
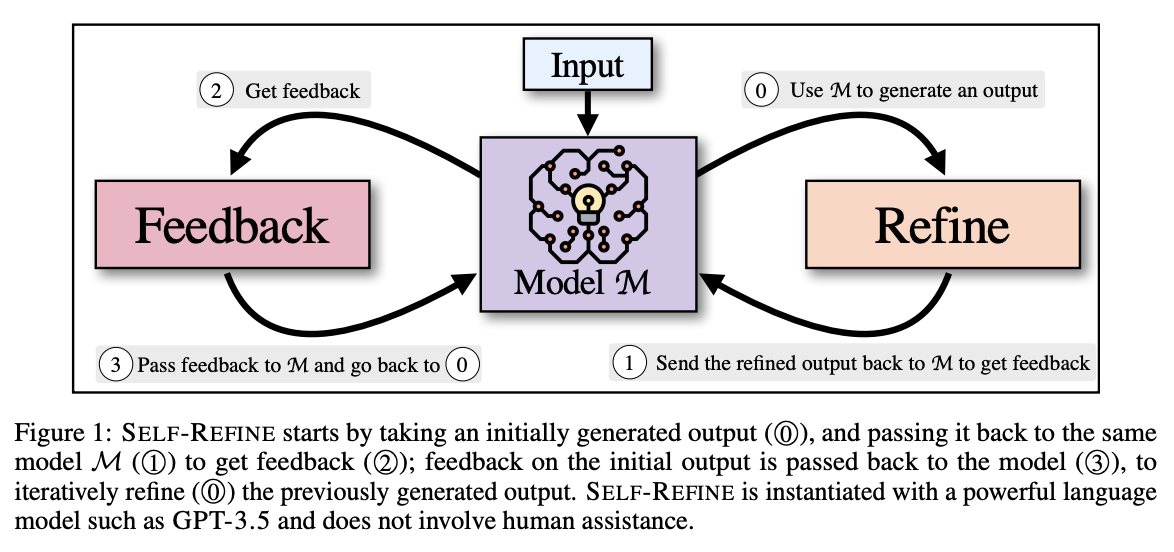
Overview of Self Refine
“GPT-4 or higher? Self-Refine: Iterative Refinement with Self-Flavour“, researchers from Carnegie Mellon University, the Allen Institute for Artificial Intelligence, the University of Washington, NVIDIA, UC San Diego and Google Research have published a paper titled “Self-Refine: Iterative Refinement with Self-Flavour”. In the paper “Self-Refine: Iterative Refinement with Self-Feedback“, researchers from Carnegie Mellon University, Allen Institute for Artificial Intelligence, University of Washington, NVIDIA, UC San Diego and Google Research have shown that large-scale language models (LLMs) can be iteratively improved to produce higher quality output. It is stated that they proposed a new framework that allows iterative refinement and self-evaluation to be used to generate higher quality output.
Iterative refinement, a fundamental feature of human problem-solving, is the process of first producing a draft and then improving it through self-feedback. For example, even an email text has a step of finishing by proofreading and revising many times.
This study examines whether LLMs can effectively replicate such human cognitive processes by proposing a framework for iterative feedback and refinement, Self-Refine. Unlike previous research, this approach does not require supervised training data or reinforcement learning, but uses a single LLM.
Self-Refine consists of an iterative loop with two components, Feedback and Refine, which work together to produce high-quality output. Given the first output proposal generated by the model, it is iteratively refined over and over again, going back and forth between the two components Feedback and Refine. This process is repeated a specified number of times, or until the model itself decides that no further refinement is necessary.


