of this blog
Dealing with the meaning of symbols on a computer
Meaning can be thought of as some kind of information conveyed by text (or sound or images), as described previously in “Two approaches to the meaning of language (fusion of symbolic and distributed representations).
This information is certain to exist, but it is like dark matter that no one has ever seen, and we cannot see it directly.
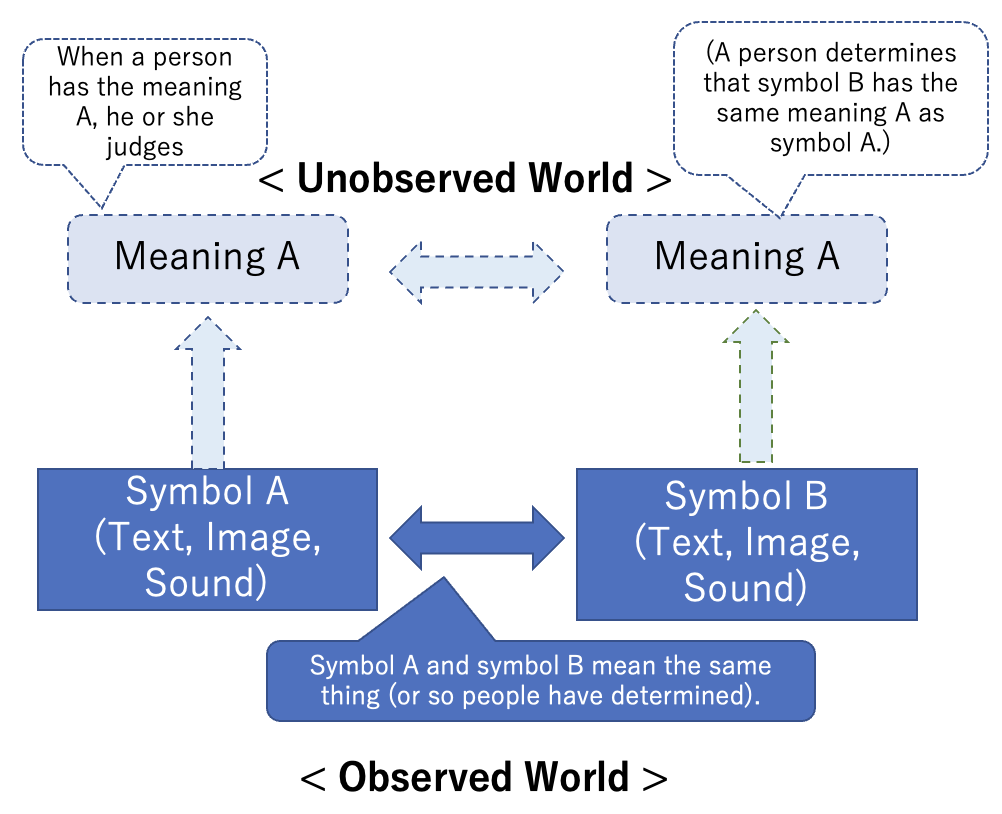
When there is a symbol B, in order to know that its meaning is A, it cannot be confirmed by itself, but only by its relative relationship (connotation, paraphrase, identical, similar, etc.) with other symbols that have the same meaning (or are judged by people to have the same meaning). In other words, “meaning,” which is dark matter, cannot be observed by itself, and the meaning of a symbol can only be defined when there is an object to compare it to.


As mentioned in “Concrete and Abstract – Semantics and Explanation of Natural Language“, this relationship can be imagined by thinking in terms of the abstraction step (the interpretation that what is abstracted from concrete things is what is called black matter in the above).
This can be seen from the fact that “What is Meaning (1) Introduction to Philosophy” and “Saussure’s Linguistics” also state that the meaning of a symbol, which is the basic component of an observed event, is not composed by itself, but is defined by its relationship with other symbols.
Here, we will consider the use of symbols in computers. “As mentioned in “Introduction to Python Programming (1) What is Programming“, the two most important things that computers do are to perform calculations and to remember the results of calculations. Therefore, in order for a computer to be able to handle symbols, it must be able to quantify the object and perform some kind of calculation.
Therefore, in order to handle the meaning of symbols “in the invisible world” with a computer, as shown in the following figure, some quantification work should be done on the symbols to make them into intermediate data, and the intermediate data should be configured to be calculated to match the semantic relationship between the two symbols.
Also, as stated in “Concrete and Abstract – Semantics and Explanation in Natural Language“, abstractions are a collection of concrete things with the same characteristics from a “certain point of view”, and by taking the step of “collecting these abstractions with the same characteristics”, we can infer that they have a hierarchical structure In addition, it can be inferred that these abstractions have a hierarchical structure. It can also be easily inferred that the process of “collecting the same features” can be performed by machine learning procedures.


