
Summary
Many hardware implementations of machine learning are dedicated hardware. These means include the following
- Use a GPU: A graphics card (GPU) allows processing large amounts of data at a higher speed than a typical central processing unit (CPU). In fact, in many machine learning tasks, the use of GPUs has increased processing speed.
- Use FPGAs: A field programmable gate array (FPGA) is a chip with custom logic that contains programmable circuitry. FPGAs can implement specialized circuitry to optimize performance for machine learning tasks. See also “Introduction to FPGAs for Software Engineers: Machine Learning” for more information on machine learning approaches in FPGAs.
- Use an ASIC: Application-specific integrated circuits (ASICs) are specialized chips that are optimized for a specific task. ASICs specialized for machine learning can process data at high speeds and run the latest deep learning models.
- Use TPUs: Tensor Processing Units (TPUs) are specialized hardware developed by Google and dedicated to deep learning algorithms that perform fast data processing and can process large amounts of data quickly and efficiently.
While these methods can speed up the implementation of machine learning algorithms and make efficient use of hardware resources, they require the implementation of dedicated programs, which can increase development costs. This section discusses the hardware approach to machine learning based on “Thinking Machines: Machine Learning and Its Hardware Implementation.
From Thinking Machines Machine Learning and its Hardware Implementation.

For a hardware approach to AI technology, see also “Application of AI to Semiconductor Design Processes and Semiconductor Chips for AI Applications.
Hardware Implementation Reality – Microprocessor Performance Stagnation
Conventional computer architecture, especially microprocessor architecture, is based on Moore’s Law, which predicts that the number of transistors on a die will double every 1.8 years as semiconductor technology improves. As a result, the clock cycle time during operation can be shortened because the transistor gate length becomes shorter, and the required execution performance (shortening the time required for execution) can be scaled accordingly. In other words, it was possible to roughly estimate how much die area would be available in a given number of years, how much wiring delay would be required, how much operating clock frequency would be required, and how much performance a processor with this many functions would achieve.
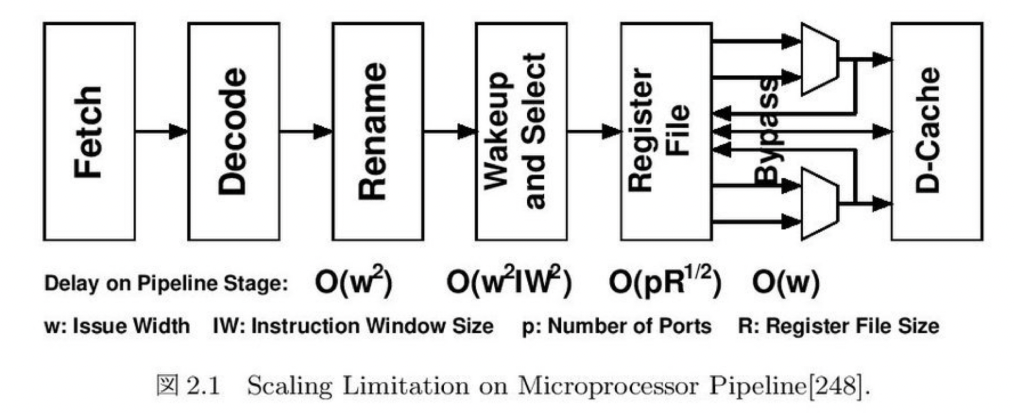
However, from the mid-1990s onward, the performance of these processors became sluggish due to the difficulty of reducing the gate length in relation to the rate of semiconductor process shrinkage, the difficulty of increasing the clock frequency, the deterioration of energy efficiency, and the increasing complexity of the design. The complexity of a circuit can be measured by the critical-path delay, which is the delay time of the longest path in the circuit. The circuit with the longest delay in a pipeline consisting of multiple circuits determines the clock time, or clock frequency, of the synchronous circuit. The figure below shows the longest path delay in each pipeline stage of a pipelined processor in terms of order.


