
トポロジカルデータアナリシスを用いたデータの位相幾何学的ハンドリング
今回は位相的データ解析(Topological Data Analysis)についてのべる。
ここで述べているものはトポロジカルデータアナリシスや、位相的データ解析(Topological Data Analysis)についてやTopological Data Analysis and Machine Learningを参照している。
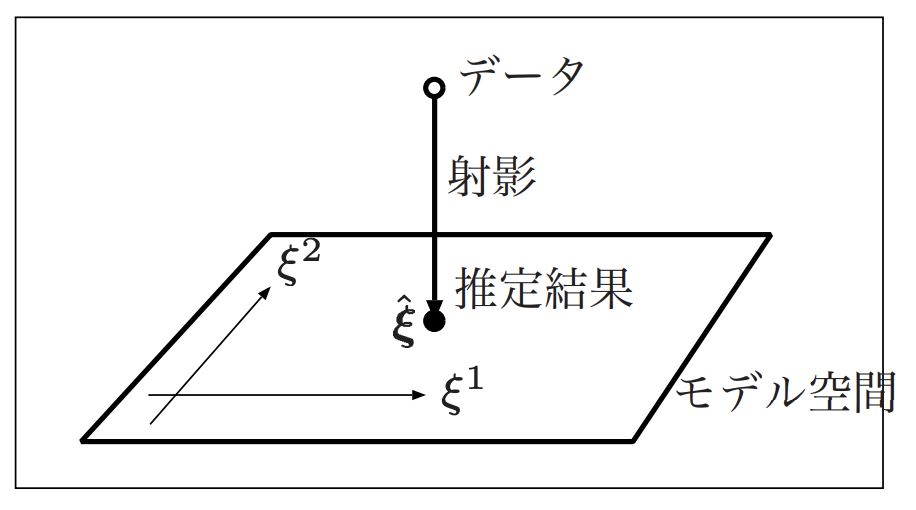
位相的データ解析とはデータの集合をトポロジーと呼ばれる「柔らかい」幾何を用いて解析する手法となる。幾何学を使ったデータ解析としては“情報幾何とは何か“でも述べている情報幾何学と呼ばれるものがあるが、こちらは機械学習を幾何的に説明しようというもので、機械学習とは,データが与えられた とき,そのデータにうまくあてはまるモデルを見つけると いう操作であり、モデルとは何らかのパラメータで表される空間であると考えると、データ点からモデルの空間への射影(関数)を見つけることが機械学習の本質となる。


情報幾何と機械学習より
このとき、モデル空間に「構造」を入れる必要があり、最も身近な空間としてはユークリッド空間があるが、既存のシステムや統計モデルの推定法はユークリッド空間では解釈できないものが多く、そのため、微分幾何と呼ばれる確率分布の空間(非ユークリッド)を想定して計算(最適化)を行うものとなる。そのため「硬い」幾何学を用いた分野とも呼ばれる。これら情報幾何に関しては別途詳細に述べる。
それに対してトポロジーはというと、よく使われているコーヒーカップとドーナッツの例で言うと。コーヒーカップが切れない粘土のようなものでできているとした時、それを少しずつ変形していくと、最終的にドーナッツに変形することができる。


Topological Data Analysis : 導入より
このとき、ドーナッツとコーヒーカップの共通tは、穴が一つ開いていることであり、これは非常にざっくりとした特徴だが、雑多なものを取り除いた本質的な抽象化であるとも言える。
これは別の例で言うと、以下の図は位相的に言うと同じであり


位相的データ解析(Topological Data Analysis)についてより
同様に以下の図も位相的には同じであると言える。

位相的データ解析(Topological Data Analysis)についてより
また以下のようなフォントが異なる文字も位相的には同じであると解釈することもできる。


位相的データ解析(Topological Data Analysis)についてより
このような位相幾何の抽象化を使ってデータ解析しようというのが位相的データ解析(Topological Data Analysis;TDA)となる。TDAは、そのような画像解析や”揺らぐタンパク質と老いる私-ミスフォールディング時代のデータサイエンス“で述べたようなタンパク質の解析、あるいはセンサーデータや自然言語処理にもその応用が考えられている。
ここでデータと図形を結びつけるアプローチについて述べる。以下左上のような5つのデータ点があるとする。


