
AWSクラウドサービスデザインパターン(2)
Amazon Web Serviceクラウドデザインパターン設計ガイドより。

クラウドコンピューティングが普及するにつれて、コンピューターリソースの調達と運用に大きな変化が起こっている。クラウドにより、必要なときに必要なだけ、多岐にわたるITリソースを、安価かつ瞬時に調達することが可能となり、ITの新しい世界の幕開けとなった。
特に、2006年からクラウドサービスを提供しているAmazon Web Service(以下AWS)の進化は目覚ましく、仮想サーバー、ストレージ、ロードバランサー、データベース、分散キュー、NoSQLサービスなどの多種にわたるインフラストラクチャサービスを、初期費用の無い安価な従量課金モデルで提供している。利用者は、これらの非常にスケーラビリティの高いサービスを、必要な時に必要なだけ瞬時に調達して利用でき、また、必要なくなったときは、すぐに廃棄でき、その瞬間から利用料はかからなくなる。
これらのクラウドサービスにはすべてAPIが備わり公開されているので、Web上のツールからコントールできるだけでなく、ユーザーはプログラマブルにインフラストラクチャをコントロールできる。もはやインフラストラクチャは物理的に硬くて融通の効かないものではなく、非常に柔軟で変更ができるソフトウェア的なものになったといえる。
このようなインフラストラクチャを使いこなせば、これまでの常識では考えられないほど素早く安価に、耐久性が高くスケーラビリティがあり柔軟性の高いシステムやアプリケーションを構築できるようになる。こうした「インターネット時代の新しいサービスコンポーネント(=クラウド)」が用意された時代においては、システムのアーキテクチャ設計に携わる人には、新しい心構え、新しい発想、新しい標準が必要となる。つまり、新しいITの世界は、クラウド時代の新しいノウハウを身につけたアーキテクトを欲している。
日本にも2011年3月にAWSのデータセンター群が開設され、すでに数千の企業やディベロッパーが、AWSを活用してシステム作りをしている。顧客は、趣味でインフラを用いる個人のディベロッパーから、新しいビジネスを素早く立ち上げるスタートアップ、コスト削減の波にクラウドで抗おうとする中小企業、クラウドのメリットを見逃せない大企業、そして官公庁や自治体、教育機関に至るまで非常に幅広い。
クラウドを利用するユースケースとしても、典型的なWebサイト・Webアプリケーションのクラウドホスティングから、既存の社内ITインフラの置き換え、バッチ処理、ビッグデータ処理や化学計算、それから、バックアップやディザスターリカバリーまであり、汎用的なインフラとして利用されている。
クラウドの特徴を活かすことで、これまで考えられなかったようなビジネスやアプリケーションを実現し、新規事業、新規ビジネス、新規サービスとして成功を収めた例や、既存システムを移行してTCOを削減した例もすでに存在している。
しかしながら、クラウドを使おうとして挫けてしまった例はいまだに耳にするし、クラウドを最大限に活用したアーキテクティングを実施できているのは残念ながらいまだ多く無い、というのが現状となる。特にクラウド特有のメリットを活かした設計、例えばスケーラビリティ(Scalability)を活かすための設計や、システム全体で耐障害性を高める設計(Design for Failure)、コストメリットを考慮した設計などが十分にできているケースは未だ少ない。
ここではそれらのクラウドを用いた新しいアーキテクティングのパターンを整理したもの、Cloud Design Pattern(CDP)について述べる。
CDPは、クラウドを利用したシステムのアーキテクチャ設計時に起こる、典型的な問題とそれに対する解決策を、その本質を抽象化して再利用できるように整理・分類したものとなり、これまでアーキテクトが発見してきた、もしくは編み出してきた設計・運用のノウハウを、再利用が可能なデザインパターンという形式で、暗黙知から形式知に変換したものといえる。
CDPを用いることで、下記が可能となる。
- 既存ノウハウを活かすことで、クラウドを用いたシステムのより良いアーキテクチャ設計が可能となる。
- アーキテクト同士で共通の言葉を使って会話できるようになる。
- クラウドがより理解しやすくなる。
以下にCDPのパターンのうち、 前回「基本パターン」「可用性向上パターン」「動的コンテンツの処理パターン」「静的コンテンツの処理パターン」について述べた。今回は「データアップロードのパターン」「リレーショナルデータベースのパターン」「非同期処理/バッチ処理のパターン」について述べ「運用保守のパターン」「ネットワークのパターン」については 次回述べる。
データアップロードのパターン
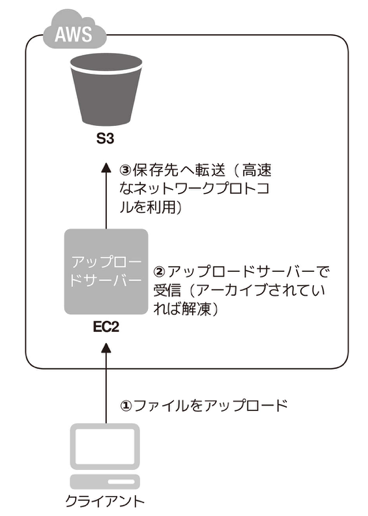
- Write Proxy: インターネットストレージは一般に、読み込みに対するキャパシティやデータの耐性は高い。しかし、冗長性を保つために複数ロケーションに書き込んでいる他、HTTPプロトコルでクライアントと通信しているので、書き込み速度が比較的劣るという性質があり、大量データをインターネットストレージに書き込む場合に、パフォーマンスが問題となる。この課題に対して、クライアントからインターネットストレージに直接データを転送するのではなく、仮想サーバーでデータを受け、その仮想サーバーからインターネットストレージへ転送する形を取る。仮想サーバーからインターネットストレージまでの通信はHTTPではなくもっと高速な(UDPベース)ものを使うことができ、小さいサイズのファイルが大量にある場合は、クライアント側で一度アーカイブし、仮想サーバーに転送後に解凍してインターネットストレージに転送することも可能となる。


