
サマリー
Kubernetes実践ガイドより。 前回はクラウドネイティブとサービス中心の開発について述べた。今回はクラウドネイティブアプリケーションにおける、コンテナやKubernatesの価値について述べる。

前回は、企業のクラウドネイティブへの歩みとともに、その中で期待されているコンテナオーケストレーションについて述べた。しかし、クラウドネイティブを実装する上での大きな課題は、クラウド技術に対する環境依存となる。例えば、特定のクラウドベンダーサービスを利用すると、そのサービスの機能やサービスレベルによって、アプリケーションのアーキテクチャ変更が強いられる。これでは、いくらクラウドを利用しても、ビジネス変化に迅速に対応できるとは限らない。
コンテナ技術が注目されている一つの理由は、こうしたベンダー依存からの解放となる。その技術的要素には、Linux Kernelの機能が活用されており、これまでのアプリケーション実行環境と大きく変わるものはない。しかし、コンテナ技術の標準化への対応によって、クラウドが特定のベンダーによって占有されることなく利用できることに、クラウドネイティブへの第一歩がある。
ここでは、こうしたコンテナを支える技術について述べるとともに、コンテナやKubernatesがどういった仕組みによって、ビジネス価値を提供しているのかについて述べる。
コンテナの概要
コンテナ以前の時代は、アプリケーションの展開というと、物理マシンに設定されたOS上に展開されることが一般的であった。しかし、近年ではアプリケーションそのものをコンテナとして展開することも、主要な選択肢の一つとなっている。コンテナとしてアプリケーションを展開するメリットとしては、実行環境に依存しないアプリーション運用ができることになる。これによって、OSによるアプリケーション独自のライブリ依存や、クラウド環境自体の運用環境から解放される。これは、JavaにおけるJVMの考え方と非常によく似ている。
Javaは、どのOS上であっても、プログラムさえ書ければどこでも同じように動かすことができるという考え方で、当時Sun Microsystem,.Incでは「Write once, Run anywhere」と言われていた。一方、コンテナはコンテナイメージさえ用意すれば、どこでも、どんな言語でも動かすことができるため、Javaのビジョンと対比して「Build once, Run anywhere」などと呼ばれる。
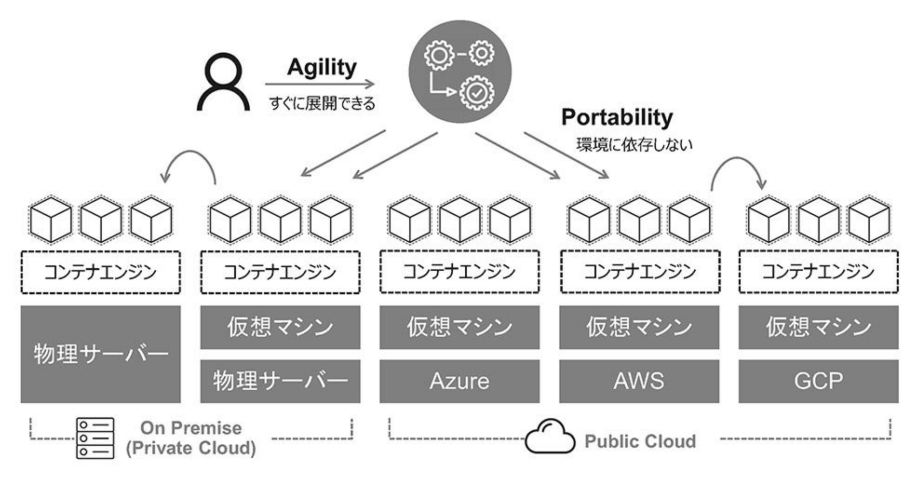
こうしたコンテナの持ち運びのしやすさのことを「可搬性(Portability)」と呼ぶ。クラウドネイティブアプリケーションは、このコンテナの持つ可搬性の高さによって支えられている。例えば、特定のクラウドやハードウェアに依存していたアプリケーションも、コンテナを利用することによって、場所の制限から解放される。こうした特徴の背景には、Linuxが築き上げてきた技術や、ベンダー技術を統合する標準化機構の働きが大きく関係している。
コンテナの提供価値
サーバーの仮想化技術がデファクトスタンダードとなった今、コンテナ技術は仮想化の延長にある次世代技術と捉えられることがある。その背景には、仮想化によるリソース集約や、コスト削減といった既存のビジネスへの投資判断が大きく絡んでいる。つまり、仮想化技術によって、多くのリソースは一つの物理的リソースに集約されたように、コンテナも複数のアプリケーションを単一のOS上で複数展開できる。こうした効率的なリソースの集約率を理由に、システム投資の計画が行われている場合がある。さらに、サーバー仮想化では、OSまでのレイヤでしか集約できなかったものが、コンテナではアプリケーションレイヤを集約できることによって、集約率がより高まるという理由で、次世代投資を進めている企業も少なくない。
これらは決して間違いではないが、コンテナのメリットはリソースの集約化のための次世代アプリ仮想化技術という側面だけではなく、あくまでコンテナは、アプリケーションを迅速に展開するといった背景からできた技術で、さらにコンテナ技術の標準化が整った結果、いまやどこでもアプリケーションが動かせるプラットフォームを実現しているということができる。コンテナの価値はまさに、クラウドネイティブアプリケーションのスピード(Agility)や可搬性(Portability)を実現するためのギジュつであるということができる。


