
Word2Vec
From “Natural Language Processing with Word2Vec. word2Vec is an open source neural network proposed by Tomas Mikolow et al. In principle, word2Vec is a vectorization of words (200 dimensions with default parameters), and it is capable of positioning words in a 200-dimensional space, looking at the similarity between words (e.g., evaluated by cosine similarity), and performing clustering.
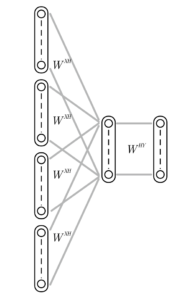
First, word2vec takes as input the five words wt-5, wt-4, . , wt-1, wt+1, … We train a CBOW (Continuous Bag Of Word) neural network as shown in the figure below, which inputs the Bag-of-Words representation of wt+4, wt+5 and outputs the (focused) word wt. (The part of 5 words before and after can be optionally specified)

word2vecを用いた自然言語学習より
To improve computational efficiency, we assume that (1) the coupling from the input layer to the hidden layer is the same regardless of the position of the word. (2) The activation function of the hidden layer is not a sigmoid, but just a constant function f(x) = x. Word2vec has these two features.
Next, as the output layer, we construct a Skip-Gram neural network as shown in the figure below, which reproduces the position in the sentence (context) when a word is input in the reverse direction.


word2vecによる自然言語学習より
In word2vec, these are pieced together to learn in the following way.


word2vecによる自然言語学習より
In this case, we use tex data formatted in the form of “words separated by spaces” and “sentences separated by line breaks” as input/output for learning. The form of this neural network is almost the same as the “autoencoder” introduced previously. The difference is that the aforementioned activation function is made very simple and the link from the input layer to the hidden layer is made uniformly.
From another point of view, this calculation is equivalent to the low-rank approximation (compressed into a 200,000×200 matrix) described in “Relational Data Learning” as shown in the figure below.


word2vecによる自然言語学習
Word2Vec uses the above mechanism to obtain a distributed vector representation corresponding to each word, and when this is combined with the cosine similarity, the similarity between words can be clustered by using clustering tools such as PCA and k-means as described above.
In a general neural network, Yin=x1w1+x2w2+x3w3 and Yout=f(Yin) for input (x1,x2,x3). In this case, f(x) is called the activation function. In general neural networks, threshold function, sigmoid function, and Reftifier function are used (from left to right, threshold function, sigmoid function, and Reftifier function).


word2vecを用いた自然言語処理
More generally, a softmax function described in “Overview of softmax functions and related algorithms and implementation examples” as shown below is used for the activation function of the output layer.
\(\displaystyle Y_i^{OUT}=\frac{\exp(Y_i^{IN})}{\sum_{k}\exp(Y_k^{IN})}\)
In word2vec, the input to the neural network is in 1-of-K format, so compared to the general case, only one digit from the matrix of weights needs to be taken out and calculated, which saves the calculation cost.


word2vecを用いた自然言語処理
Furthermore, word2vec uses “hierarchical softmax” and “negative sampling” described in ‘Negative sampling overview, algorithms and implementation examples’ for efficient computation. In order to select such a hierarchy, “Huffman coding” (words are sorted by the number of times they appear, and then two words are selected from the smallest and put together) is used. In order to select such a hierarchy, we repeatedly perform “Huffman coding” (sorting the words by the number of times they appear, and then selecting two of the smallest ones and grouping them together) until we end up with one tree with two branches. If you paint one of the branches red and arrange the path from the root to the word with red as 0 and black as 1, you can get a rich tree with no duplicates as follows).


word2vecによる自然言語学習より
In this way, the Huffman code is used to group the words into groups where the first row is 0 and the second row is 1, and so on. In this way, words with high frequency are encoded shorter and words with low frequency are encoded longer. In the above example, the longest code is 5, which means that it will be processed 5 times. If we multiply the length of the code by the frequency and calculate the average coding length, we get 2.51, which means that even though there are 8 words, they can be processed in an average of 2.51 times.
Next, we will discuss negative sampling. Negative sampling does not update any neurons in the correct answer layer other than the correct answer neuron, but instead randomly selects about 5 false inputs (the probability of selecting them is 3/4 of the unigram probability (the frequency of occurrence of the word)), and then calculates the probability of getting the correct answer with those false inputs. This negative sampling is an effective method for “repeated learning by adding to the corpus” in situations where the vocabulary set changes.
There are several issues with word2vec. First, it has to deal with “polysemous words”. For example, the word “amazon” can have multiple meanings, such as Amazon of the Amazon River and Amazon of e-commerce, or the word “apple” can be both an apple and the name of a computer manufacturer. However, deep learning approaches, including word2vec, can only estimate a unique variance representation in order to find the optimal solution.
To deal with this issue, there is a generative model approach, which was discussed in the previous sections on “topic models” and “relational data learning”. In this approach, words are generated according to a probability model, and by creating a model using objects such as a mixture of Gaussian distributions, it is possible to deal with polysemous words that generate multiple words.
The next issue is related to similarity. For example, W2V similarity is generally evaluated by cosine similarity, which measures the similarity between vectors, and as a distributed representation, if A and B are similar and B and C are similar, then A and C are also similar. In contrast, in the real semantic world, problems arise when, for example, apples and tomatoes are similar in terms of being red, and apples and green apples are similar in terms of being apples, but tomatoes and green apples are not similar. Such an approach using the structure of relationships requires not only simple machine learning but also a combined approach of “mathematical logic.
The last issue is that the input is greatly affected by the way the words are separated. For example, if “seismometer” and “earthquake” are separated and used as integers in the input to W2V, “seismometer” will be 123 and “earthquake” will be 235, and the words that originally had similar meanings will become different. In addition, if particles consisting of a single hiragana character, symbols such as punctuation marks and parentheses, or numbers, which appear frequently but are not necessary in terms of the meaning of the sentence, are included in the distributed representation without any consideration, the learning results will be biased. In order to prevent this, it is necessary to regularize and cleanse the input data carefully.


コメント