位相的データ解析(Topological Data Analysis)についてより
その点を少しずつ大きくしていくと、やがて重なり合い、左下の図形では穴が一つ(ドーナッツと位相的には同じ図形)になり、最終的には一つの形(穴のない円や三角、四角の図形とと位相的には同じ形)となる。
これを実際に実現するための方法として抽象単体複体がある。単体的複体での近似は脈体定理(点の周りに描く領域を凸集合に(球は凸集合)し、K+1個の球が重なっているときにK単体が要素になる(チェック複体とアルファ複体)ような抽象単体複体は、もとの見立てた図と定性的な性質が同じである)により、元のデータの集合による図形を近似できることが証明されている。大雑把な流れとしては、点の周りにある領域を考え、つながり方から抽象単体複体、およびその幾何学的実現(図形を構成する。これは、点と線や三角形といった図形の組み合わせとなっており、コンピュータで計算することが比較的容易なのものとなる。つまり、見立てた図形を何らかのルールによって三角形的な図形で分割して近似する、ということを大雑把にやっている。何らかのルールの部分は幾つか種類があるが、以下で代表的な3つの方法を紹介する。
- チェック複体
最も単純な構成で以下の手順となる。
-
- 点の周りにある半径の球を描く
- 球が接していたら「つながっている」とみなし、抽象単体複体(チェック複体)を構成する。抽象単体複体を構成するルール例としては、2つの球が重なる場合は、2つの点でラベルされる1単体が抽象単体複体の要素とするものや、3つの球が重なる場合は3つの点でラベルされる2単体が抽象単体複体の要素となる。


トポロジカルデータアナリシス:データと図形を結びつけるより
- ヴィートリス・リップス複体
チェック複体は、最も素直な構成の仕方だが、計算量が多いという欠点がある。それは、何個の球が重なっているかをすべて洗い出す必要があるからで、考える点の数が増えると、考慮する場合の数も爆発的に増えてしまう。そこで、チェック複体の簡易版として、以下のヴィートリス・リップス複体というものも考えられている。手順は以下のようになる。
-
- 点の周りにある半径の球を描く
- 球が接していたら「つながっている」とみなし、抽象単体複体(ヴィートリス・リップス複体)を構成する。チェック複体との違いは、K+1個の球の「任意の」2点が重なっていれば、K単体が抽象単体複体の要素であり、チェック複体は、K+1個の球すべてが重なっている領域がないとダメだとみなす

トポロジカルデータアナリシス:データと図形を結びつけるより
- アルファ複体
構成法が複雑だが、計算量がチェック複体ほど多くならなそうな単体的複体。手順は以下となる。
-
- 点と点の間を垂直2等分線で分割する。ただし線を引くのは他の垂直2等分線とぶつからない部分だけ
- 各点がボロノイ領域というもので分割される
- さらに点の周りにある半径の球を描き、ボロノイ領域と球の共通部分を考える
- 上で考えた共通部分どうしが接していたら「つながっている」とみなし、抽象単体複体(アルファ複体)を構成する

トポロジカルデータアナリシス:データと図形を結びつけるより
このTDAの活用として、ノイズのあるデータの解析がある。例として以下のようなデータ(中)とそのデータが表す真のモデル(左)を考える。

トポロジカルデータアナリシス:ノイズのあるデータへ応用するより
上図の場合は大きいリングと小さいリングがあるものが真のモデルだとする。実際のデータはこのモデル上にノイズを持って分布している。これに対して球の半径が小さいとうまくつながらず、球の半径が大きいとつぶれて小さい構造が見えなくなる。
これに対するTDAの考え方の一つにパーシステントホモロジーというアプローチがある。これは以下のように半径を変えていったときの図形の移り変わりを見るというものになる。

トポロジカルデータアナリシス:ノイズのあるデータへ応用するより
具体的な手順としては、データ点の周りに球を考え、その半径を一斉に、かつ連続的に大きくしていく。すると、最初は細かい構造だったものが、小さいリングの構造が見え始める、大きいリングと小さいリングが1個ずつある構造が見える、大きいリングのみの構造が見える、穴がなくなると移り変わる。
ここで、半径を大きくしていったときにすぐ構造が変わってしまうものをノイズ的なもの、構造が安定的(長い区間同じ構造を保っている)なものをデータの本質的な情報、といった見方をする。上の例だと、半径を大きくしていったときに、大きいリングと小さいリングが1個ずつある構造が比較的安定して存在していることが見えた場合、この構造が本質であったと判断することとなる。
構造の移り変わりを構造の「生成」と「消滅」という見方で可視化したものを、パーシステント図という。ここでいう構造とは、例えば一次元ホモロジー群の生成元のことを指すが、これはざっくり「何個かの穴をもったものを表現する量」のこととなる。
今、球の半径を一斉に、かつ連続的に大きくしていったとする。大きくしていく途中で、新しい構造がでてきた半径(Birth)と、その構造が消えた(つまり別の新しい構造が生まれた)半径(Death)を記録していく。それらをプロットすると、下の図のようになる。

