
サマリー
機械学習をハードウェア的に実装する場合、多くは専用のハードウェア利用することとなる。それらの手段としては以下のようなものがある。
- GPUを使用する:グラフィックスカード(GPU)を利用することで、一般的な中央処理装置(CPU)よりも高速で大量のデータを処理することができるようになる。実際に多くの機械学習のタスクにおいて、GPUを使用することで処理速度を向上させている。
- FPGAを使用する:フィールドプログラマブルゲートアレイ(FPGA)は、プログラム可能な回路を含むカスタムロジックを備えたチップとなる。FPGAは、専用の回路を実装して、機械学習タスクに最適な性能を発揮することができる。FPGAでの機械学習のアプローチに関しては”ソフトウェア技術者のため のFPGA入門 機械学習編“も参照のこと。
- ASICを使用する:アプリケーション固有集積回路(ASIC)は、専用のチップであり、特定のタスクに最適化されたものが提供されている。機械学習に特化したASICは、高速なデータ処理を行うことができ、最新の深層学習モデルを実行することができる。
- TPUを使用する:テンソル処理ユニット(TPU)は、Googleが開発した専用のハードウェアであり、深層学習アルゴリズムに特化している。TPUは、高速なデータ処理を行い、大量のデータを高速かつ効率的に処理することができる。
これらの方法をもちいることで、機械学習アルゴリズムの実装を高速化し、ハードウェアリソースを効率的に使用することができるが、専用のプログラムを実装する必要があるため、開発コストが高くなる可能性がある。ここでは、この機械学習でのハードウェア的なアプローチに関して「Thinking Machines 機械学習とそのハードウェア実装」をベースに述べる。

AI技術へのハードウェアアプローチに関しては”半導体の設計プロセスへのAIの適用およびAIアプリケーション用半導体チップについて“も参照のこと。
ハードウェア実装の現実 – マイクロプロセッサ性能の停滞
従来の計算機アーキテクチャ、特にマイクロプロセッサアーキテクチャはムーアの法則(半導体技術の向上に伴い、1.8年毎にダイに実装されるトランジスタ数が2倍になるとした予想)を前提に単位面積辺実装できる論理回路の規模がスケールでき、結果としてトランジスタのゲート長が短くなるので動作時のクロックサイクル時間を短縮できて、要求される実行性能(実行に要する時間の短さ)もそれとともにスケールができていた。つまり何年後にこれだけダイ面積が利用でき、配線遅延もこれだけだから動作クロック周波数もこれだけになるので、これだけの機能を実装したプロセッサはこれだけの性能になるというのが大体見積もれていた。
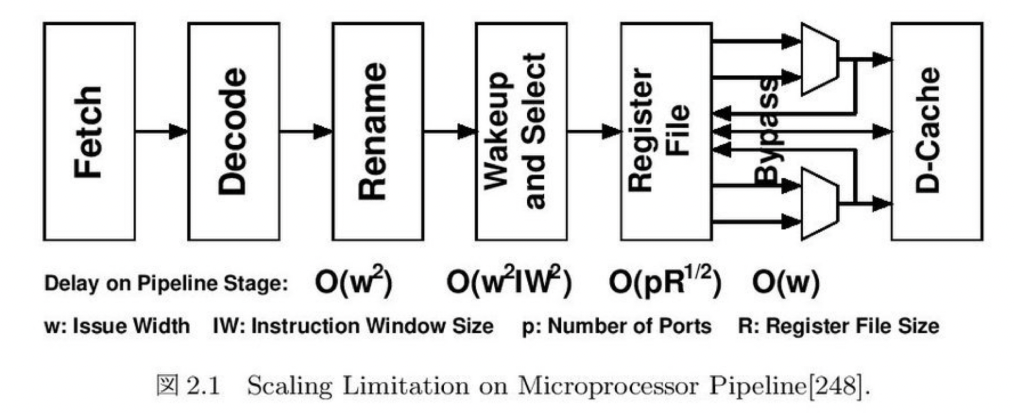
しかし1990年台中盤以降で半導体プロセスの縮小率に対してゲート長の縮小が難しくクロック周波数が向上しづらい事や、エネルギー効率の悪化、そして設計の複雑化などからそれらの性能が伸び悩むこととなった。回路の複雑さはその回路上の最長経路の遅延時間(critical-path delay)から測ることができる。複数の回路で構成されたパイプライン上最も長い遅延時間を持つ回路が同期式回路のクロック時間つまりクロック周波数を決めていた。下図にパイプライン型プロセッサの各パイプラインステージにおける最長経路時間をオーダー換算で示す。


