
Artificial Intelligence Technology Web Technology Knowledge Information Processing Technology Semantic Web Technology Ontology Technology Natural Language Processing Machine learning Ontology Matching Technology
Continuing from the previous article on natural language similarity from ontology matching..In the previous article, we discussed an approach based on internal structures. This time we will discuss an approach based on external structure.
The basic similarity introduced in the previous article can be considered a local method since it only considers their appropriate characteristics (name, internal structure, extensions) to evaluate the similarity or dissimilarity between two entities. In this article, we will discuss a global method that uses the external structure of an entity instead of its internal structure in order to compare various entities.
If there are nonlinearities in the constraints governing cycles and relational similarity in the ontology, a simple similarity calculation is not possible. Therefore, there is a need to perform iterative similarity computation techniques. These approaches are in the form of approximating the optimal solution to the constraints. The first approach to solving these matching problems is through classical optimization methods. Another global approach is the probabilistic approach, which calculates the probability of related entities based on the structure of the ontology and alignments. Furthermore, there are semantic methods that rely on the global interpretation of ontologies and alignments respectively.
These approaches often rely on an underlying matcher that provides seed alignments and anchors to be improved.
Relational Techniques
An ontology can be thought of as a graph whose edges are labeled with relation names (mathematically speaking, this would be a graph of multiple relations in the ontology with relations such as (⊑, ∈, ⊥, , =)). Finding a correspondence between the elements of two such graphs corresponds to finding a common isomorphic subgraph of both graphs.
Definition 6.1 (Common isomorphic directed subgraphs) Given two directed graphs G = ⟨V , E⟩ and G' = ⟨V', E' ⟩. The common isomorphic directed subgraphs of G and G' are the graphs ⟨V'', E'''⟩ such that W ⊆ V and W' ⊆ V' such that there exists an isomorphic pair f : W → V'' and g : W' → V'' such that - ∀w ∈ V'', ∃u ∈ V ; f(u)=w and ∃v ∈ V'; g(v)=w; - ∀⟨u,v⟩ ∈ E|W × W, ⟨f(u),f(v ) ⟩ ∈ E''; - ∀⟨u′,v′⟩∈ E'|W'×W', ⟨g(u'),g(v') ⟩ ∈ E''.
- r compares entities that are in a direct relationship via the relation r.
- r- compares entities in other dynamic reductions of the relation r; and
- r+ compares entities in the other dynamic closure of the relation r; and
- r-1 compares the entities that come through the relation r.
- r↑ compares the entities that will eventually be included in r+ (the largest element of the closure).
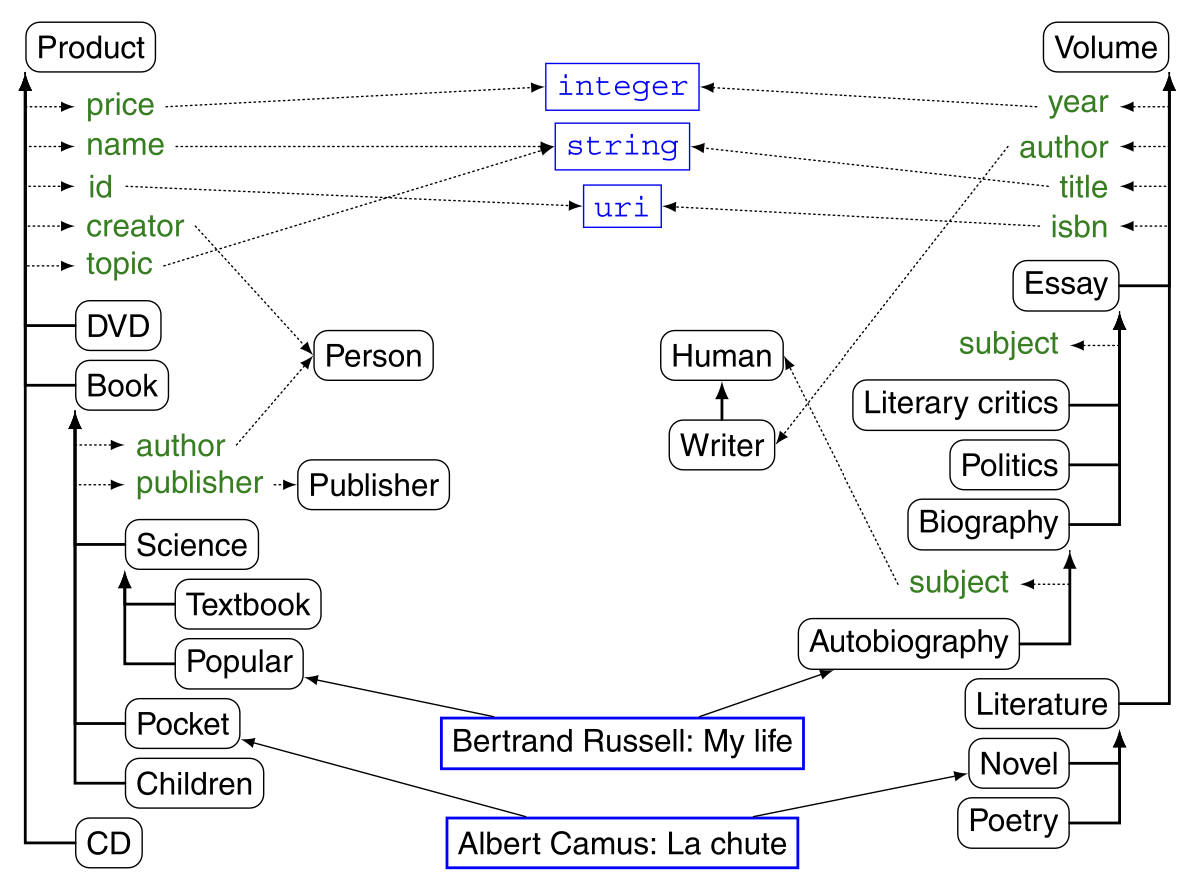
Applying these relations to the previous example of using the ontology relation between Product and Volume (see below), the relation based on the subClass of Book is as follows