In other words, when a person judges that symbols A and B are equal (or similar, etc.), he or she can use various methods to convert the symbols into a form that can be calculated (intermediate data), and if they are equal, for example, define a function that will calculate them to be equal. It is important to note that the intermediate data itself is a conversion of the symbol, and does not represent the meaning. Meaning is not given as an absolute thing, but is given by some relative operation between things.
This relative approach to meaning has the following pattern.
- Similarity (A~B)
- Equality (A=B)
- Inclusion (A⊆B)
- Difference (A⋃B)-(A⋂B)
- Overlap(A⋂B)
- Combination (A⋃B)
The term “set” appears in the context of each relationship (inclusion, integration, etc.), but as previously mentioned in “Fundamentals of Computer Mathematics,” set theory can be used to handle the relationships and definitions of things (basic mathematics).
As mentioned in “Concrete and Abstract – Semantics and Explanation in Natural Language“, when we think in terms of abstraction, it is very important to understand that when we say that symbols are similar, what semantic features are similar and what semantic features are not similar depends on the perspective from which we judge them. This perspective is very important.
In order to actually perform calculations on these relationships, we can define functions to operate on each of them, and then we can judge (calculate) the meaning using intermediate data. For example, “similarity” can be defined by the following formula as described in “Basics of similarity (1) Overview“.
Definition 1 (Similarity) Similarity σ : o × o → R is a function from a pair of entities to a real number, denoting the similarity between two objects such that ∀x, y ∈ o, σ(x, y) ≥ 0 (positivity) ∀x ∈ o, ∀y, z ∈ o, σ(x, x) ≥ σ(y, z) (maximality) ∀x, y ∈ o, σ(x, y) = σ(y, x) (symmetry)
In addition, for those that are not similar, they can be defined as follows.
Definition 2 (Dissimilarity) Given a set of entities, the dissimilarity δ:o×o→R is a function that converts from a set of entities to real numbers such that ∀x, y ∈ o, δ(x, y) ≥ 0 (positivity) ∀x ∈ o, δ(x, x) = 0 (minimality) ∀x, y ∈ o, δ(x, y) = δ(y, x) (symmetry)
For δ(x,y), various functions can be defined according to the data format (vector, graph, etc.). For example, there are distance measures between vectors such as cosine similarity, PMMI, TF-IDF, Kullback-Leiber divergence measure, etc., as described in “Teaching the meaning of words to computers (about various language models)” and “Basics of similarity (2) String-based approach“. divergence measure, etc. There is also a method for obtaining Mahalanobis distance as a more general distance evaluation method as described in “Classification (3) Probabilistic Discriminant Function (Logistic, Softmax Regression) and Local Learning (K-Nearest Neighbor Method, Kernel Density Estimation)“.
In this way, the meaning of symbols can be handled by mathematically defining the symbols and their relationships in a form that can be calculated, using the relationships between the meanings of the original symbols as teacher data, and optimizing the data structure and calculation method to match these relationships.
When we assume that symbols A and B are similar, there are various ways to look at the similarity. For example, in the case of figures, it could be the color, the shape, or the category of the concept they point to (for living things or for non-living things). The key to this calculation is the teacher data.
If the teacher data, which is the key to this calculation, is shaky, the results will also be shaky. It is best to define these perspectives from the perspective of the application, which is what the semantic interpretation is used for, and it is necessary to arrange candidate perspectives from these perspectives (or extract and compare similar and dissimilar samples from the perspective of the application) so that a judgment can be made by a person with good reproducibility. It is necessary to be able to do so.
In summary, First, the correct answer data (in the case of similarity, pairs of sentences with similar meanings) is prepared based on strict (use-scenario) criteria., then perform cleansing (normalization) of the data as described in “Basics of similarity (2) String-based approach“. Then, as described in “Two approaches to language meaning (fusion of symbolic and distributed representations)“, we select symbolic and distributed representations for each model and convert them into features (intermediate representations). Then, the semantic approach for each is determined along with the use case, and the appropriate features and calculation method are optimized.


AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.

