
Artificial Intelligence Technology Web Technology Knowledge Information Processing Technology Semantic Web Technology Ontology Technology Natural Language Processing Machine learning Ontology Matching Technology
Continuing from the previous article on ontology matching. In the previous article, we discussed alignment extraction. This time, we will discuss alignment disambiguation improvement.
Alignment Improvement
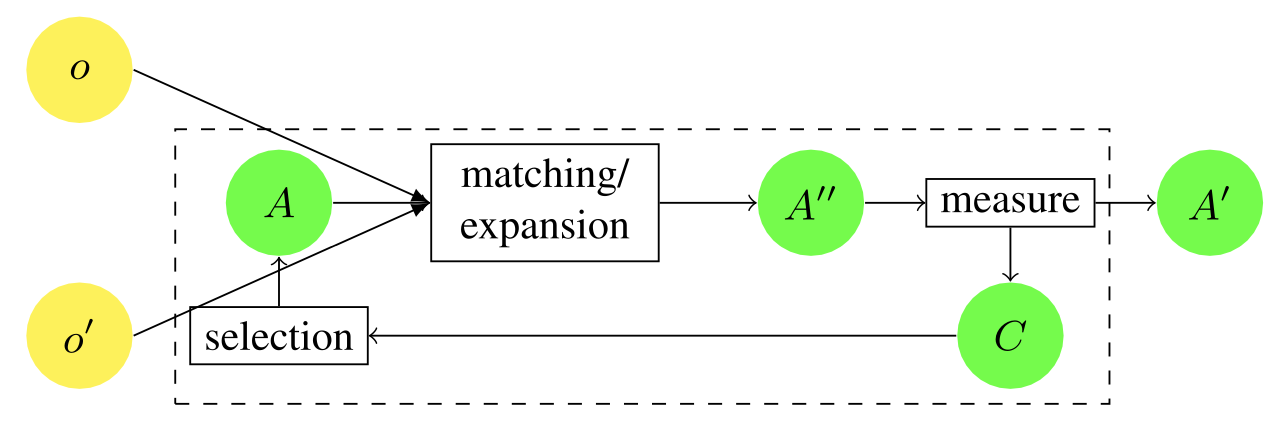
Improving alignment means measuring the quality of the generated alignment, reducing the alignment so that the quality is improved, and in some cases, repeating the process of expanding the resulting alignment. A typical improvement process is shown in the figure below. There are several possibilities for the initial alignment reduction, so we need to choose the one to use. Once the measurements reach a certain threshold, an alignment is selected as a result of this process. If the selected alignment is not fed back to the matcher, but provided as a direct output, the improvement acts as an alignment filter.


