
AWS Cloud Service Design Patterns (1)
From the Amazon Web Service Cloud Design Pattern Design Guide.

As cloud computing becomes more prevalent, a major shift is taking place in the procurement and operation of computing resources. The cloud has ushered in a new world of IT by making it possible to procure a wide variety of IT resources instantly and inexpensively, as and when they are needed.
In particular, Amazon Web Service (AWS), which has been providing cloud services since 2006, has evolved dramatically, offering a wide range of infrastructure services, including virtual servers, storage, load balancers, databases, distributed queues, and NoSQL services, at low initial costs. AWS offers a wide variety of infrastructure services such as virtual servers, storage, load balancing, databases, distributed queues, and NoSQL services on an inexpensive pay-as-you-use model with no initial costs. Users can instantly procure and use these highly scalable services as and when they need them, and when they no longer need them, they can immediately dispose of them and no longer pay for them from that moment on.
All of these cloud services are publicly available with APIs, so not only can they be controlled from tools on the web, but users can also programmatically control their infrastructure. Infrastructure is no longer physically rigid and inflexible; it is now software-like, highly flexible and changeable.
By mastering such infrastructure, one can build durable, scalable, and flexible systems and applications more quickly and inexpensively than previously thought possible. In this era of “new service components for the Internet age (=cloud),” those involved in designing system architecture will need a new mindset, new ideas, and new standards. In other words, the new IT world needs architects with new know-how for the cloud era.
In Japan, a cluster of AWS data centers opened in March 2011, and thousands of companies and developers are already using AWS to create their systems. Customers range from individual developers who use infrastructure as a hobby, to startups that quickly launch new businesses, small and medium-sized enterprises that are trying to fight the wave of cost reduction with cloud computing, large enterprises that cannot ignore the benefits of cloud computing, and government agencies, municipalities, and educational institutions.
Use cases for cloud computing range from cloud hosting of typical websites and web applications, to replacing existing internal IT infrastructure, batch processing, big data processing, chemical computation, and backup and disaster recovery. The cloud is being used as a general-purpose infrastructure.
There are already examples of businesses and applications that have taken advantage of the characteristics of the cloud to achieve success as new businesses, new businesses, and new services that were previously unthinkable, as well as examples of existing systems that have been migrated to reduce TCO.
However, we still hear of cases of failed attempts to use the cloud, and unfortunately, there are still not many architectures that take full advantage of the cloud. In particular, there are still few cases in which the unique advantages of cloud computing are fully utilized, such as design for scalability, design for failure, and design with cost advantages in mind.
This section describes the Cloud Design Pattern (CDP), a new architectural pattern for cloud computing.
The CDP is a set of typical problems and solutions that occur when designing architectures for cloud-based systems, organized and categorized so that they can be reused by abstracting the essence of the problems and solutions. The design and operation know-how discovered or developed by architects is converted from tacit knowledge to formal knowledge in the form of design patterns that can be reused.
By using CDP, it is possible to
- By leveraging existing know-how, better architectural designs for cloud-based systems will be possible.
- Architects will be able to talk to each other using a common language.
- The cloud will be more easily understood.
The following CDP patterns are described in this issue: “Basic Pattern,” “Availability Improvement Pattern,” “Dynamic Content Processing Pattern,” and “Static Content Processing Pattern. In the next article will discuss “Data Upload Patterns”, “Relational Database Patterns”, and “Asynchronous Processing/Batch Processing Patterns”.
basic pattern
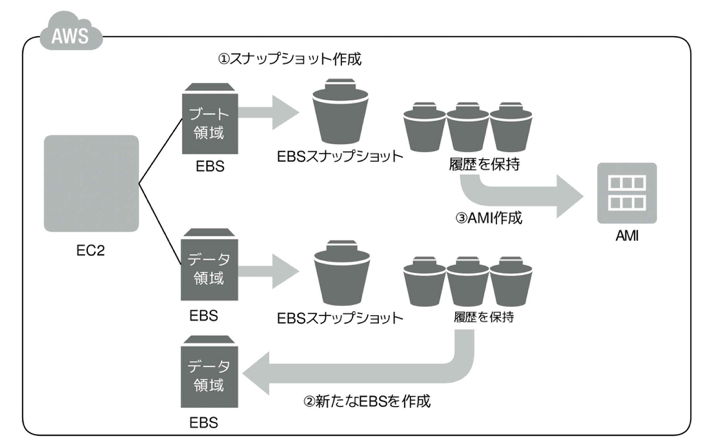
- Snapshot :Backup of data using backups (snapshots) that duplicate data at a given moment using secure, unlimited capacity “Internet storage” in the cloud


- Stamp: Create a machine image of the virtual server with the necessary OS and application settings installed so that it can be copied and reused.