Specifically, given an initial output, Feedback evaluates it and generates actionable feedback for modification; Refine takes that feedback into account and refines the output; and the output is then used as the basis for a new output. These are repeated.
Experiments have conducted extensive testing on seven tasks, including story generation, code optimisation and abbreviation generation, and results have shown that Self-Refine improves by at least 5% and up to 40% over direct generation from powerful generators such as GPT-3.5 and GPT-4.
Self Refine is summarised below.
Algorithms related to Self Refine
Algorithms related to the ‘self refine’ functionality in artificial intelligence technologies aim to improve the performance of models through self-improvement and iterative learning. The following are some examples of such algorithms.
1. recurrent neural networks (RNNs): RNN described in “Overview of RNN and examples of algorithms and implementations” are suitable for working with continuous data and are a particularly effective approach for time series data and natural language processing RNNs self-refine by reflecting past outputs on current inputs.
2. Stochastic Gradient Descent (SGD): SGD described in “Overview of Stochastic Gradient Descent (SGD), its algorithms and examples of implementation” is an optimisation algorithm used to update the parameters of a model. By updating the parameters in small batches rather than for the entire dataset, the computational cost is reduced and the model converges faster. The following is the basic procedure of SGD.
import numpy as np
def stochastic_gradient_descent(X, y, theta, learning_rate=0.01, epochs=100):
m = len(y)
for epoch in range(epochs):
for i in range(m):
rand_index = np.random.randint(0, m)
xi = X[rand_index:rand_index+1]
yi = y[rand_index:rand_index+1]
gradients = 2 * xi.T.dot(xi.dot(theta) - yi)
theta = theta - learning_rate * gradients
return theta3. the Self-Attention Mechanism: the Self-Attention Mechanism described in “About ATTENTION in Deep Learning” is widely used as part of the Transformer architecture. It models the relationships between different parts of the input sequence and allows focusing on important information, and self-attention mechanisms are used in models such as BERT and GPT.
import torch
import torch.nn as nn
class SelfAttention(nn.Module):
def __init__(self, embed_size, heads):
super(SelfAttention, self).__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
assert (
self.head_dim * heads == embed_size
), "Embedding size needs to be divisible by heads"
self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.fc_out = nn.Linear(heads * self.head_dim, embed_size)
def forward(self, values, keys, query, mask):
N = query.shape[0]
value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]
values = values.reshape(N, value_len, self.heads, self.head_dim)
keys = keys.reshape(N, key_len, self.heads, self.head_dim)
queries = query.reshape(N, query_len, self.heads, self.head_dim)
energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])
if mask is not None:
energy = energy.masked_fill(mask == 0, float("-1e20"))
attention = torch.softmax(energy / (self.embed_size ** (1 / 2)), dim=3)
out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(
N, query_len, self.heads * self.head_dim
)
out = self.fc_out(out)
return out4. reinforcement learning (Reinforcement Learning): reinforcement learning described in “Overview of reinforcement learning techniques and various implementations” is a method by which agents learn measures to maximise rewards through interaction with the environment and includes algorithms such as Q-learning and policy gradient methods.
import numpy as np
class QLearningAgent:
def __init__(self, state_size, action_size, learning_rate=0.1, discount_factor=0.99, exploration_rate=1.0, exploration_decay=0.995):
self.state_size = state_size
self.action_size = action_size
self.learning_rate = learning_rate
self.discount_factor = discount_factor
self.exploration_rate = exploration_rate
self.exploration_decay = exploration_decay
self.q_table = np.zeros((state_size, action_size))
def choose_action(self, state):
if np.random.rand() <= self.exploration_rate:
return np.random.choice(self.action_size)
return np.argmax(self.q_table[state])
def learn(self, state, action, reward, next_state):
best_next_action = np.argmax(self.q_table[next_state])
td_target = reward + self.discount_factor * self.q_table[next_state][best_next_action]
td_error = td_target - self.q_table[state][action]
self.q_table[state][action] += self.learning_rate * td_error
self.exploration_rate *= self.exploration_decay5. meta-learning (Meta-Learning): meta-learning described in “Overview and implementation examples of Meta-Learners that can be used for Few-shot/Zero-shot Learning” and “Overview of causal inference using Meta-Learners and examples of algorithms and implementations“, also known as ‘learning by learning’, where models learn to adapt quickly to new tasks, with MAML (Model-Agnostic Meta-Learning) being the leading algorithm.
import torch
class MAML:
def __init__(self, model, inner_lr, outer_lr, inner_steps):
self.model = model
self.inner_lr = inner_lr
self.outer_lr = outer_lr
self.inner_steps = inner_steps
self.optimizer = torch.optim.Adam(self.model.parameters(), lr=self.outer_lr)
def inner_update(self, loss):