複数命令を同時発行可能なスーパースカラープロセッサは、コンパイラが生成した命令列を動的に解析し、プログラムを破壊しない範囲で実行可能な複数の命令を同時に実行していく。
第1章 イントロダクション
1.1 機械学習の認知
1.2 機械学習と応用範囲
1.2.1 機械学習の定義
1.2.2 機械学習の応用範囲
1.3 学習と性能
1.3.1 学習前の事前準備
1.3.2 学習とその方法
1.3.3 性能評価と検証
1.4 機械学習の位置づけ
1.4.1 第4次産業革命
1.4.2 トランザクション処理
第2章 従来のアーキテクチャ
2.1 ハードウェア実装の現実
2.1.1 幕色プロセッサ性能の停滞
2.1.2 GPUの計算機システムへの応用
2.1.3 FPGAの計算機システムへの応用
2.2 特定用途向け集積回路(ASIC)
2.2.1 アプリケーションの特性:局所生徒依存性
2.2.2 半導体設計時の制約
2.3 ハードウェア実装のまとめ
2.3.1 計算機産業のこれまで
2.3.2 機械学習のハードウェア化
2.3.3 ハードウェア化の分類
2.3.4 機械学習ハードウェア化の経緯
第3章 機械学習と実装方法
3.1 ニューロモルフィックコンピューティング
3.1.1 活動電位タイミング依存可塑性と学習
3.1.2 ニューロもルフィックコンピューティングハードウェア
3.1.3 AER:Advances-Event Representation
3.2 ニューラルネットワーク
3.2.1 ニューラルネットワークモデル
3.2.2 ニューラルネットワーク・ハードウェア
第4章 機械学習ハードウェア
4.1 実装プラットフォーム
4.1.1 メニーShellプロセッサ(ManyーCore Processors)
4.1.2 Digital Signal Processors
4.1.3 GPUs:Graphics Processing Unit
4.1.4 FPGAs :Field-Programmable Gate Arrays
4.2 性能指標
4.3 性能向上方法
4.3.1 モデル最適化
4.3.2 モデル圧縮
4.3.3 パラメータ圧縮
4.3.4 データの符号化
4.3.5 データフローの最適化
4.3.6 ゼロスキッピング演算
第5章 機械学習モデルの開発
5.1 ネットワークモデルの開発プロセス
5.1.1 開発サイクル
5.1.2 ソフトウェアスタック
5.2 コードの最適化
5.2.1 ベクトル化とSMD化
5.2.2 メモリアクセス最適化
5.3 Python言語と仮想機械(Virtual Machine)
5.3.1 Python言語と最適化
5.3.2 仮想機械(Virtual Machine)
第6章 ハードウェア実装の事例
6.1 ニューロモルフィックコンピューティング
6.1.1 アナログ回路実装(Analog Logic Circuit)
6.1.2 デジタル回路実装(Digital Logic Circuit)
6.2 ディープニューラルネットワーク
6.2.1 アナログ回路実装
6.2.2 DSP実装
6.2.3 FPGA実装
6.2.4 ASIC実装
6.3 その他の事例
6.4 事例のまとめ
6.4.1 ニューロもルフィックコンピューティングの事例
6.4.2 ディープニューラルネットワークの事例
6.4.2 ニューロもルフィックコンピューティングとニューラルネットワークの比較
第7章 ハードウェア実装の要点
7.1 市場規模予測
7.2 設計とコストのトレードオフ
7.3 ハードウェア実装の戦略
7.3.1 戦略立案の要件
7.3.2 基本戦略
7.3.3 外部要因
7.4 まとめ:ハードウェア設計に要求されること
第8章 結論
付録A 深層学習の基本
A.1 数式モデル
A.1.1 順伝搬型ニューラルネットワーク
A.1.2 学習と誤差伝搬法:パラメータの更新
A.1.3 活性化関数
A.2 機械学習ハードウェアモデル
A.2.1 パラメータ空間と順伝搬・逆伝搬演算の関係
A.2.2 学習の最適化
A.2.3 パラメータの数値精度
A.3 深層学習と行列演算
A.3.1 深層学習の行列表現とデータサイズ
A.3.2 行列演算のシーケンス
A.3.3 パラメータの初期化
A.4 ネットワークモデル開発時の課題
A.4.1 バイアス・バリアンス問題
付録B Advanced Network Models
B.1 CNN Variants
B.1.1 Deep Convolutional Generative Adversarial Networks
B.2 RNN Variants
B.2.1 Highway Networks
B.3 Autoencoder Variants
B.3.1 Stacked Denoising Autoencoders
B.3.2 Ladder Networkd
B.4 Residual Networks
付録C 国別の研究開発動向
C1中国
C2米国
C 2.1 SyNAPSE program
C 2.2 UPSIDE program
C 2.3 MIGrONS program
C3欧州
C4日本
C 4.1 総務省
C 4.2 文部科学省
C 4.3 経済産業省
C 4.4 内閣府
C 4.5 全能アーキテクチャイニシアティブ
付録D 社会に与える影響
D.1 産業
D.1.1 これまでの産業
D.1.2 これからの産業
D.1.3 オープンソース・ソフトウェアとハードウェア
D.1.4 ソーシャル・ビジネスとシェアリング・エコノミー
D.2 機械学習と人の共存
D.2.1 機械学習が代変可能な業種
D.2.2 業界の整理統合
D.2.3 世界が単純になる日
D.3 社会と個人
D.3.1 プログラミングの浸透
D.3.2 価値観の変化
D.3.4 犯罪
D.4 国家
D4.1 警察と検察
D.4.2 行政・立法・司法
D.4.3 軍事


AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.


コメント
[…] Thinking Machines 機械学習とそのハードウェア実装 […]
[…] リアルタイム処理が必要な場合、”Thinking Machines 機械学習とそのハードウェア実装“にも述べているように高速なモデルやハードウェアアクセラレーション(GPU、TPUなど)を活用 […]
[…] 、モデルの軽量化などを検討する。また、GPUを活用することも処理速度を向上させる方法の一つとなる。詳細は”Thinking Machines 機械学習とそのハードウェア実装“等も参照のこと。 […]