According to wiki, machine learning is defined as “a computer algorithm that automatically improves by learning from experience or its research area. It can be said that machine learning is a future technology that attempts to realize the same functionality in computers as the natural learning ability of humans. It is also an approach that has a philosophical aspect, as well as basic research that essentially considers “what is the ability to learn? In contrast, “machine learning,” a more engineering-oriented definition that focuses on data utilization, has been widely used in recent years. Machine learning is focused on the practical use of predicting unknown phenomena and making judgments based on such predictions by mathematically analyzing data characteristics and extracting rules and structures hidden in the data.
In this engineering perspective, the basic process is to learn from a large amount of training data to find patterns and rules in things and phenomena. Learning from data in this way can be said to be the task of imitating and reproducing as well as possible the rules that generate the data when the training data are generated according to some rules.
Machine learning does this by using the computing power of a computer. This is not simply storing the training data as it is, but clarifying (abstracting) the model (patterns and rules) behind it so that it can be judged when data other than the training data is input. This kind of work is called generalization.
Various machine learning models have been proposed, ranging from very simple ones such as the linear regression model to deep learning with tens of thousands of parameters. What to use among them depends on the data to be observed (number of samples, characteristics, etc.) and the purpose of learning (whether it is just prediction or whether it is necessary to explain the results, etc.).
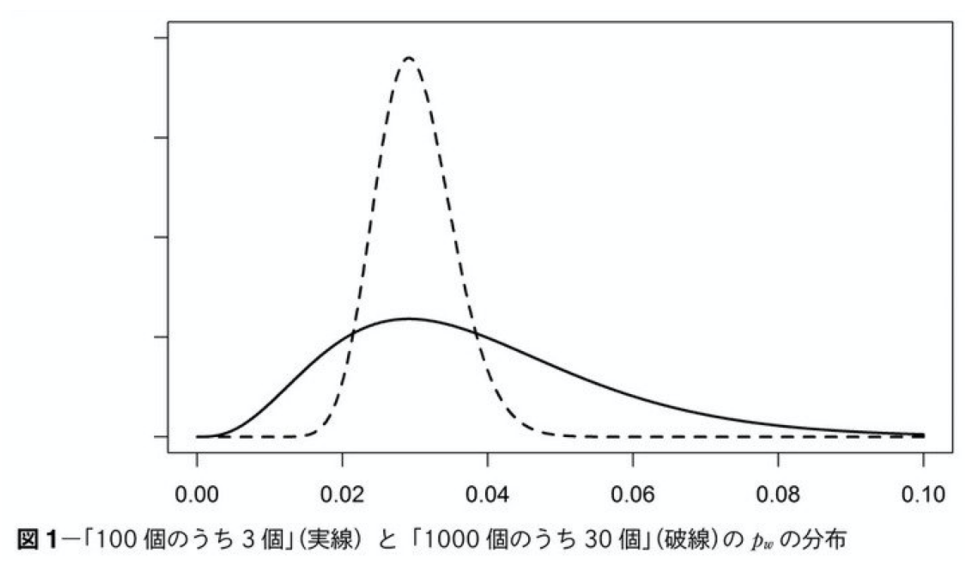
The following is an example of a case where the model required for the above data and purpose differs. First, for the data, the following figure shows the probability distributions for the same percentage of correct answers with different numbers of samples.
Both show the normal distribution of data where 3% of the answers are correct. The wavy line represents the case where there are 1000 samples and 30 correct answers, and the solid line represents the case where there are 100 samples and 3 correct answers. As can be seen from the above, when the number of samples is small, the base widens greatly, and the probability that other than the three correct answers are also correct increases. (The variability increases).
However, as shown above, when the number of training data is small, the variability of each parameter becomes large, and many uncertainties intervene. However, when there is little training data to begin with, as shown above, the variability of each parameter increases, and many uncertainties intervene, and the probability of choosing an incorrect answer increases due to the influence of the variability of each parameter. Therefore, when the number of samples is small, it is necessary to consider a model with fewer parameters, such as a sparse model, to find the answer. (In real life cases, the number of samples is more often small.)
Also, in cases where the purpose of the task is not to simply predict data, but to find out why the data is the way it is (e.g., where judgment is required on the predicted data), it is necessary to consider a white-box approach that uses a certain amount of carefully selected data, rather than a black-box approach that uses a large number of parameters. A white-box approach with some carefully selected data is required.