トポロジカルデータアナリシス:ノイズのあるデータへ応用するより
すぐ生成されてすぐ消滅する量は、それぞれの半径の大きさの差が非常に小さくなる。そのため、Death – Birth(寿命)が0に近い、つまり対角線上に近くなる。一方で、長い区間で安定的な構造は、Death – Birthが大きくなるため、対角線上から離れたところに位置する。先ほどの例だと、大きいリングと小さいリングが1個ずつある構造が対角線上から離れた場所にプロットされた場合、この構造が本質であったと判断するものとなる。
ここまで述べたTDAのライブラリはpythonではscikit-tdaというscikit-learn風のpythonモジュールを用いることができる。
導入は以下のようにして行う
pip install cython
pip install ripserパーシステント図を扱うコードとしては以下のようになる。
import numpy as np
from ripser import ripser
from persim import plot_diagrams
data = np.random.random((100,2))
diagrams = ripser(data)['dgms']
plot_diagrams(diagrams, show=True)Rの場合はTDAというライブラリを使うことができる。例えば以下のようなクラスタがあったときにこれを位相的に見るということをTDAで行う。


位相的データ解析(Topological Data Analysis)についてより
install.packages("TDA")
library(MASS)
library(TDA)
#データの生成
mu1 <- c(0, 0)
Sigma1 <- matrix(c(1, 0.3, 0.3, 1), 2, 2)
x1 <- mvrnorm(30, mu1, Sigma1)
mu2 <- c(8, 0)
Sigma2 <- matrix(c(1, -0.2, -0.2, 1), 2, 2)
x2 <- mvrnorm(30, mu2, Sigma2)
mu3 <- c(4, 6)
Sigma3 <- matrix(c(1, 0, 0, 1), 2, 2)
x3 <- mvrnorm(30, mu3, Sigma3)
x <- rbind(x1,x2,x3)
#TDAによる計算
Diag <- ripsDiag(X = x, maxdimension = 0, maxscale = 5, library = "Dionysus")
#可視化(バーコードプロット)
D <- Diag[["diagram"]]
n <- nrow(D)
plot(c(min(D[,2]), max(D[,3])-1.5), c(1,n + 1), type="n", xlab = "radius", ylab ="", xlim=c(min(D[,2]), max(D[,3])-1.5), ylim=c(1, n + 1), yaxt ='n')
segments(D[,2], 1:n, sort(D[,3]), 1:n, lwd=2)

位相的データ解析(Topological Data Analysis)についてより
上図はバーコードプロットとよばれているもので、半径3.5では一つの図形、半径2.0〜3.0までで3つの図形となり、位相の変化からみると3つの図形(クラスタ)があることが予測される。
もう一つの例として、穴の数を数えるということもできる。


位相的データ解析(Topological Data Analysis)についてより
例えば「A」「L」「B」という文字を識別する時に、それぞれ穴が1個, 0個, 2個という情報を自動的に取得できるため、文字の識別するための特徴量として使え、また、点の周りに円を描いて各点を大きくすることで、薄れた文字の認識をすることもできる。
library(TDA)
#データの生成
image_A <- cbind(x= c(0,1,2,3,4,5,6,7,8,9,10,3.5,5,6.5) * 0.6 + 2,
y =c(0,3,6,9,12,15,12,9,6,3,0,6,6,6)*0.55 + 1.25)
image_L <- cbind(x = c(0,0,0,0,0,0,0,0,0,1,0.25,0.5,0.75,1.25,1.5) * 4 + 2 ,
y = c(0,1,2,3,4,5,6,7,8,0,0,0,0,0,0) + 1.25)
image_B <- cbind(x = c(0,0,0,0,0,0,0,0,0,1,1,1,1.25,1.25,1.5,1.5,1.5,0.25,0.25,0.25,0.5,0.5,0.5,0.75,0.75,0.75,1.25,1.25) * 4 +2,
y = c(0,1,2,3,4,5,6,7,8,0,4,8,5.3,6.6,1,2,3,0,4,8,0,4,8,0,4,8,3.5,0.5) + 1.25)
#TDAによる計算
Diag_A <- ripsDiag(X = image_A,maxdimension = 1,maxscale = 5)
Diag_L <- ripsDiag(X = image_L,maxdimension = 1,maxscale = 5)
Diag_B <- ripsDiag(X = image_B,maxdimension = 1,maxscale = 5)
#可視化(パーシステント図)
plot(Diag_A$diagram)
plot(Diag_L$diagram)
plot(Diag_B$diagram)以下が左から「A」「L」「B」について得られたパーシステント図となる。


位相的データ解析(Topological Data Analysis)について
この図は、各点の周りの円の半径の大きさを大きくしていった時に、穴が生まれた時(Birth)の半径の大きさと、穴がなくなった時(Death)の半径の大きさをプロットしたものとなる。穴の数は赤い三角で表現されている。ここからすぐにそれぞれの文字の穴の数が1個、0個、2個ということが分かる。


AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.


コメント