
サマリー
Clojure for Data Scienceより。今回はClojureを用いたネットワーク解析として、 幅優先/深さ優先探索・最短経路探索・最小スパニング木・サブグラフと連結成分について述べる。

イントロダクション
グラフを視覚的な意味ではなく、数学的な意味で扱った場合について考える。グラフとは、単に辺で結ばれた頂点の集合であり、この抽象化の単純さは、グラフがどこにでもあることを意味する。グラフは、ウェブのハイパーリンク構造、インターネットの物理構造、道路、通信、社会的ネットワークなど、さまざまな構造の有効なモデルとなる。
このように、ネットワーク解析は決して新しいものではないが、特にソーシャルネットワーク解析の台頭により、一般的になってきた。Google、Facebook、Twitter、LinkedInなどは、大規模なグラフ処理により、ユーザーのデータをマイニングしている。ウェブサイトの収益化においてターゲット広告が非常に重要であることから、インターネットユーザーの興味を効果的に推論する企業には大きな金銭的報酬があることになる。
これらのグラフデータの為のアルゴリズムに対して、以前”グラフデータの基本的アルゴリズム(DFS、BFS、ニ部グラフ判定、最短路問題、最小全域木)“や”高度なグラフアルゴリズム(強連結成分分解、DAG、2-SAT、LCA)“等でC++を使った実装について述べた。今回はClojure/loomを使った活用について述べる。
今回は具体的な例として、一般に公開されているTwitterのデータを使って、ネットワーク分析の原理について述べる。三角形カウントなどのパターンマッチング技術を適用してグラフ内の構造を探し、ラベル伝播やPageRankなどのグラフ全体処理アルゴリズムを適用してグラフのネットワーク構造を探し出す。最終的には、これらの技術を利用して、Twitterコミュニティの最も影響力のあるメンバーから、そのコミュニティの関心事を特定する。
Twitterのデータを用いた解析
まず具体例としてTwitterのソーシャルネットワークのフォロワーデータを利用する。このデータは、Stanford Large Network Dataset Collection の一部として提供されている。利用するデータは前述のページの中で”Socila networks”、”ego-Twitter”と辿り、”twitter.tar.gz”、”twitter_combined.txt.gz”の2つを利用する。
Clojureの環境立ち上げは、”Clojureを始めよう(1)“等を参照のこと。またREPL環境としてはsublimetext4のClojure sublimedプラグインを利用した詳細は”SublimeText4とVS code、LightTableでのClojureの開発環境立ち上げ“参照のこと。
まずプロジェクトファイルを”lein new network-analysis-test(任意のプロジェクト名)”で作成し、プロジェクトフォルダ内のproject.cljファイルにライブラリを以下のように追加する。
(defproject network-analysys-test "0.1.0-SNAPSHOT"
:description "FIXME: write description"
:url "http://example.com/FIXME"
:license {:name "EPL-2.0 OR GPL-2.0-or-later WITH Classpath-exception-2.0"
:url "https://www.eclipse.org/legal/epl-2.0/"}
:dependencies [[org.clojure/clojure "1.11.1"]
[aysylu/loom "1.0.2"]
[incanter "1.9.3"]
[t6/from-scala "0.3.0"]
[glittering "0.1.2"]
[gorillalabs/sparkling "3.2.1"]
[org.apache.spark/spark-core_2.11 "2.4.8"]
[org.apache.spark/spark-graphx_2.11 "2.4.8"]
[org.clojure/data.csv "1.0.1"]]
:repl-options {:init-ns network-analysys-test.core})追加されるライブラリの詳細は後述する。まずはダウンロードしてきたデータをresourceフォルダー以下に格納し、loomを使った簡単なグラフデータ化とビジュアライゼーションを行う。
(ns network-analysys-test.core
(:require [clojure.data.csv :as csv]
[clojure.java.io :as io]
[clojure.string :as str]
[loom
[graph :as loom]
[io :as lio]
[alg-generic :as gen]
[alg :as alg]
[gen :as generate]
[attr :as attr]
[label :as label]]
))
(defn to-long [s]
(Long/parseLong s))
(defn line->edge [line]
(->> (str/split line #" ")
(mapv to-long)))
(defn load-edges [file]
(->> (io/resource file)
(io/reader)
(line-seq)
(map line->edge)))
上記のコードでtwitterデータを読み込むと、以下のように、2つのノードのペアのデータとなっていることが確認される。
(load-edges "twitter/98801140.edges")
(["100873813" "3829151"]
["35432131" "3829151"]
["100742942" "35432131"]
["35432131" "27475761"]
["27475761" "35432131"])これをloomを用いてグラフデータにし、更に可視化する。
(->> (load-edges "twitter/98801140.edges")
(apply loom/graph)
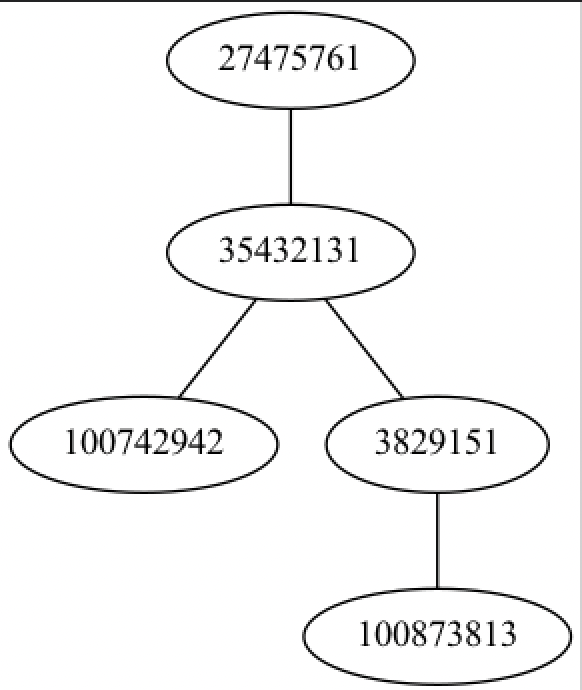
(lio/view))) loom/viewはgraphvizが必要となる為、事前にインストール(macの場合は”brew install graphviz”)する必要がある。結果は以下のようなグラフとなる。