Putting all this together, we need to consider the following three issues in order to apply machine learning to real-world tasks.
How do you want to solve the problem (including the fundamental question of why the problem is occurring)?
What kind of model should be applied to the problem (consideration of various models)
How to compute those models using realistic computational methods (algorithms)
As for the first point, we need to clearly define how we should interpret the data. It is necessary to clearly define the purpose of the data. This clarification of the purpose is called requirements definition. In general, requirements definition involves analyzing the target domain (or business flow in the case of business), extracting issues from it, and defining functions to solve those issues. KPIs and OKRs are the systematic analysis methods for these issues.
As for the second point, deep learning models have been proposed to deal with a large number of parameters, probability generation models to obtain multiple results instead of a single result, online models to learn while continuously obtaining data, and reinforcement learning to combine learning results and their evaluation values. In this blog, I would like to discuss some of them. In response to these, this blog focuses extensively on deep learning methods, kernel methods, sparse modeling, and other methods that have been called breakthroughs in modern machine learning.
Finally, for the third point, it is necessary to apply efficient computation and various algorithms based on various mathematical theories, such as Bayes’ theorem and other probabilistic theories used in probabilistic generation methods, back propagation methods in deep learning, and norm regularization used in sparse modeling.
From a practical standpoint, machine learning tasks include the following
regression : to find a function for predicting a continuous-valued output from a given input. Linear regression is the most basic regression. (It is called “linear regression” because the parameters are transformed by adding the input vectors together.
Classification : A model in which the output is limited to a finite number of symbols. There are various algorithms, but as an example, logistic regression using sigmoid functions, etc., is used for the actual calculation.
Clustering: A task that divides input data into K sets according to some criteria. Various models and algorithms are available.
Linear dimensionality reduction : This task is performed to process high-dimensional data, which is common in real-world systems. Basically, it is based on linear algebra such as matrix calculations.
Separation of time series data such as signal series : Tasks to predict the connection of data based on probabilistic models. It is also used as a task to recommend what will appear next or to interpolate missing data.
Sequence pattern extraction : Learning sequence patterns of genes, workflows, etc.
Deep learning : Tasks to learn thousands to hundreds of millions of parameters. It can be used to improve results in image processing, etc.
Most machine learning consists of the following three steps abstraction, which extracts features from the data; generalization, which extracts patterns from the features (e.g., classification); and evaluation, which measures the significance of the learned knowledge and encourages improvement. A step consisting of a feedback mechanism. For example, deep learning, which has become a hot topic in recent years, is a technology with breakthroughs in the last of these steps.
There are two major approaches to implementing machine learning. One is “machine learning as a toolbox. This is an approach in which tools based on various algorithms are selected, data is introduced, and final predictions and judgments are made by selecting algorithms with good performance evaluations according to some criteria.
The other is “machine learning as modeling,” in which models (hypotheses) of the data are constructed in advance and the parameters and structures contained in them are inferred from the data. There are two types of modeling methods: statistical methods (generative models) and deep learning systems, which are extensions of toolbox methods. Both methods require sufficient mathematical skills to compute the models, which is a high hurdle, but they offer greater flexibility in application.
With the recent prosperity of DNN, I feel that more and more people are becoming “machine learning absolutists” who believe that the symbolic approach of conventional artificial intelligence has “frame problems” and is “unusable technology” and that machine learning can solve all of its problems and provide answers to anything as long as data is collected. I think this tendency is particularly strong among younger people.
However, human thinking is inseparable from symbolic information, and to deny this is to deny mathematics and physics itself.
The essence of the frame problem is that “a machine with only finite information processing capacity cannot deal with all problems that may occur in reality,” and I think that this applies to all “processing done by machines,” whether symbolic or machine learning. In fact, there is a “no-free-lunch theorem”> in machine learning, which is similar to the “frame problem” in that optimization is not possible without defining regions.
The figure below shows the classification tasks performed by various machine learning methods. (skit-learn:Comparing different clustering algorithms on toy datasets)
You can see that even with the same data, the results differ depending on the learning algorithm.
This blog discusses the following items regarding these machine learning techniques









コメント