subclass(Book) = subclass– (Book) = {Science, Pocket, Children}.
= subclass+ (Book) = {Science, Pocket, Textbook, Popular, Children}
= subclass-1(Book) = {Product}
= subclass↑(Book) = {Textbook, Popular, Pocket, Children}

The table below shows different ways to compare two ontology entities based on their relationships with other entities. Of course, an approach may combine some of the above criteria (Mädche and Staab 2002; Euzenat and Valtchev 2004; Bach et al. 2004).


As can be seen from the above table, some features are of type String and can be compared to the techniques described previously. However, the types Class and Property really cause a graph structure. Furthermore, values labeled with Set(-) are more difficult to handle because it means that many edges labeled with that feature will appear in the graph. The last part of the table is, in fact, related to the extension technique discussed in the previous section.
There are three types of relations that have been considered so far in relational structure techniques: taxonomic relations, meleological relations, and all relations. These are described below.
Taxonomic (taxonomic) structure
Taxonomic structures, i.e. graphs made of subClassOf relations, are the backbone of ontologies. For this reason, it has been studied in detail by researchers and is very often used as a comparison source for matching classes.
Several methods have been proposed to compare classes based on their taxonomic structure. The most common one will be based on counting the number of taxonomic edges between two classes. The structural topological dissimilarity on the hierarchy (Valtchev and Euzenat 1997) follows from the graph distance, i.e., the shortest path distance of the graph, taken here as a transitive reduction of the hierarchy.
Definition 6.3 (Topological structural dissimilarity on hierarchies) The topological structural dissimilarity δ : o × o → R is the dissimilarity on hierarchies H = ⟨o, ≤⟩, such that
\[ \forall e,e’\in o,\ \delta(e,e’)=\min_{c\in o}[\delta(e,c)+\delta(e’,c)]\]
Here, δ(e, c) is the number of intermediate edges between one element e and another element c.
This corresponds to the distance of the unit tree, i.e., each edge with a weight of 1 (Barthélemy and Guénoche 1992). This function can be normalized by the maximum length of the path between the two classes on the taxonomy.
\[ \overline{\delta}(e,e’)=\frac{\delta(e,e’)}{\max_{c,c’\in o}\delta(c,c’)}\]
An example of structural topological dissimilarity is provided based on the taxonomy shown below. Here, we consider that each term corresponds to a class (all meanings are considered together) and that there is a top of the hierarchy (above Person, litterate, legal document, God).