A superscalar processor capable of issuing multiple instructions simultaneously dynamically analyzes the instruction sequence generated by the compiler and executes multiple instructions simultaneously that can be executed to the extent that they do not destroy the program.
Chapter 1 Introduction
1.1 Recognition of Machine Learning
1.2 Machine Learning and Scope of Application
1.2.1 Definition of Machine Learning
1.2.2 Scope of Application of Machine Learning
1.3 Learning and Performance
1.3.1 Preparation before learning
1.3.2 Learning and methods
1.3.3 Performance evaluation and validation
1.4 Positioning of Machine Learning
1.4.1 The Fourth Industrial Revolution
1.4.2 Transaction processing
Chapter 2 Conventional Architecture
2.1 Hardware Implementation Realities
2.1.1 Stagnation of Makuhari Processor Performance
2.1.2 Application of GPUs to Computer Systems
2.1.3 Application of FPGAs to Computer Systems
2.2 Application Specific Integrated Circuits (ASIC)
2.2.1 Application characteristics: local student dependence
2.2.2 Constraints during semiconductor design
2.3 Summary of Hardware Implementation
2.3.1 The computing industry to date
2.3.2 Hardware Implementation of Machine Learning
2.3.3 Classification of Hardware Implementation
2.3.4 History of Machine Learning Hardware Implementation
Chapter 3 Machine Learning and Implementation Methods
3.1 Neuromorphic Computing
3.1.1 Action Potential Timing-Dependent Plasticity and Learning
3.1.2 Neuromorphic Computing Hardware
3.1.3 AER: Advances-Event Representation
3.2 Neural Networks
3.2.1 Neural Network Models
3.2.2 Neural Network Hardware
Chapter 4 Machine Learning Hardware
4.1 Implementation Platforms
4.1.1 Many-Shell Processors (Many-Core Processors)
4.1.2 Digital Signal Processors
4.1.3 GPUs: Graphics Processing Units
4.1.4 FPGAs: Field-Programmable Gate Arrays
4.2 Performance Indicators
4.3 Performance Improvement Methods
4.3.1 Model optimization
4.3.2 Model Compression
4.3.3 Parameter Compression
4.3.4 Data Encoding
4.3.5 Data flow optimization
4.3.6 Zero-skipping operations
Chapter 5 Machine Learning Model Development
5.1 Network Model Development Process
5.1.1 Development cycle
5.1.2 Software stack
5.2 Code optimization
5.2.1 Vectoring and SMD
5.2.2 Memory Access Optimization
5.3 Python Language and Virtual Machine
5.3.1 Python Language and Optimization
5.3.2 Virtual Machine
Chapter 6 Hardware Implementation Examples
6.1 Neuromorphic Computing
6.1.1 Analog Logic Circuit Implementation
6.1.2 Digital Logic Circuit
6.2 Deep Neural Networks
6.2.1 Analog Circuit Implementation
6.2.2 DSP Implementation
6.2.3 FPGA Implementation
6.2.4 ASIC Implementation
6.3 Other Case Studies
6.4 Summary of Examples
6.4.1 Neuromorphic Computing Case Study
6.4.2 Deep Neural Network Case Studies
6.4.2 Comparison of Neural Networks with Neuromorphic Computing
Chapter 7 Hardware Implementation Essentials
7.1 Market Size Projections
7.2 Design and Cost Tradeoffs
7.3 Strategies for Hardware Implementation
7.3.1 Requirements for Strategy Planning
7.3.2 Basic Strategy
7.3.3 External Factors
7.4 Summary: Hardware Design Requirements
Chapter 8 Conclusions
Appendix A Basics of Deep Learning
A.1 Mathematical Models
A.1.1 Forward Propagating Neural Networks
A.1.2 Learning and error propagation methods: updating parameters
A.1.3 Activation functions
A.2 Machine learning hardware models
A.2.1 Parameter space and forward and backward propagation operations
A.2.2 Learning optimization
A.2.3 Numerical accuracy of parameters
A.3 Deep Learning and Matrix Operations
A.3.1 Matrix representation and data size in deep learning
A.3.2 Sequence of matrix operations
A.3.3 Parameter Initialization
A.4 Challenges in developing network models
A.4.1 Bias Variance Problem
Appendix B Advanced Network Models
B.1 CNN Variants
B.1.1 Deep Convolutional Generative Adversarial Networks
B.2 RNN Variants
B.2.1 Highway Networks
B.3 Autoencoder Variants
B.3.1 Stacked Denoising Autoencoders
B.3.2 Ladder Networkd
B.4 Residual Networks
Appendix C. R&D Trends by Country
C1 China
C2 U.S.A.
C 2.1 SyNAPSE program
C 2.2 UPSIDE program
C 2.3 MIGrONS program
C3 Europe
C4 Japan
C 4.1 Ministry of Internal Affairs and Communications
C 4.2 Ministry of Education, Culture, Sports, Science and Technology
C 4.3 Ministry of Economy, Trade and Industry
C 4.4 Cabinet Office
C 4.5 Omnipotent Architecture Initiative
Appendix D Impact on Society
D.1 Industry
D.1.1 Past industries
D.1.2 Future industries
D.1.3 Open Source Software and Hardware
D.1.4 Social business and the sharing economy
D.2 Coexistence of Machine Learning and People
D.2.1 Industries where machine learning can substitute
D.2.2 Consolidation of Industries
D.2.3 The Day the World Becomes Simpler
D.3 Society and the Individual
D.3.1 Programming penetration
D.3.2 Changing Values
D.3.4 Crime
D.4 The State
D4.1 Police and prosecutors
D.4.2 Executive, Legislative, and Judicial
D.4.3 Military Translated with www.DeepL.com/Translator (free version)


AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.


コメント