General alignment improvement framework. The first alignment (A′′) is generated by the matcher. This is evaluated based on inherent measures (consistency, agreement, constraint violation) to determine a set of compatible subalignments (C). One of these is selected and fed back to the process as the input alignment (A) so that the matcher can improve it. This process is iterated until the scale shows a satisfactory value, and the last calculated alignment (A′) is finally returned.
The refinement process can be done manually, with the user controlling each step and possibly weaving in other operations, or it can be done automatically, with the matcher embedding the refinement. The user can contribute (1) by indicating that a particular set of correspondences is incorrect (instead of a measure), or (2) on behalf of a selected component.
Quality measures are the main ingredient for improvement. They are the essential measures of alignment. Such measures may include the following.
- Confidence threshold or average confidence level.
- Cohesion measure between matched entities, i.e., the number of adjacent entities that are matched to each other.
- Degree of ambiguity, i.e., the percentage of classes that match more than one other class.
- Agreement or disagreement between aligned ontologies (d’Aquin 2009).
- Violation of constraints (e.g., acyclicity of corresponding paths).
- Satisfaction of syntactic anti-patterns
- Consistency and coherence
Alignment disambiguation
An example of such a method is alignment disambiguation. An alignment is when one entity matches several other entities (assuming the relationships are equivalent), e.g., ? 😕 An alignment becomes ambiguous if, for example, we are looking for an alignment but a *:* alignment is returned.
Therefore, a measure could be the degree of ambiguity, i.e., the percentage of classes that match multiple other classes, or a Boolean indicator, i.e., whether an alignment is ambiguous or not. A simple way to deal with this problem would be to always select the correspondence with the highest confidence (greedy algorithm), or to compute the subalignment with the largest weight.
Another solution is based on the idea that a correct match between two classes tends to have other correct matches between its more general and more specific entities (Tordai 2012). Therefore, in this method, for each ambiguous correspondence, we count the proportion of correspondences that can be reached from both sides by subclasses of the relevant class. Then, the correspondence with the highest ratio is retained. Thus, for any pair of ambiguous correspondences ⟨e,f,=⟩ and ⟨e,g,=⟩
If|{⟨e′,f′,=⊑∈A;e′ ⊑e∧f′ ⊑f}|>|{⟨e′,g′,=⊑∈A;e′ ⊑e ∧g′ ⊑g}|, then ⟨e, g, =>⊑ can be preserved; otherwise, ⟨e, f, => is preserved.
If the number of more specifically matched entities is the same, no correspondence can be selected. The same technique cannot be used with more general entities, such as superclasses instead of subclasses. This technique applies to the invalidation of the same type of optimization techniques that were used to extract the matches and alignments.
Debugging Alignment
Debugging alignments or repairing alignments aims to restore the consistency and cooperativity of the generated alignments. Consistency refers to the fact that the aligned ontology does not have a model, and consistency refers to the fact that the model of the aligned ontology does not allow a particular class to have an instance. The measure applied depends on the semantics given to the alignment.
A comprehensive framework for alignment repair based on diagnosis theory has been developed by (Meilicke and Stuckenschmidt 2009; Meilicke 2011) et al. (Minimal inco-herence, or unsatisfiability, preserving subalignments (MIPS)), defined as a minimal set of correspondences that generate inconsistencies and inconsistencies, and diagnostics to restore consistency and coherence to the alignment. It is defined as an inclusive minimal subset. The relationship between these concepts is that the minimal set of hits (taking one correspondence from each MIPS) is a diagnosis.
The concept of optimality of a diagnosis is defined as maximizing the reliability of the repaired alignment. This optimization can be applied to the case where the correspondences to be suppressed from each MIPS are selected individually (locally optimal diagnosis) or globally (globally optimal diagnosis). In general, the globally optimal diagnosis is smaller than the locally optimal diagnosis.
Example of Debugging Alignment Consider the alignment shown in the figure below.


