
Overview of RAG(Retrieval-Augmented Generation)
Retrieval-Augmented Generation (RAG) is a technique that has attracted attention in the field of natural language processing (NLP), which combines retrieval (Retrieval) and generation (Generation) of information to build models with richer context. The main objective of RAG is to build models with richer context by combining Retrieval and Generation. This technology is derived from the “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks” issued in 2021.
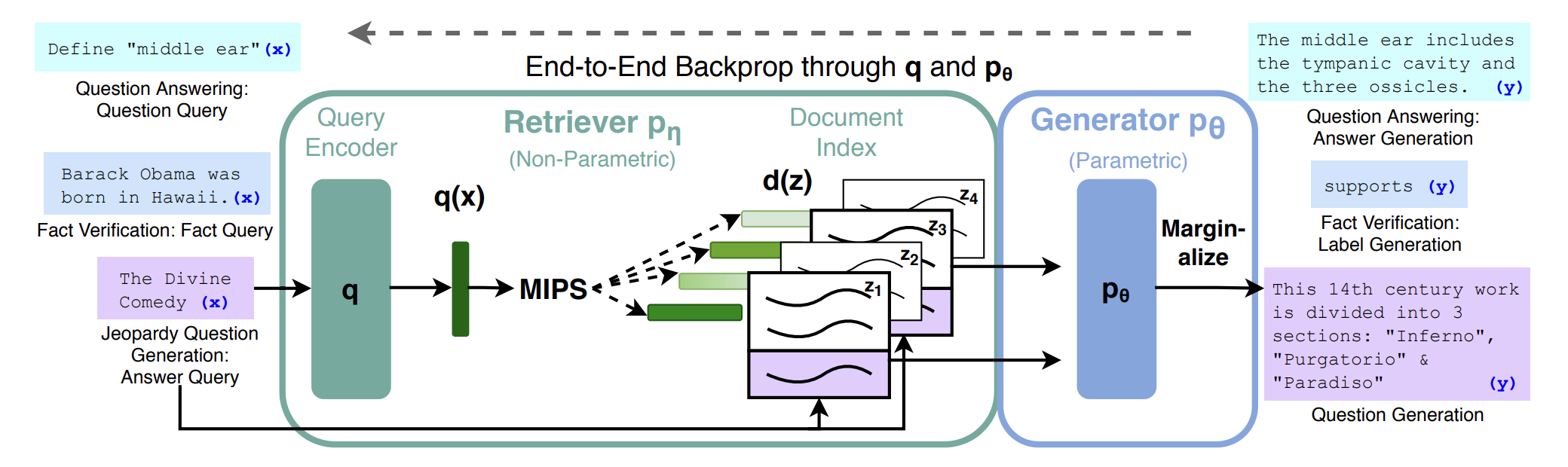
The RAG is constructed as follows (from the above paper).