Again, the WordNet data corroborates that the closest classes are writer and author.
The results given by such a measure are not necessarily semantically appropriate, since long paths in the class hierarchy can often be summarized into alternative short paths.
A similar measure is that of Leacock-Chodorow (Leacock et al. 1998), which is a function of the length of the shortest path. This was introduced for lexical classifiers, and a more elaborate measure of this kind is known as the Wu-Palmer similarity (Wu and Palmer 1994). This similarity measure takes into account the fact that two classes close to the root of a hierarchy may be close to each other in terms of edges, but very different conceptually, while two classes below one that are separated by more edges should be conceptually close. The first Wu-Palmer similarity is designed by counting nodes as path lengths, instead of using the usual graph-theoretic edge counting.
Although we prefer to formulate it in terms of edges (Resnik 1999). When used in ontology matching, this difference is largely irrelevant.
Definition 6.5 (Wu-Palmer similarity) The Wu-Palmer similarity σ : o × o → R is the similarity on the hierarchy H = ⟨o, ≤⟩, such that
\[ \sigma(c,c’)=\frac{2x\delta(c∧c’,\rho)}{\delta(c,c∧c’)+\delta(c’,c∧c’)+2x\delta(c∧c’,\rho)}\]
where ρ is the root of the hierarchy, δ(c,c′) is the number of edges between class c and other classes c′, and c∧c′={c′ ∈ o; c ≤ c′ ∧ c′ ≤ c′′}.
The Wu-Palmersimilarity example, Wu-Palmersimilarityalsop, provides a picture consistent with the structure of WordNet.


The cotopic similarity is the application of Jaccard similarity to cotopies. It is described in (Mädche and Zacharias 2002) and is defined as follows.
Definition 6.7 (Upward cotopic similarity) The upward cotopic similarity σ : o × o → R is the similarity on the hierarchy H = ⟨o, ≤⟩, such that
\[ \sigma(c,c’)=\frac{|UC(c,H)\cap UC(c’,H)|}{|UC(c,H)\cup UC(c’,H)|}\]
Here, UC(c,H) = {c′ ∈ H; c ≤ c′} is the set of superclasses of c (superclass+(c)).
In the following example (upward cotopic similarity), all senses are counted as cotopic (not pathologically closest), so the result is different from the other measures. creator, from its position as a superclass of author and illustrator A creator, because of their position as a superclass of author and illustrator, can get a better score than a normal writer-creator pair, but that is because they have too many irrelevant senses.

These measures cannot be applied as-is in the context of ontology matching, since it is assumed that the ontologies do not share the same taxonomy H, but they can be used in combination with common knowledge resources such as WordNet. For this purpose, it is necessary to develop this kind of measure for a pair of ontologies. For example, (Valtchev 1999; Euzenat and Valtchev 2004) uses (local) matching between elements (e.g., hierarchies) to be compared.
Besides these global measures, which consider the entire taxonomy to evaluate the similarity between classes, non-global measures are also used in ontology matching. Some of those measures are introduced below.
Superclass or Subclass Rule : Some matchers are based on a rule that captures the intuition that if the superclasses and subclasses are similar, then the classes are similar. For example, if the superclasses are the same, then the actual classes are similar to each other. If the subclasses are the same, then the classes being compared are similar (Dieng and Hug 1998; Ehrig and Sure 2004). There are at least two drawbacks to this approach. (1) if there are multiple subclasses and superclasses, they will all be mapped to the same class if we are not careful, so we need other discriminators, and (2) the similarity between subclasses and superclasses depends on the similarity of their superclasses and subclasses. These will turn this problem into yet another global similarity problem.
Bounded Path Matching: Bounded Path Matcher takes two paths with links between classes defined by hierarchical relationships, compares terms and their sites along these paths, and identifies similar terms. This technique has been introduced in Anchor-Prompt, described below. For example, in Figure 2.9, if Book corresponds to Volume and Popular corresponds to Autobiography, the correspondence of the elements along the path (Science on the one hand, and Biology and Essay on the other) needs to be carefully examined. For example, it is to determine that Essay is more general than Science. This method is mainly guided by the anchoring of the two paths and uses alternative methods to select the best match.
The edit distance can also be applied to structures other than strings, especially trees (Tai 1979).In the next article, I will discuss another method of global matching, the meleological approach.


AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.


コメント