
オートエンコーダー
深層学習(DNN)のwikiのページを読むと「2006年にニューラルネットワークの代表的な研究者であるジェフリー・ヒントンらの研究チームが、制限ボルツマンマシンによるオートエンコーダ(自己符号化器)の深層化に成功[注釈 5]し、…2012年には物体の認識率を競うILSVRCにおいてジェフリー・ヒントン率いるトロント大学のチームが”AlexNetについて“で述べているAlexNetによって従来の手法(エラー率26%)に比べてエラー率17%と実に10%もの劇的な進歩を遂げたことが機械学習の研究者らに衝撃を与えた。」とある。
このジェフリーヒントンのオートエンコーダーの論文である「Reducing the Dimensionality of Data with Neural Networks」から今回は述べたいと思う。
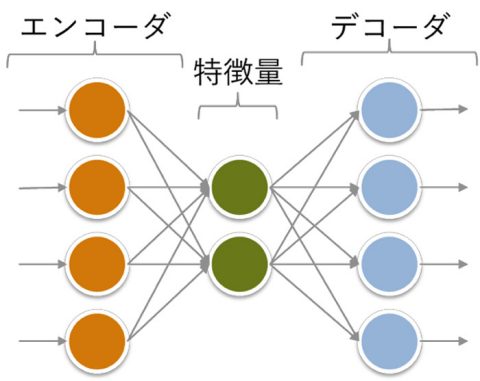
オートエンコーダーは、入力層と出力層に同じベクトルを与えて学習させる。この時、中間層のニューロンの数を入出力層より小さくし、中間層の出力を取り出すと、データの特徴量として圧縮できるというアイデアとなる。


MathWorks オートエンコーダーとは*1)
これは以前述べたデータ圧縮のアルゴリズムによるものと異なり、データ量が劇的に減るわけではなく、ロスも大きいが、圧縮されたベクトルは元データの重要な部分だけを含むので、パターン認識として特徴量を抽出するのに効果的なものとなる。
また特徴量の抽出手法としては主成分分析(PCA)がある。主成分分析(PCA)は、データセット内の最大の分散の方向を見つけ、各データポイントをこれらの方向に沿った座標で表したものだが、この論文ではPCAを主成分分析を非線形に拡張したものであるとして提案されている。
スタックドオートエンコーダーは、オートエンコーダーで圧縮したベクトルをさらに同様の方法で圧縮するというようなことを繰り返し、データを圧縮する手法で。圧
縮する層と展開する層をつなげて、最後に全体を学習することで効果的に多層のニューラルネットワークを学習することができるものとなる。ヒントンの論文では2000次元を1000次元に、1000次元を500次元に、500次元を30次元に圧縮している。


Reducing the Dimensionality of
Data with Neural Networksでの特徴量抽出例
上記の文献では制限付きボルツマンマシンのコントラスティブ・ダイバージェンス法という学習を用いている。
オートエンコーダーの活用としては特徴量を出すだけであれば、上記のAやBのケースではOpenCV等を用いてデータを正規化する手法でも十分実用的ではないかと思う。正解の画像を学習し異常検知で用いるものが実用化されているとのこと。
pythonを使った実装はkerasのHPで紹介されており、ClojureではJavaの深層学習ライブラリであるDeepLearning4Jを使うことができる。これらの詳細は別の機会に紹介したい。
*1) Mathworks オートエンコーダーとは


AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.