- Scale up: Switch virtual server specifications (CPU, memory size, etc.) in the cloud when server resources become insufficient after operation.


- Scale out: To handle high traffic requests in Web services, there is a “scale-up” approach that uses high-specification machines to increase processing capacity, but this approach is expensive. Therefore, a “scale-out” approach that uses multiple servers with similar specifications to handle high-traffic requests is achieved by load balancing using multiple virtual servers and load balancers.


- Ondemand Disk: Using virtual disks to reserve as much capacity as needed at any desired time, the disk capacity used by the system is reserved on demand while watching the amount of usage.


Availability Improvement Pattern
- Multi-Server: To increase system availability (the ability of a system to operate continuously), multiple virtual servers are lined up and load balancers are used to distribute the load.


- MultiDatacenter: The Multi-Serve pattern is suitable for improving availability when server failures are assumed, but when failures at the data center level (e.g., power outages, earthquakes, network failures) are assumed, the Nulti-Server pattern cannot cope and a distributed system with multiple data centers connected by high-speed dedicated lines is used.


- Floating IP: Server outages are necessary when servers are patched or upgraded (to increase processing power). Since a server outage directly results in a service outage, to minimize the downtime, a backup server should be set up to take over for the service in case of a server outage.


- Deep Health Check: Using the health check functions of the cloud load balancer and DNS, configure dynamic pages (i.e., programs) such as PHP and Javascript to check the health of the entire system by using these programs to check the operation of proxy servers, AP servers, DB servers, etc. and returning the results to the load balancer and DNS.


- Routing-Based HA: Switching connection destinations during failover to servers across segments (subnets) and data centers is achieved by manipulating network routing via APIs.


Dynamic Content Processing Patterns
- Clone Server: In a small-started system, services are not provided by multiple servers and load balancing is not considered. To make the system capable of load balancing, the already existing server is used as the master, a machine image of the server to be added is prepared, and the machine image is started to express load balancing by scale-out.


- NFS Sharing: When load balancing is done on multiple servers, there is a need to synchronize content. Although it is easy to synchronize periodically from the master server to the slave servers unilaterally, periodic synchronization has the problem of delay, and when a write is made on the slave server, it is not reflected on the master server. The system will allow the same content to be read and written in real time between such multiple servers.


- NFS Replica: When using NFS to share files among multiple servers, the performance degradation of the NFS portion cannot be ignored as the number of shared servers increases and the access frequency increases.


- State Sharing: When generating dynamic content, state information (HTTP session information) with user-specific states is often used. However, if multiple Web/AP servers are running under a load balancer and each Web/AP server has its own state information, the state information will be lost in the event of a server failure or when the number of servers is intentionally reduced. To solve this problem, state information is placed in a highly durable shared data store (memory/disk), and multiple servers can reference the information.


- URL Rewriting: When Web services are provided on virtual servers, the number of virtual servers is increased or the specifications of the virtual servers are raised to handle the load when the number of accesses increases. However, since the majority of accesses are often requests for static content, how to distribute access to static content is an issue. As a method of distributing access to such static content, Internet storage can be used to handle the load without increasing the number of virtual servers. To achieve this, the URLs of static content need to be converted to Internet storage URLs, which can be done by directly modifying the static content, using the filter function of the WEb server to change the URLs at the time of delivery, or using a content delivery There are methods to deliver content from a server.


- Rewrite Proxy: One of the load countermeasures is to place static content on an Internet storage or content delivery service. However, it is necessary to change the access destination of static content to Internet storage, which requires modifications to the existing system, such as rewriting URLs in the content and configuring filtering settings on the Web server. On the other hand, a method to change the access destination without modifying the existing system is to deploy a proxy server. A proxy server is placed in front of the server that stores the content, and the access destination for static content is changed to Internet storage or a content delivery service.


