
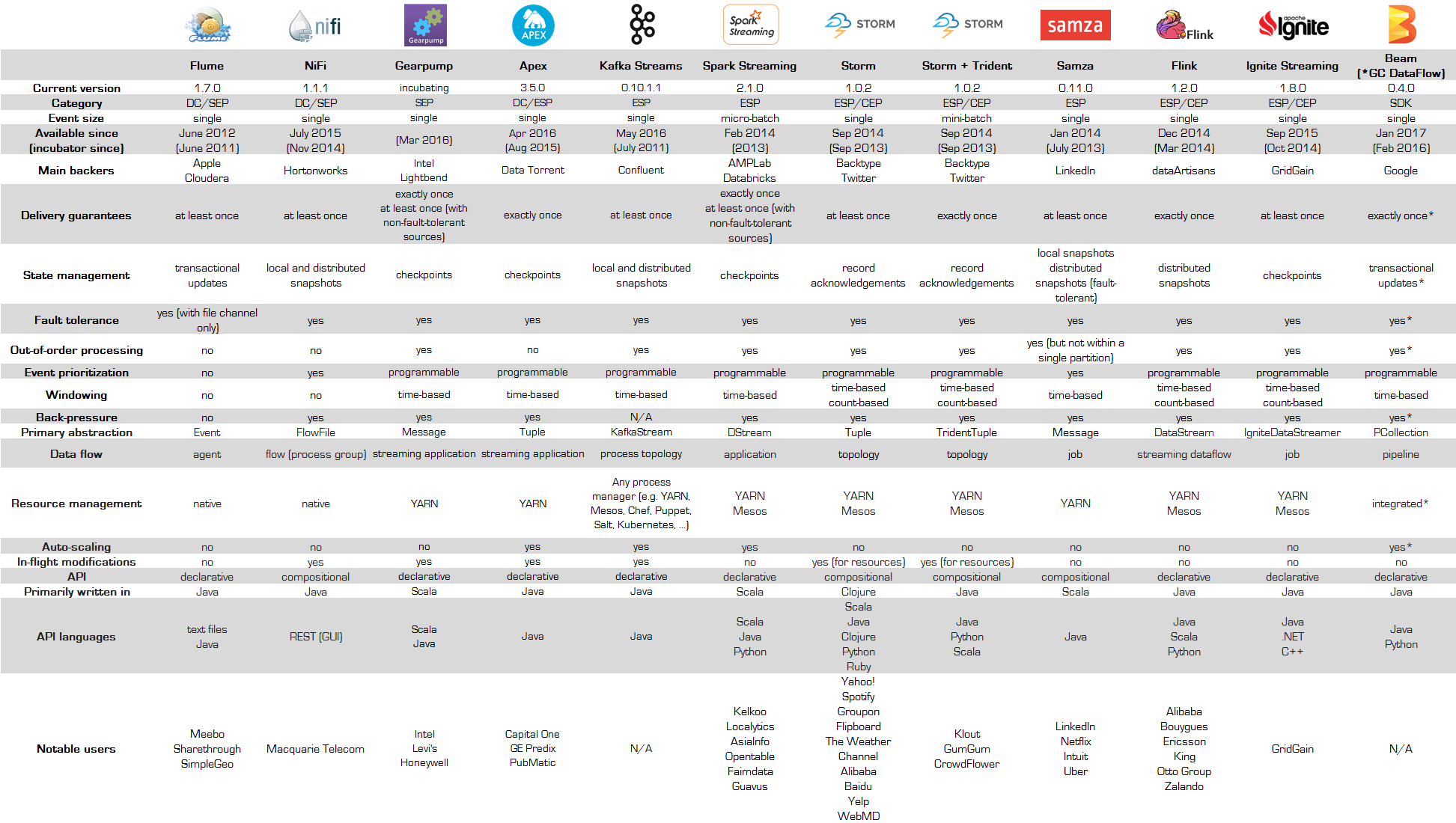
Apache Streaming technologies
A summary of the distributed platform for stream processing provided by Apche.