The basic structure is to vectorize input queries with Query Encoder, find Documnet with similar vectors, and generate responses using those vectors. Vector DB is used to store the vectorized documents and to search for similar documents.
The main purpose of RAG is to generate higher quality results by utilizing retrieved information in generative tasks (sentence generation, question answering, etc.). While ordinary language models are generated by considering only the given context, RAG is characterized by its ability to incorporate external information, thereby utilizing a wider range of knowledge and context. RAGs are characterized by their ability to take advantage of a wider range of knowledge and context by incorporating external information.
RAGs consist of three main components
1. Retrieval: RAGs have a mechanism for retrieving information relevant to a given question or context. Various approaches to retrieval are available as described in “Retrieval Techniques” but the most popular approach in recent years is to vectorize the data to be retrieved using a method called embedding, which is also described in “Overview of Multilingual Embedding, Algorithms and Implementations. The data is then stored in a vector database as described in “Overview of Vector Databases“, and information is retrieved using indices such as cosine similarity as described in “Similarity in Machine Learning“.
2. Ranking: From the results of information retrieval, ranking is performed to select the most appropriate context and information. It is important to find the most appropriate information for the generation task among the retrieved information.
3. Generation: Finally, based on the information retrieval and ranking, the model performs a generative task (e.g., generating sentences, answering questions, etc.). The goal is to generate more relevant and natural sentences based on the selected information.
The advantages of RAGs include “rich contextualization,” which allows the model to obtain a wider range of knowledge and context through retrieval from external sources, “increased reliability,” which improves the quality of information used for generation through ranking, and “diversity and adaptability,” which allows for flexible generation by obtaining information from a variety of sources. and adaptability.
RAGs have been widely applied to NLP tasks such as question answering, information retrieval, dialogue systems, and sentence generation, and are particularly effective in dialogue systems using large knowledge bases and question answering systems based on search results.
Algorithms related to RAG (Retrieval-Augmented Generation)
The following is a description of the algorithms and methods involved in RAG.
1. algorithms for Retrieval: The first step in RAG is to retrieve information related to a given input from external data sources. Algorithms and methods related to information retrieval include the following See also “Similarity in Machine Learning” for similarity determination as a basis for information retrieval.
TF-IDF (Term Frequency-Inverse Document Frequency): Calculates the similarity between documents by considering the word frequency and inverse document frequency, and retrieves the most relevant documents based on the similarity between the search query and documents.
BM25 (Best Matching 25): Calculates the similarity between documents based on the occurrence of words in the documents and ranks search results considering the similarity between the search query and documents.
Neural Retrieval Models: There are also information retrieval models using neural networks, with Transformer-based architectures and BERT (Bidirectional Encoder Representations from Transformers) Transformer-based architectures and BERT (Bidirectional Encoder Representations from Transformers) based retrieval models are common.
2. Ranking Algorithms: It is important to rank the candidate documents and information retrieved by information retrieval in an order suitable for the generation task, and the algorithms and methods used in this process include the following. One well-known ranking algorithm is page rank, which is described in “Overview and Implementation of the Page Rank Algorithm. For an overview of ranking algorithms, see also “Overview of Ranking Algorithms and Examples of Implementations.
Learning to Rank: Learning a ranking model to rank search results appropriately. Methods such as neural networks and random forests are used.
BM25F: An extended version of BM25 that considers information in multiple fields (title, body text, etc.). Information is weighted and an overall score is calculated.
BERT-based Ranking Models: There are ranking models that use language models such as BERT to achieve rankings that consider the meaning and context of the text.
3. algorithms for Generation: Based on information retrieval and ranking, the final generation task (e.g., generating sentences, answering questions and responses, etc.) is performed. Algorithms and methods used here include the following. See also “Automatic Generation by Machine Learning” for details.
Transformer-based Models: Language models based on the Transformer architecture, such as GPT-3, GPT-4, BERT, and T5, are used. They learn the parameters for generating sentences and perform context-aware natural generation.
Template-based Generation: This method will use pre-defined templates to generate sentences by combining information. By filling in the templates, appropriate answers and sentences are generated.
Controlled Text Generation: This method generates text according to specific conditions and styles. Constraints and guides are given to the model to control the generated results.
4. End-to-End Approach: RAG combines a series of steps, such as information retrieval, ranking, and generation, to perform the task end-to-end. Therefore, these algorithms and methods are integrated to build the model. A representative tool that integrates these tools is LamgChain, as described in “Overview of ChatGPT and LangChain and its use” and “Agents and Tools in LangChain“.
Application of RAG (Retrieval-Augmented Generation)
The following are examples of RAG applications.
1. Question and Answer (QA) systems: RAGs are effectively used in Question and Answer (QA) systems, which retrieve relevant information from external sources for a given question and generate an answer based on that information. Specific applications include the following
Medical QA: Question-and-answer systems for making appropriate diagnoses based on patient symptoms.
Educational QA: Question-and-answer systems for providing explanations that are easy for learners to understand.
2. dialogue systems: In dialogue systems, RAGs are also used to achieve natural and rich dialogue. by using RAGs, information is obtained from external knowledge bases and corpora to augment the flow of dialogue. Specific applications include the following
Customer support: a dialogue system that provides more accurate and detailed answers to customer questions and problems.
Virtual assistants: dialogue agents with rich information for user requests and queries.
3. sentence generation and summarization: RAGs are also used to generate and summarize more specific and precise sentences based on a given context or question. Examples of specific applications include the following