grads = torch.autograd.grad(loss, self.model.parameters(), create_graph=True)
updated_params = [param - self.inner_lr * grad for param, grad in zip(self.model.parameters(), grads)]
return updated_params
def outer_update(self, meta_loss):
self.optimizer.zero_grad()
meta_loss.backward()
self.optimizer.step()These algorithms support the process of self refinement and help AI systems to self-improve over time.
Examples of Self Refine applications
Specific examples of the application of the ‘self refine’ function in artificial intelligence technologies include the following. These examples aim to provide more accurate and reliable results through an iterative process for AI systems to evaluate and improve their own output.
1. sentence generation in natural language processing:
Self-improvement with GPT models:
– APPLICATION: Large-scale language models such as OpenAI’s GPT-3 and GPT-4 produce more consistent, grammatically correct and meaningful sentences through a process of self-improvement.
– Methods:
1. generating initial output: generating initial output based on input text.
2. evaluation: the generated output is evaluated and scored according to specific criteria (e.g. grammar checking, semantic coherence, etc.).
3, Regeneration: in the case of low ratings, feedback is given to the model and the output is regenerated. 4, Finalisation of output: the output is finalised.
4. finalising the final output: selecting the output with the highest rating as the final result.
2. accuracy improvement in image recognition:
Automatic label correction:
– Application: in image recognition systems, to self-evaluate initial predictions and improve the accuracy of labels.
– Methods:
1. Initial prediction: make an initial prediction for an image.
2 Evaluation: evaluate the prediction results based on a confidence score.
3. Correction: for low-confidence predictions, change the pre-processing (e.g. adjusting image brightness and contrast) and re-predict.
4. finalise the final prediction: select the high-confidence prediction as the final result.
3. policy improvement in reinforcement learning:
Policy optimisation in Q-learning:
– Application: a reinforcement learning agent self-improves its game-playing strategy.
– Methods:
1. initial policy generation: select actions based on an initial policy.
2 Evaluate: evaluate the reward for each behaviour and update the Q-value.
3 Policy modification: modify the policy to select better behaviours based on the Q-value.
4 Iterate: repeat this process several times to optimise the policy.
4 Adaptation to new tasks by meta-learning: adapt to new tasks by meta-learning:
Model adaptation with MAML:
– Applications: applications that need to adapt quickly to new tasks (e.g. new types of image classification).
– Methods:
1. inner update: perform an inner update to quickly adjust the model to the new task.
2. evaluation: evaluate performance against the task.
3. outer update: update the overall model parameters based on meta-learning algorithms.
4. iterative: this process is repeated several times to adapt the model to the new task.
5. route planning in self-driving vehicles:
route optimisation by self-evaluation:
– APPLICATION: Self-improving route planning in self-driving vehicles to ensure safe and efficient driving.
– Methods:.
1. initial route planning: plan an initial route based on the current situation. 2.
2. evaluation: assess the safety and efficiency of the route (e.g. traffic volume, road conditions, predicted time, etc.).
3. re-planning: for routes with low ratings, re-plan taking into account the new information;
4. final route selection: the route with the highest rating is selected as the final route to be travelled.
These examples illustrate specific applications of self refine and are used to improve AI performance in various fields.
Examples of Self Refine implementations
An example of an implementation of a ‘self-refine’ function in artificial intelligence technology is the following method. This feature aims to provide more accurate and reliable results through an iterative process in which the AI model evaluates and improves its own output.
Example implementations of self-refine in natural language processing:
Initial output generation: generate initial output based on input data.
from transformers import GPT2LMHeadModel, GPT2Tokenizer
model = GPT2LMHeadModel.from_pretrained('gpt2')
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
input_text = "What are some examples of the implementation of SELF REFINITION in artificial intelligence technology?"
inputs = tokenizer.encode(input_text, return_tensors='pt')
outputs = model.generate(inputs, max_length=100)
initial_output = tokenizer.decode(outputs[0], skip_special_tokens=True)Evaluation of outputs: the outputs generated are evaluated and scored according to specific evaluation criteria.
def evaluate_output(output_text):
# Here, as a provisional evaluation function, the number of characters is used as a score
return len(output_text)
score = evaluate_output(initial_output)Modifying outputs: modifying outputs based on assessment results. For example, regenerate outputs based on specific criteria or reflect modifications.
refined_output = initial_output
while score < threshold:
refined_output = model.generate(tokenizer.encode(refined_output, return_tensors='pt'), max_length=100)