前述のデータでは、エッジが5つあったが、上図では4つしかエッジがないことから、このデータは有向グラフである可能伊勢がある。その場合はloom/graphではなく、loom/diagraphという関数を使う
(defn testa5 [n]
(->> (testa3 n)
(apply loom/digraph)
(lio/view)))
(testa5 "data/twitter/98801140.edges")結果を以下に示す。エッジが5本の有向グラフであることが確認できる。


このデータはtwitterのソーシャルグラフなのでアカウント382951には、アカウント35432131と100873813という2つのフォロワーがいて、アカウント27475761と35432131の間には、2本のエッジが存在して”サイクル”を形成していることが分かる。
Loomを用いたグラフの探索
グラフモデルで表現できる現象が多様に存在する為、グラフ探索アルゴリズムは非常に有用なものとなる。例えば”「複雑ネットワークとは何か 複雑な関係性を読み解く新しいアプローチ」 読書メモ“でも述べたケーニヒスベルク橋でのオイラー路(グラフの全ての辺を通る路)は、開始と終了を除くすべてのノードが複数の接続エッジを持つ為、奇数次の頂点の数を数えて0個か2個であれば良いこととなる。これは以下のように実装され、前述のグラフを代入すると”false”の結果となる。
(defn euler-tour? [graph]
(let [degree (partial loom/out-degree graph)]
(->> (loom/nodes graph)
(filter (comp odd? degree))
(count)
(contains? #{0 2}))))
(euler-tour?
(->> (load-edges "twitter/98801140.edges")
(apply loom/graph))) ;; false
幅優先探索と深さ優先探索
グラフ探索においてより一般的な欲求は、ある制約条件でのグラフ内のノードを見つけることである。この課題に対しては、いくつかの方法がある。Twitterのフォローグラフのような重みのないグラフの場合、最も一般的なものは幅優先探索と深さ優先探索となる。
幅優先探索は、ある特定の頂点から始めて、その近傍にある頂点を探索する。その頂点が見つからなければ、その近傍を順番に探索し、頂点が見つかるか、グラフ全体を走査し終えるまで探索する。
次の図は、頂点が探索される順序を示したもので、上から順に左から右へと階層的に探索される。


Loomではloom.algという名前空間に様々な探索アルゴリズムが含まれている。これまでと同じTwitterのフォロワーグラフに対して、幅優先探索を実行してみる。
まず幅優先探索について。幅優先探索はbf-traverse関数として提供される。この関数は
幅優先探索で訪れたノードが順番に示され、幅優先探索がどのようにグラフを横断するかを見ることができる。
(let [graph (->> (load-edges "twitter/98801140.edges")
(apply loom/digraph))]
(alg/bf-traverse graph 100742942))
;;(100742942 35432131 27475761 3829151)上述の結果は、bf-traverse 関数を使用して、ノード 100742942 から始まるグラフの走査を実行している。応答にはノード100873813 が含まれていない。これは、辺の方向だけをたどってこの頂点までグラフを横断する方法はないことを示している。頂点100742942に到達する唯一の方法は、そこから始めるものとなる。


