
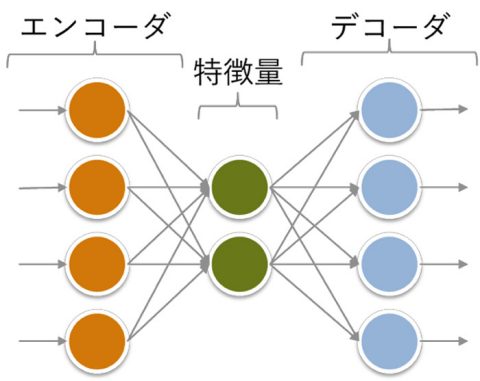
autoencoder
According to the wiki page on deep learning (DNN), “In 2006, Jeffrey Hinton and his team, one of the leading researchers in neural networks, succeeded in deepening autoencoders (self-encoders) with restricted Boltzmann machines [Note 5]. . In 2012, the University of Toronto team led by Jeffrey Hinton shocked machine learning researchers when AlexNet described in “About AlexNet” achieved a dramatic 10% improvement in error rate (17%) over the previous method (26%) in the ILSVRC, an object recognition competition. And so it goes.
I would like to start with Jeffrey Hinton’s paper on autoencoders, “Reducing the Dimensionality of Data with Neural Networks“.
In the autoencoder, the same vector is given to the input and output layers to train them. The idea is to make the number of neurons in the middle layer smaller than in the input and output layers, and to compress the data as features by extracting the output of the middle layer.


MathWorks オートエンコーダーとは*1)
This differs from the data compression algorithms described previously in that the amount of data is not dramatically reduced and there is a large loss, but the compressed vector contains only the important parts of the original data, making it effective for extracting features for pattern recognition.
Another feature extraction method is Principal Component Analysis (PCA). Principal Component Analysis (PCA) finds the direction of the largest variance in a data set and represents each data point as a coordinate along these directions, but in this paper PCA is proposed as a non-linear extension of Principal Component Analysis.
In this paper, PCA is proposed as a nonlinear extension of principal component analysis. Stacked autoencoders are a method of compressing data by repeating the process of compressing vectors compressed by autoencoders in a similar way. Compression
The stacked autoencoder is a method of compressing data by repeatedly compressing vectors in the same way. In Hinton’s paper, 2000 dimensions are compressed to 1000 dimensions, 1000 dimensions to 500 dimensions, and 500 dimensions to 30 dimensions.


Reducing the Dimensionality of
Data with Neural Networksでの特徴量抽出例
In the above literature, a learning method called the Contrastive Divergence Method of Restricted Boltzmann Machines is used.
As for the use of autoencoders, if it is only to produce feature values, I think the method of normalizing data using OpenCV or the like may be practical enough in cases A and B above. A method that learns the correct image and uses it for anomaly detection has been put to practical use.
An implementation using python can be found on the keras website, and DeepLearning4J, a Java deep learning library, can be used with Clojure. I would like to introduce the details of these at another time.
*1) What is Mathworks Autoencoder?


AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.


コメント