クラウドネイティブアプリケーションを構築するためには、コンテナ技術やコンテナオーケストレーションを取り巻く背景を知った上で、利用することが望まれる。もし、背景を知らずに実装を初めてししまうと”クラウドネイティブとサービス中心の開発について“で述べたクラウドを阻害する要因のように、単なるアプリケーションのコンテナ化となってしまう。これは、クラウドネイティブアプリケーションを構築・運用するすべての利用者が注意しなければならないポイントになる。アプリケーションのコンテナ化が目的ではなく、コンテナの特性を利用して開発スピードを上げ、運用負荷を下げていく方法を常に検討し、日々改善していくことが重要になる。
コンテナの特性
ここでDockerについて述べる。Dockerとは、PaaSのクラウドプロバイダであるdotCloud Incが開発し、2013年に公開したオープンソースのコンテナ管理ソフトウェアとなる。当初は、アプリケーションとその動作に必要なライブラリだけをパッケージ化してイメージ化するだけの技術であったが、その後さらに、そのイメージをどのOSでも展開できる環境を実現し、アプリケーションデプロイの自動化を推進したものとなる。
コンテナと言えばDockerという印象が強いのも、このしくみを応用し、今もMailSEnderの環境で利用されているからとなる。Dockerが、コンテナ技術において優れていたのは、そのコンテナに必要な要素を「イメージ化(リソース管理の抽象化)」して、「デプロイの自動化(コードによるコンテナの実行)」できる仕組みを実装したことによる。ここで述べているイメージがコンテナイメージ(Docker Image)であり、コンテナを実行できる環境がコンテナエンジン(Docker Engine)となる。このコンテナイメージでは、コンテナレジストリからダウンロード(Pull)して展開される。


Dockerを利用することにより、コンテナイメージさえ展開すれば、どの環境でもアプリケーションプロセスを再現できる。こうした環境がアプリケーション開発者にとって、複雑な環境セットアップ作業を排除し、迅速なコード開発を支援できるというユーザー体験をもたらした。
現在、コンテナのイメージ化とコンテナ実行の仕様は、Open Container Initiative(OCI)によって標準化されている。またDocker以外のコンテナ技術も複数存在している。ここでは、これらの背景よりコンテナ技術がどのような価値を提供してきたかについて再確認する。
コンテナの特性
コンテナの特性としては以下のようなものがある。
- APIによる迅速なアプリケーション管理 : イメージ化と実行が標準化された仕様(API)で管理できるため、アプリケーションデプロイの自動化や継続的インテグレーションが実施できる。
- 可搬性の高さ: コンテナイメージさえあれば、クラウドローカル環境など場所を問わず実行できる。
- 軽量なコンテナイメージ : アプリケーションの実行に必要な最低限のライブラリしかイメージに含まないため、スピーディに展開できる。
- コンテナの再利用 : 一度作成したコンテナイメージは、異なる環境でも同様の実施結果を再現できる。また、それらを共有することも可能となる。
コンテナの特性をうまく活かすことによって、アプリケーション開発の効率化や工数削減といった効果が発揮できる。これは、Dockerだけではなくその他のコンテナ技術においても同様のことが言える。
コンテナの要素技術
仮想マシンを前提とすると、どうしても「コンテナ」や「コンテナイメージ」と言われても、仮想化 技術を使った小さなマシンといった概念から離れられなくなる。ひの概念のままだと、実際のイメージとは乖離してしまうため、ここではコンテナは「アプリケーションの実行形式」そのものだととせえる。つまり、プロセスそのものをパッケージング化したものにすぎない。例えば、コンテナを起動するというと、仮想OSを起動するイメージではなく、linuxのInitシステムからアプリケーションを立ち上げるようなものだと考える。systemctlによって実行プロセスを起動することと同様に、コンテナではdockerコマンドによってコンテナを立ち上げる。もちろん、systemdにおける起動オプションは「etc/systemd/<SERVER名>.service」に設定していたように、コンテナもDockerfileや、コマンドのオプションにて起動オプションを指定する。このように扱えると、1コンテナ1プロセスといった概念も納得がいく。
よくある事象としては、sshdデーモンプロセスをアプリケーションプロセスと同じコンテナの中に起動するといったような例となる。これは完全にコンテナを仮想マシンとして取り扱っており、アプリケーションをその中で管理するという考え方で利用される。通常の運用では、コンテナに対してSSHで接続することはない。
このようにアプリケーションが、あたかも別のホストに存在するように感じる仕掛けはコンテナの要素技術によるものとなる。コンテナの要素技術としては、Linux Kernelの仕組みを活用した実行プロセスの確立となる。Linux Kernelでは、主に以下の2つの実装を行うことによって、あたかもアプリケーションが独自のOS上で動いているような環境を作り出している。
- 実行プロセスをグループ化して、分離された空間の中だけで実行する(namespace)
- 実行プロセスに対してハードウェアリソースを制限する(cgroups)