また、35432131は27475761と3829151の両方に接続しているにもかかわらず、一度だけしかリストされない。Loomの幅優先探索の実装は、メモリ内に訪問した頂点のセットを保持するので、一度訪れた頂点は、再び訪れない。
幅優先探索の代替手法として、深さ優先探索がある。このアルゴリズムは、ツリーの底まですぐに進み、次の図に示す順序でノードを訪問するものとなる。


loomでの実装は以下のようになる。
(let [graph (->> (load-edges "twitter/98801140.edges")
(apply loom/digraph))]
(alg/pre-traverse graph 100742942))
;; (100742942 35432131 3829151 27475761)幅優先探索とはみつけてくるノードの順番が異なる結果となる。深さ優先探索の利点は、各階層ですべてのノードを保存する必要がないため、広さ優先探索よりも必要なメモリ量がはるかに少ないこととなる。このため、大規模なグラフの場合、メモリ消費量が少なくて済む可能性がある。
しかし、状況によっては、深さ優先探索と幅優先探索のどちらかの方が便利な場合もある。例えば、家系図を見て生きている親族を探す場合、その人は木の一番下の方にいると考えられるので、深さ優先探索の方が早くたどり着けるかもしれない。もし、古い先祖を探しているのであれば、深さ優先の検索では、より新しい親族を数多くチェックすることになり、目標に到達するまでにかなりの時間がかかることとなる。
最短経路探索
先述したアルゴリズムは、グラフを頂点ごとに走査し、グラフ内の全ノードの順列を返すものであった。これらは、グラフ構造をナビゲートする2つの主要な方法を説明するのに便利であるが、より一般的なタスクは、ある頂点から別の頂点への最短経路を見つけることにある。つまり、その間にあるノードの並びだけに興味を持つことになる。
前述のグラフのように重みのないグラフの場合は、通常、距離は「ホップ」の数で数えることになる。最短経路は、ホップ数が最も少ない経路となる。一般に、この場合、幅優先探索はより効率的なアルゴリズムとなる。
Loomではbf-path関数として、幅優先の最短経路を実装している。以下にそれらの実装を示す。まず以下のようなデータを対象とする。
(->> (load-edges "twitter/396721965.edges")
(apply loom/digraph)
(lio/view))

上下のノード75914648と32122637の間の最短経路を特定できるかどうか見てみ.る。アルゴリズムが返す可能性のあるパスはたくさんあるが、ここでは点28719244と点163629705を通るパスを特定したい。これは最もホップ数の少ないパスとなる。
(let [graph (->> (load-edges "twitter/396721965.edges")
(apply loom/digraph))]
(alg/bf-path graph 75914648 32122637))
;;(75914648 28719244 163629705 32122637)実際にそれらのパスが最短経路として抽出されていることが確認できる。
また、Loomにはbf-path-biという双方向の幅優先最短パスアルゴリズムが実装されている。これは、送信元と送信先の両方から並列に検索を行い、ある種のグラフでは最短経路をより速く見つけられる可能性があるものとなる。
次にグラフに重みがある場合について述べる、この最短ホップは2つのノード間の最短経路に対応しないかもしれない。なぜなら、この経路は大きな重みを持つ可能性があるからである。それらを求めるアルゴリズムとして、ダイクストラアルゴリズムがある。これは、2つのノード間の最短コストの経路を見つける方法となり。この経路はホップ数が多くても、通過するエッジの重みの総和は最小になるものとなる。
(let [graph (->> (load-edges "twitter/396721965.edges")
(apply loom/weighted-digraph))]
(-> (loom/add-edges graph [28719244 163629705 100])
(alg/dijkstra-path 75914648 32122637)))
;;(75914648 28719244 31477674 163629705 32122637)このコードでは、グラフを重み付きグラフとして読み込み、ノード28719244と163629705間のエッジの重みを100に更新している。これは、最短経路に非常に高いコストを割り当てる効果があるため、代替経路を見つけることができる。
ダイクストラのアルゴリズムは、特に経路探索に有効となる。例えば、グラフが道路網をモデルにしている場合、最短距離の経路よりも、主要な道路を通る経路が最適となる場合がある。また、時間帯や道路の交通量によって、特定の経路にかかるコストが変化することもある。このような場合、ダイクストラのアルゴリズムは、一日のどの時間帯でも最適なルートを決定することができる。
また、A* (A-star と発音する) と呼ばれるアルゴリズムは、ヒューリスティックな関数を許容することで、ダイクストラのアルゴリズムを最適化するものとなる。Loomではalg/ astar-pathとして実装されている。ヒューリスティック関数は、目的地までの予想コストを返す。真のコストを過大評価しない限り、どのような関数でもヒューリスティックとして使用することができる。このヒューリスティックを使うことで、A* アルゴリズムはグラフの網羅的な探索を避けることができ、したがって
より高速に処理することができる。
最小スパニング木
次に、グラフ内のすべてのノードを結ぶ経路を発見するアルゴリズムである、最小スパニング木(minimum spanning tree)について述べる。最小スパニング木は、完全グラフ探索アルゴリズムと、先述した最短経路アルゴリズムのハイブリッドと考えることができる。
最小スパニング木は重みつきグラフに特に有効となる。重みが2つの頂点を結ぶコストを表している場合、最小スパニング木はグラフ全体を結ぶコストの最小値を求める。これは、ネットワーク設計のような問題で使われる。例えば、ノードがオフィスを表し、エッジの重みがオフィス間の電話線のコストを表すとすると、最小スパニング木は、すべてのオフィスを結ぶ電話線の集合を最小の総コストで提供することになる。
Loomの最小スパニング木の実装はPrimのアルゴリズムを利用しており、prim-mst関数として提供されている。
(let [graph (->> (load-edges "twitter/396721965.edges")
(apply loom/weighted-graph))]
(-> (alg/prim-mst graph)
(lio/view)))このコードは以下のような結果を示す。