- Cache Proxy: The use of multiple Web/AP servers as a load countermeasure increases the cost burden. Therefore, as a means of increasing the performance of the boatyard system without increasing the number of Web/AP servers, content caching (caching static or dynamic content that does not change much upstream of the Web/AP server and delivering the content on an upstream cache server with high delivery performance until the cache expires) is built on a virtual server. The upstream cache server with high delivery performance delivers the content until the cache expires) is built on a virtual server.


- Scheduled Scale Out: The Scale Out pattern is effective when handling high traffic in web services built in a cloud environment. However, if virtual servers are added manually based on the load status, or if instances are added automatically based on the load status of the virtual servers, it will not be possible to launch instances in time for a sudden increase in access (as a rule of thumb, a case in which traffic doubles within 5 minutes). Also, in situations where a large amount of computer resources are to be used only during a certain period of time, there are cases where instance startup should be performed on a time basis. Scheduled scale-out is performed in such cases where the timing is known in advance.


- IP Pooling: In cases where the IP address of the connection source is restricted in order to limit connections, such as when sending mail to a mobile carrier and only accepting mail from a pre-registered IP address, or when restricting the connection source for a service addressed to a designated network, the cloud requires a global IP address to be registered with the service source each time, since it is not possible to specify an IP address. In order to cope with these cases, the necessary IP addresses are secured in advance and registered at the connection point, so that even if the server changes or increases or decreases, the available IP address pool can be searched for and assigned to the server. Allocation.


Static content processing patterns
- Web Storage: Network load becomes a problem when large files such as videos, high quality images, and Zip files are distributed from a single Web server. In such cases, if multiple Web servers are deployed side-by-side to distribute the load in order to reduce the network load, large files are placed on multiple servers, which increases costs. To address this issue, large files are placed in Internet storage, from which the files are directly distributed, thereby solving the problems of network load and disk space on the Web servers. Objects stored in the Internet storage can be set to public settings so that users can access them directly.


- Direct Hosting: If the number of accesses increases rapidly in a short period of time, additional machines will not be sufficient. In contrast, increasing the number of servers in anticipation of increased accesses poses a cost challenge. As a means to address this issue, Internet storage is used as a Web server to host not only large static files such as images and videos, but also HTML files.


- Private Distribution: Internet storage is highly available and durable, and is a good choice for distributing large content or content with a large number of accesses. However, if content is to be distributed only to specific users, it must be linked to the authentication mechanism of the application that created it. It is difficult to achieve such access restrictions with Internet storage. To address this issue, the constrained URL publishing functionality provided by Internet Storage allows the setting of access source IP addresses and access periods for content. By issuing a URL for each user and allowing content to be downloaded only through that restricted URL, content can be distributed only to specific users in effect, with no downloading allowed even if someone with an expired link or a different IP address tries to access the content.


- Cache Distribution: With the proliferation of computers and mobile devices, more and more people can access content on the Internet from many locations. In addition, images and video data are becoming higher quality and the amount of data is increasing dramatically. With current technology, for example, accessing a server on the East Coast of the U.S. from Japan will cause at least a 200 mm communication delay, and the user experience will be degraded if the content originates from only one location. In contrast, by placing cache data of content distributed from the content distributor (original) at locations around the world, it is possible to distribute content from locations geographically closer to the user.


- Rename Distribution: When distributing content through Cache Distribution, even if a file on the origin server is changed, the data on the edge server (cache server) will not be updated until it times out. key, but by placing the file to be updated with a different file name and changing the access URL, new content can be delivered regardless of the cache timeout on the edge server.


- Private Cache Distribution: By using content delivery services that utilize cache locations around the world, it is possible to deliver data to users around the world at high speed. However, when content is to be delivered only to specific users, it is necessary to authenticate users, and it is not easy to build those mechanisms. To address this issue, the “signed URL authentication function” provided by Content Delivery is used. This function issues a “signed URL authentication function” only when the “access source IP address,” “downloadable period,” and “access source region” set in advance when a user accesses a website to download content are met, enabling delivery to specific users with a higher degree of accuracy. This enables delivery to specific users with higher accuracy.


- Latency Based Origin: When using a CDN to distribute the website, firmware, manuals, etc. of a globally deployed product, we want the same URL to be accessed from all over the world for branding purposes. If there is no cache, the user needs to go to the origin server to retrieve the content, which reduces usability. To address this issue, multiple origin servers can be prepared to hold the same content, and when registering the DNS name to be used when accessing the origin, multiple origin server DNSs can be registered for a single DNS, which can then be set to return the origin that is geographically closer.




AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.