News article summarization: The system generates summaries and key points from a large number of news articles.
Report generation: Systems that generate detailed reports and explanatory text from input data and information.
4. information retrieval and document rewriting: RAG is also used in systems that combine information retrieval and information rewriting (reconstruction) to reuse or provide information. Specific applications include the following
Sentence rewriting: A system that rewrites input sentences to provide information from a different perspective or style.
Document similarity search: A system that searches for documents with similar content for a given query.
5. building and updating knowledge bases: RAG is also used to acquire information from external sources and to build and update knowledge bases. by using RAG, a series of processes from information acquisition to generation can be automated to improve the quality of knowledge bases. Specific applications include the following
Corporate knowledge base: Construction of a knowledge base that collects information and procedures within a company and provides it for employees and customers.
Creation of educational materials for educational institutions: A system that acquires information from textbooks and articles to generate new teaching materials and content.
RAGs provide effective solutions for a variety of natural language processing tasks by leveraging external information to create language models with richer context.
Examples of RAG (Retrieval-Augmented Generation) implementations
Examples of RAG (Retrieval-Augmented Generation) implementations have been developed in various forms in the field of natural language processing (NLP), and specific RAG implementations are described below.
1 RAG combining DPR (Dense Passage Retrieval) and Hugging Face Transformers: Hugging Face is a framework that provides a transformer-based language model, and DPR (Dense Passage Retrieval) is a model for information retrieval. Combining these two models makes it possible to implement RAGs. These procedures are described below.
1. retrieve relevant passages from an external corpus using DPR
2. input the retrieved passages into a Hugging Face language model (e.g. GPT-3, BART, etc.) and perform the generation task
3. combine the ranked passages with the generated sentences to generate the final answer or sentence.
See also “Overview and Implementation of RAG with DPR and Hugging Face Transformer” for details.
2 Facebook RAG: An implementation of the RAG provided by Facebook AI Research, which is a model that combines information retrieval and generation to generate sentences based on retrieved passages.
3. T5X-RETRIVAL: T5X-RETRIEVAL is an implementation of the RAG proposed by google-research. This model combines T5 (Text-To-Text Transfer Transformer) and information retrieval.
4. Example of implementing a home-made RAG model : If you want to implement your own RAG model, you can generally use ChatGPT’s API or LanChain, as described in “Overview of ChatGPT and LangChain and their use”. The general procedure is as follows
1. collect necessary information from external sources, embed it, and store it in a vector database
2. embed user questions, extract similar information from the vector database, and pick up data for answers from the ranked data.
3. generate final answers and sentences based on the picked data.
For details, see “Overview of RAGs using ChatGPT and LanChain and Examples of Implementations.
RAG (Retrieval-Augmented Generation) Issues and Measures to Address Them
Retrieval-Augmented Generation (RAG) is a method that combines information retrieval and generation to build models with rich context, but several challenges exist in its implementation and application. The following describes some of the challenges of RAG and how they are addressed.
1. accuracy and efficiency of information retrieval:
Challenge: The performance of RAG is highly dependent on the quality of documents and passages retrieved during the information retrieval phase, and it is necessary to efficiently and accurately retrieve highly relevant information from large data sets.
Solution:
Improved information retrieval methods: use modern information retrieval methods such as TF-IDF, BM25, Neural Retrieval Models, etc. to retrieve relevant documents and passages.
Selection of appropriate information sources: Select the most appropriate information sources (e.g., web corpora, specialized documents, knowledge bases, etc.) according to the task and data.
Caching and preloading: frequently used information should be cached or preloaded to improve search efficiency.
2. appropriate adjustments to rankings:
Challenge: It is important to rank the most appropriate information among multiple documents and passages obtained in the information retrieval phase, and appropriate adjustment of ranking methods and learning of models are required.
Solution:
Trainable ranking model: The ranking model can be trained by machine learning to improve the ability to select the most appropriate information.
Human feedback: Improve ranking methods by incorporating human judgment.
Ensure diversity: Adopt a ranking method that takes diversity into account and reflects different perspectives and information sources.
3. model size and processing time:
Challenge: RAG is a complex system that combines a large-scale language model and an information retrieval model, which takes time and resources to process.
Solution:
Optimize the model: Make the model lighter and faster to improve processing speed.
Use parallel processing: Use GPUs and distributed processing to improve processing speed through parallelization.
Caching and preloading: Some information is obtained in advance and reused to reduce processing time.
4. accountability and transparency:
Challenges: It is sometimes difficult to explain the rationale or reason for the answers or statements generated by the RAG. The main reason is that the internal behavior of the model is a black box and lacks transparency.
Solution:
Introduce interpretable AI techniques: Introduce techniques to visualize model behavior and important information to improve explanatory power.
Extracting rationale: Introduce techniques to extract statements and information that provide rationale for the responses generated.
Research to improve transparency: Introduce techniques for transparency and explainability of AI as described in “Various Explainable Machine Learning Techniques and Examples of Implementation” etc.
5. data bias and domain adaptation:
Challenge: RAG training data may contain biases that cause problems specific to a particular domain and may be difficult to adapt to new domains and tasks.
Solution:
Data bias detection and correction: detect biases and correct the dataset to generate fair and unbiased responses.
Use domain adaptation methods: Use transfer learning described in “Overview of Transfer Learning and Examples of Algorithms and Implementations” and domain adaptation methods to adapt to new domains and tasks.
Ensure data diversity: train models with data from different domains and genres to increase generalizability.
Reference Information and Reference Books
For details on automatic generation by machine learning, see “Automatic Generation by Machine Learning.
Reference book is “


“


“


“




AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.


コメント