また、ファイルシステムの技術を利用して、コンテナイメージとコンテナの軌道を管理している。ここでは、主要な昨日のみを取り上げているが、そのほかにもセキュリティ、ネットワークなど複数のKernel機能を駆使して、実行プロセスの隔離を実現している。
名前空間(namespace)
コンテナの内部で稼働する実行プロセスには、ホストのリソースをアプリケーション自身の専有リソースとして見せる必要がある。これにはKernelの名前空間(namespace)という機能を利用する。コンテナごとに一つのnamespaceが作成され、ユーザー空間を分離する。コンテナを起動しているホスト側から見ると、各namespaceはホストのシステムリソースを共有しているが、namespaceの内部では独立したホストのように見える。その結果、一つのホスト上で複数のコンテナがリソースを共有できる。以下の図では、ネットワークの名前空間(network namespace)の例となる。コンテナ内からは占有したネットワークデバイスに見えるが、ホスト側からは仮想的なネットワークが通信している。


ネットワークだけに限らず、namespaceはシステムリソースごとに分かれており、コンテナはnamespace内であれば、システムリソースを共有できる。
コントロールグループ(cgroups)
プロセスを起動するためには、システムの物理リソースを割り当てる必要がある。これにはKernelのコントロールグループ(Control Groups:cgroups)という機能を利用する。コントロールグループは、指定した実行プロセスに対して共有可能な物理リソースの割り当て、優先度設定、拒否、管理、モニタリングなどの細かい管理をファイルシステム形式で提供するインターフェースとなる。たとえば、特定のcgroupsに対してメモリを200MBに制限することで、コンテナはそれ以上のメモリを取り扱うことができなくなる。


cgroupsは、階層構造であり、子は親の属性の一部を継承する仕組みで、多数の異なる階層がシステム上に共有できる。これらの各階層は、単一または複数の「サブシステム」に接続される。ここでいうサブシステムが、CPUやメモリなどの物理リソースを指す。
ファイルシステム
仮想マシンの場合は、仮想マシンイメージからコピーし、ハイパーバイザーが起動できるフォーマットに変換した上で、仮想マシンを起動している。また、一度仮想マシンを起動すると、ファイルシステムだけに限らずその仮想マシンのリソースはすべて専有される。しかし、コンテナの場合は、イメージそのもものを共有する。共有と言っても、コンテナイメージ自体は読み込み専用(Read Only Layer)で作成されており、イメージ内のファイルシステムには直接書き込みは行わない。また、起動中に実行プロセスによって書き込まれたデータは、新しいレイヤ(Thin R/W Layer)のファイルに書き込まれる。この仕組みを「コピーオンライト(COW:Copy-On-Write)と呼ぶ。通常は共有プロセスのメモリ書き込みに対して利用される言葉だが、ファイルシステムへの応用として、ここでは利用される。コピーオンライトでは、特定のファイルシステムの状態(コンテナイメージ)を原本として、起動したあとのファイルへの変更は、新たに作成したオリジナルファイルにのみ反映することで書き込み要求に対応している。