This is an incoherent arrangement. The reason this is incoherent is that the class “Person” cannot have instances. The reason for this incoherence is that the class “Person” cannot have an instance, otherwise it would become “Biography”, which is assumed to be separate from “Person”, which would become “Book”.
There are four correspondences in Alignment A.
\[ \begin{eqnarray} &c_1& &Book\geq_{.8}Essay&\\&c_2&&Person\geq_{.7}Biography&\\&c_3&&topic=_{.6}subject&\\&c_4&&Person\geq_{.9}foaf:Person& \end{eqnarray}\]
The system can use incoherent patterns (or anti-patterns) such as {X⊥Y, ⟨X ≤ Z⟩, ⟨Y ≥ W ⟩, Z ⊑ W }. Using reduced semantics, this pattern implies that X cannot have any extension. This is because otherwise, this extension would be included in Y’s, which is assumed to be disjoint. This pattern is instantiated at the two corresponding points c2 and c1 of alignment A. A matcher using such a pattern may decide to discard c2 because of its low confidence (.7).
However, this alone is not sufficient to make the alignment coherent. In fact, the topic property will never have a value. The alignment contains two minimum unsatisfiable preserving subalignments (MUPS), {c1, c2} and {c1, c3, c4}. As a result, there are three diagnoses. ({c1}, {c2, c3}, and {c2, c4}) In general, the system will recheck the impact of the change on the alignment and pull back c1 (globally optimal). However, the system can choose another diagnosis, e.g. {c2 , c3 }. However, the system can choose another diagnosis, such as {c2 , c3 } (locally optimal), based on the average confidence level or other metrics.
This alignment is also ambiguous because Person is matched to both Biography and foaf:Person. If we disambiguate by selecting the correspondence with the lowest confidence, c2 will be discarded.
Use Case The LogMap system uses a logical reasoner to identify inconsistent or incoherent classes. To cope with large ontologies, LogMap uses an incomplete reasoner. It selects the correspondence with the lowest confidence level from the set of smallest correspondences that cause inconsistencies The ASMOV system detects inconsistencies by means of inconsistency patterns and corrects the alignment before final delivery The inconsistency patterns used by ASMOV are semantically The inconsistency pattern used by ASMOV is semantically correct, but not perfect. ASMOV rejects some of the correspondences in these patterns based on their confidence level and repeats the matching process. It can also be thought of as a constraint-based debugging tool using user-provided constraints.
Since the ontology does not have disjoint axioms, ontology repair techniques by inconsistency detection cannot be applied. To learn how to generate disjoint axioms, naive Bayesian classifiers can be used (Meilicke et al. 2008). Such a classifier is trained on various datasets and uses different similarity features (path distance, shared properties, similarity, instance set) of pairs of classes to determine which classes are disjoint.
This type of technique can also be applied to networks of ontologies, if the ontology is given a semantics. Since repairing alignments at such a scale is very difficult, both computationally and for the user, (Zurawski et al. 2008) proposed to restore consistency only in the sphere that is the local set of ontologies and alignments.
ALCOMO6 (Applying Logical Constraints On Matching Ontologies) will be developed based on these research results. ALCOMO6 will not be an ontology matcher, but a library of tools to compute MIPS, MUPS, and diagnostics in a complete or constraint-based manner. It provides a library of tools to compute MIPS, MUPS, and diagnostics on a full or constraint basis. This allows the measurement and selection part of Fig. 7.16 to be implemented independently of the matcher. It also includes a method to pre-generate the optimal incoherence avoidance alignment from the similarity matrix by advancing the coherence detection one step before the matching process.
Summary of Alignment Improvement
Alignment improvement can be integrated into the matcher, or it can be considered as a separate, after-the-fact activity. We decided to consider alignment improvement separately because it is independent of matching and alignment extraction technologies, and can be applied to alignments made with any technology. Therefore, any system can improve its alignment based on such technologies. We have presented only clearly defined techniques for improving alignment. Other techniques can be developed in the same spirit, as can be seen from the list of criteria given at the beginning of this section.
similarity Summary
We have presented the strategic issues involved in creating a matching system, both when using basic matchers and when using more advanced global methods. Specifically, the combination of basic matchers, the aggregation of the results, and the extraction of alignments. The use of learning algorithms and strategies to improve the extracted alignments was also described.
The art of ontology matching systems can be a delicate art of combining basic matchers in the most advantageous way. In this chapter, we present techniques for assembling the components of a matching system. In most cases, the appropriate architecture depends on the problem to be solved. Is there a basic, independent matcher that can be applied to the data? Is the data very complex? Are there users who can evaluate the results? Do the expected results have to be injectable? These questions are important components of a methodology, and answering them will bring together the various components.
The methods presented in this chapter are often a matter of trade-offs for various requirements, such as between completeness and correctness of alignment in threshold applications, and between quality and computational time in the choice of global similarity computation.
The figure below shows a fictitious example that combines several methods. Specifically, we (1) run several basic matchers in parallel, (2) aggregate their results, (3) select some correspondences based on their (dis)similarity, (4) extract an alignment, (5) repair or disambiguate this alignment, and (6) if necessary, repeat this Repeat the process as needed.


Other chapters in ontology Matching describe how various implemented systems utilize the discussed techniques and how they are organized into coherent system-tems.


AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.


コメント