refined_output = tokenizer.decode(refined_output[0], skip_special_tokens=True)
score = evaluate_output(refined_output)
Finalisation of the final output: after repeated modifications, the output with the highest rating is finalised as the final result.
final_output = refined_output
print(final_output)Examples of self-refine implementations in image recognition:
Initial prediction: initial prediction is made on the input image.
import torch
from torchvision import models, transforms
from PIL import Image
model = models.resnet18(pretrained=True)
model.eval()
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_image = Image.open("path_to_image.jpg")
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0)
with torch.no_grad():
initial_output = model(input_batch)Evaluating outputs: apply evaluation criteria to the predicted results and calculate a score.
def evaluate_output(output):
# Use the score of the prediction with the highest confidence as a provisional evaluation function
return torch.max(output).item()
score = evaluate_output(initial_output)Modifying output: if confidence is low, change image pre-processing and re-predict.
while score < threshold:
# For example, reprocessing by changing the contrast of the image.
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ColorJitter(contrast=2.0), # Adjust contrast.
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0)
with torch.no_grad():
refined_output = model(input_batch)
score = evaluate_output(refined_output)
Finalisation of the final forecast: after repeated revisions, the forecast with the highest rating is finalised as the final result.
final_output = refined_output
print(final_output)Challenges and measures for self refinement
Several challenges exist for the ‘self refine’ function in artificial intelligence technologies. The main challenges and their remedies are listed below.
1. biases in training data:
Challenge: biases present in the training data can be amplified through the self refine process, resulting in biased output results.
Solution:
– Ensure data diversity: ensure training data is diverse and balanced.
– Bias detection and correction: implement methods to detect and correct biases at the data pre-processing stage.
– Active learning: use user and expert feedback to continuously improve datasets.See also “Active Learning Techniques in Machine Learning” for details.
2. overfitting:
Challenge: models over-adapt to training data, leading to poor generalisation performance.
Solution:
– Regularisation techniques: use techniques such as L1/L2 regularisation and drop-out to reduce model complexity.
– Cross-validation: split the data and cross-validate to assess the generalisation performance of the model.
– Data expansion: use data expansion techniques to increase the data set and prevent overfitting.
3. increased computational costs:
Challenge: the self refine process consumes a lot of computational resources and increases processing time.
Solution:
– Efficient algorithms: select and optimise algorithms with low computational cost.
– Distributed processing: use cloud computing or GPU clusters to distribute the computation.
– Incremental learning: utilise incremental learning, where models are retrained only on new data.
4. instability of the feedback loop:
Challenge: the self-assessment and improvement loop can be unstable, making model convergence difficult.
Solution:
– Feedback control: introduce appropriate controls in the feedback loop to ensure stable convergence.
– Adaptive learning rate: dynamically adjust the learning rate to ensure stable learning.
– Error checkpoints: monitor errors at each step and adjust the direction of improvement.
5. uncertainty handling:
Challenge: it is difficult to properly assess and handle uncertainty in the results output by the model.
Solution:
– Bayesian approach: use Bayesian estimation to explicitly model uncertainty in outputs.
– Ensemble learning: combining multiple models to offset the uncertainty of individual models and obtain more reliable results.
– Confidence scores: calculate a confidence score for each prediction and pay attention to predictions with high uncertainty.
6. scalability:
Challenge: there is a scalability issue when applying self refine to large data sets and complex models.
Solution:
– Distributed learning: distribute data and computations to make learning on large datasets more efficient.
– Efficient data processing: efficiently pre-process and filter data, feeding only the necessary parts into the self refine process.
– Hardware utilisation: utilise high-performance hardware and dedicated accelerators (e.g. TPUs, FPGAs) to improve computational efficiency.
Reference Information and Reference Books
For details on automatic generation by machine learning, see “Automatic Generation by Machine Learning.
Reference book is “


“


“


“


“Reinforcement Learning: An Introduction“ by Richard S. Sutton and Andrew G. Barto
“Deep Learning“ by Ian Goodfellow, Yoshua Bengio, and Aaron Courville
“The Fifth Discipline: The Art and Practice of the Learning Organization“ by Peter M. Senge
“Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation“ by Jez Humble and David Farley
“Atomic Habits: An Easy & Proven Way to Build Good Habits & Break Bad Ones“ by James Clear


AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.


コメント