このように、更新された差分データだけを別ファイルとして取り扱うことによって、コンテナイメージの共有化や再利用を実現している。コンテナを削除すると、書き込み可能なレイヤだけが削除されるため、起動後に設定した内容などもなくなる。したがって、起動後の内容を保存したい場合には、コンテナイメージとして再度更新してイメージ化するか、別途外部ファイルに書き出すといった仕組みを構築する必要がある。
コンテナランタイム
前述までが、Kernel実装の組み合わせであり、コンテナ実行エンジンは、これらのKernelの機能をAPIとして実装するライブラリとなる。
当初Dockerは、LXC(Linux Container)の機能を利用していたが、バージョン0.9よりlibcontainerと呼ばれる独自のライブラリを利用するようになった。さらにそれの規格化を行うため、Open Container Initiative(OCI)が発足されコンテナランタイムの規格が作られた。この企画はコンテナランタイムの標準仕様である「Runtime Specification」とコンテナイメージフォーマットの標準仕様「Format Specification」の2つとなり「OCI vx.x」と呼ばれるものとなる。
このOCIの仕様に従って、コンテナを生成・実行するためのコンテナランタイム(CLI)が「runC」となる。Dockerをはじめとするコンテナ実行エンジンは、このrunCを内部動作として呼び出すことによって、標準化されたコンテナ実行ほ実現する。
しかしながら、コンテナを実行する場合、runCを直接操作することはあまりなく。ユーザーはDockerをはじめとするコンテナエンジンを介して、runCを呼び出す形となる。このように、コンテナの実行はいくつかのコンテナランタイムを経由して実装されることとなる。このように標準規格によりランタイムをAPI化することで、多様なワークロードに対応するしくみを構築することができる。
ランタイムのレイヤとしては大きく2つ存在し、runCのようにコンテナを操作するものを「ローレベルコンテナランタイム(Low-level Container Runtime)、またコンテナイメージを展開し、ローレベルコンテナランタイムに受け渡すコンテナライタイムを「ハイレベルコンテナランタイム(High-level Container Runtime)」と呼ぶ。


- ローレベルコンテナランタイム(Low-level Container Runtime) : カーネルの機能などを利用しながら、コンテナの隔離環境の作成やコンテナを直接操作するランタイム。RunCやgVisorを指す。
- ハイレベルコンテナランタイム(High-level Container Runtime) : OCIのコンテナイメージフォーマットに従ってイメージを展開し(ファイルシステムバンドルに回答)、ローレベルコンテナランタイムにコンテナ実行作業を受け渡すランタイム。containerdやcri-oを指す。
なお、Dockerはコンテナランタイム以外にも、コンテナのビルドやネットワークの管理などが同梱されたパッケージであり、内部のランタイムにはContainerdが利用されている。
Kerbernetesを利用する上では、こうしたコンテナランタイムを細かく意識する必要はない。しかし、Kubernetesから、APIを経由してハイレベルコンテナランタイムが呼ばれていることは、理解しておく必要がある。
containerdとcri-oについて
containerdは、もともとDocker Incが独自に開発していたコンテナランタイムだが、コンテナ技術の中立性を保つために、2017年にCNCFに寄贈されたものとなる。
containerdは、OCIの意向とともに発展してきたこともあり、バージョンによって実装アーキテクチャに差がある。バージョン1.0の段階ではCRIに対応しておらず、Kubernetesからcontainerdを利用する際には、CRI-Containerdをブリッジとして設ける必要があった、しかし、バージョン1.1よりCRIのPluginがcontainerdに内蔵されることによって、直接Kebernatesと接続できるようになった。
cri-oは、CRIに必要な最低限の機能を提供し、コンテナ実行エンジンの軽量化を目指しているプロジェクトとなる。Kubernetesコミュニティのひとつとして活発に開発されており、Dockerが持つcontainerd機能の豊富さとは対照的に、cri-oはCRIの提供範囲の実装としての役割を持つため、CRIの要求に応じた監視やリソース分割などの機能はあるが、コンテナを柔軟に操作するためのコマンドや、コンテナイメージのBuild/Push機能は持ち合わせていない。基本的にはコンテナを実行することがcri-oの役割となる。


AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.