Data acquisition system
- Flume
The original product for distributed data collection, similar to Fluentd.
It was introduced as part of the Hadoop ecosystem, but we don’t hear much about it these days. - Kafka Streams
A messaging system originally developed by LinkedIn that supports Pub-Sub messaging, but also functions as a queue.
It is fast, fault-tolerant, and can be dynamically scaled out.
Data flow/ETL (Extract/Transform/Load) systems
A type that processes event data in real time.
- Nifi
Released as OSS by the U.S. National Security Agency (NSA).
Data flow can be defined by WebUI, and trade-off between reliability and performance, dynamic change, etc. are possible.
Bidirectional flow is possible.
Stream Processing System
- Storm
An OSS released by Twitter, it is the spark that ignited the distributed stream processing platform.
In addition to Yahoo and Spotify, it is also used in Thunder, Salesforce’s IoT platform, and is available as a platform in Hortonworks and Microsoft Azure.
It is available as a platform in Hortonworks, Microsoft Azure, etc. There are two types: Storm Core, which is a Spout/Bolt configuration that processes as a single event, and Storm Trident, which operates as a micro-batch.
Storm Core is At Least Once, and Storm Trident is Exactly Once. - Spark Streaming
A real-time processing engine for Spark, which is increasingly being used as a member of the Hadoop family, as Hadoop is increasingly integrated with Spark (for batch processing).
It runs as a micro-batch, and although it is said to support Exactly Once, it is At Least Once for fault tolerance.
It was often compared to Storm, but nowadays I think Flink is the competitor. - Apex
An OSS released by DataTorrent.
It is based on YARN and works with Hadoop.
Exactly Once. - Samza
Like Kafka, Samza was developed by LinkedIn. Therefore, it is easy to integrate with Kafka. - Flink
Flink is highly fault-tolerant and can automatically recover and continue processing even if it goes down.
It supports not only stream processing but also batch processing, and has a machine learning library.
Exactly Once. - Ignite
Ignite has the characteristics of an in-memory data grid, and can be integrated with Spark.
It supports a variety of queries, including Scan queries, SQL queries, and text queries.
At Least Once. - Gearpump
Gearpump is designed for high throughput and low latency.
Compatible with Storm and Samza.
Can support both At Least Once and Exactly Once. - Beam
An OSS version of the Google Cloud Dataflow model. It supports both stream processing and batch processing modes.
As a backend, Flink, Spark, and Google Cloud Dataflow can be used, and it is possible that Google is aiming to integrate a stream processing engine.
Auto-scaling is supported.
Exactly Once.
Points to consider when choosing
- Performance and fault tolerance
Stream processing is a real-time process, so performance is definitely important. However, fault tolerance is just as important. Every product claims to be fault-tolerant, but the reliability of messages such as “At Least Once” or “Exactly Once” differs, and the programming model for when a failure occurs also differs depending on the product. Depending on the method of data collection and storage, where to ensure reliability may also vary, so it is necessary to consider the overall architecture of the system. - Single-Event vs Micro-Batch
In some cases, such as Storm, both are supported due to differences in programming models, and in other cases, such as Spark Streaming, it is specialized for Micro-Batch.
The Single-Event method has less latency per message, but Micro-Batch makes it possible to perform aggregate processing in a short time span. - Streaming + Batch
With Spark/Spark Streaming, both stream and batch processing are supported. In some cases, such as Flink and Beam, a single product can support both.
When considering the entire system, there are many cases where both stream and batch processing are used, so you may want to choose one that takes such requirements into account. - Programming model
While Storm, for example, uses a low-level API to achieve processing, Spark Streaming/Flink provides a high-level API, allowing implementation without much awareness of distributed processing (this also tends to make it more difficult to isolate when a failure occurs). - Operability
When a large amount of data is streamed, it is not possible to check the operation by outputting logs (a large amount of logs will be output).
This is why the management console screen is so important. If you can check throughput, error information, etc. on the management console screen, it makes operation easier.
Functions such as the ability to notify other systems when a failure occurs are also important. Translated with www.DeepL.com/Translator (free version)


AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.


コメント