これに対して、頂点28719244と163629705の間の辺を100に更新すると、最小スパニングツリーに与える違いを観察することができる。
(let [graph (->> (load-edges "twitter/396721965.edges")
(apply loom/weighted-graph))]
(-> (loom/add-edges graph [28719244 163629705 100])
(alg/prim-mst)
(lio/view)))

ツリーは、最もコストの高いエッジを迂回するように再構成されている。
サブグラフと連結成分
最小スパニング木は,すべてのノードが少なくとも1本のパスで他のノードに接続されている連結グラフに対してのみ指定できる。グラフが連結されていない場合は、明らかに最小スパニング木は作れない(代わりに最小スパニング林を作ることはできる)。


グラフが、内部的にはつながっているが、互いにつながっていない部分グラフの集合を含んでいる場合、その部分グラフは連結成分と呼ばれる。さらに複雑なネットワークを読み込むと、連結成分を観察することができる。
(->> (load-edges "twitter/15053535.edges")
(apply loom/graph)
(lio/view))上記のコードは以下のような結果を出力する。


グラフには、3つの連結成分があることが簡単にわかる。 Loomはconnected-components関数でこれらを計算してくれる。
(->> (load-edges "twitter/15053535.edges")
(apply loom/graph)
(alg/connected-components))
;; [[30705196 58166411]
[25521487 34173635 14230524 52831025 30973 55137311 50201146
19039286 20978103 19562228 46186400 14838506 14596164 14927205]
[270535212 334927007]]
有向グラフは、すべてのノードから他のすべてのノードへのパスが存在する場合、強連結となる。有向グラフが弱連結であるのは、すべての辺を無向であるとみなして、すべてのノードから他のすべてのノードへの経路が存在するときのみとなる。


同じグラフを有向グラフとして読み込み、強く結ばれた成分があるかどうかを見てみる。
(->> (load-edges "twitter/15053535.edges")
(apply loom/digraph)
(lio/view))結果は以下のようになる。


弱連結成分は先ほどと同じく3つとなる。強連結成分がいくつあるのか、グラフを見ただけではなかなか判断がつかず視覚的に判断するのは難しい。Kosarajuのアルゴリズムは、グラフ内の強連結成分の数を計算するもので、Loomではalg/scc関数として実装されている。
(->> (load-edges "twitter/15053535.edges")
(apply loom/digraph)
(alg/scc)
(count))
;; 13Kosarajuのアルゴリズムは、すべてのエッジを逆にした転置グラフが、入力グラフと全く同じ数の連結成分を持つという興味深い性質を利用している。応答には、すべての強連結成分(ノードが1つしかない縮退した場合も含む)がシーケンスベクトルとして含まれる。長さの降順でソートすると、最初の成分が最も大きくなる。
(->> (load-edges "twitter/15053535.edges")
(apply loom/digraph)
(alg/scc)
(sort-by count >)
(first))
;; [14927205 14596164 14838506]最大の強連結成分は3ノードに過ぎないことが確認される。
次回は引き続きClojureを用いたネットワーク解析として、Glitteringを使ったグラフ中の三角の計算について述べる。


AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.