- Storage Index: インターネットストレージはデータが分散配置されているので耐久性も可用性も高い。ただ、インターネット経由でアクセスすることになるのでオンプレミスに比べて一般に応答性能は低い。また高度な検索機能は用意されていないので、特定ユーザーのデータ一覧を取得したり、ある日付範囲のデータを取得する場合に、アプリケーション側で工夫が必要となる。これに対して、インターネットストレージにデータを格納する際に、同時に検索性能の高いKVSへメタ情報を格納し、検索はKVSを用い、得られた結果をもとにインターネットストレージにアクセスする。


- Direct Object Upload: 写真や動画の共有サイトでは、多数のユーザーからサイズの大きいデータがアップロードされる。アップロード処理はサーバー側の負荷(特にネットワーク負荷)が高く、ある程度の規模のサイトでも、アップロード専用の仮想サーバーが必要になる。アップロード処理をインターネットストレージに任せる。つまり、クライアントから仮想サーバーを経由することなく、インターネットストレージに直接アップロードする。


リレーショナルデータベースのパターン
- DB Replication: システムにとって重要なデータを守る基本的な方法はデータベースに格納することとなる。さらに近年ではデータベースのレプリケーション機能を使うことも増えている。レプリケーションは従来はコストの観点から一つのデータセンターにとしでいることが多かったが、大規模な災害時にはデータセンターごと損傷を受けるケースを想定しなければならなくなった。この課題に対応するため、地域的ロケーションを跨いだレプリケーションを行う。


- Read Replica: データベースへのアクセス頻度が高くDBサーバーのリソースが逼迫している場合、サーバーのスペックを上げる(つまりスケールアップする)ことが多い。スケールアップが困難になると、DBサーバーを水平分散するスケールアウトが行われるが、一般には難しい。通常はデータベースの書き込みより、読み込みの比率が高いため、まず読み込み処理を分散してシステム全体のパフォーマンス向上を目指すことが求められる。この課題に対して、読み込みを複数の「リードレプリカ(読み込み専用のレプリカ)」に分散させることで、全体のパフォーマンスを向上させる。


- Inmemory DB Cache: データベース負荷の大部分は読み込みに関するものであることが多い。そのためデータベースからの読み込みパフォーマンスを向上するため、頻繁に読み込まれるデータをメモリにキャッシュする。


- Sharing Write: RDBMSの書き込みに対する高速化は非常に重要で、また難易度の高い課題となる。複数のデータベースサーバーで書き込みパフォーマンスを上げるために「シャーディング」(基本的に、同じ構造のデータベースを用意して適切なテーブルの絡むをキーにして分割し、書き込み処理を分散する)


非同期処理/バッチ処理のパターン
- Queuing Chain: 複数システムで処理を連携させて逐次的な処理(例えば、画像処理の場合、画像のアップロード、保存、エンコーディング、サムネイル作成などの逐次処理)を行う場合。システム同士が密に結合しているとパフォーマンス面でボトルネックが発生しやすい。また、障害時の復旧作業が煩雑になってしまう。できるだけシステムを疎結合にすることがパフォーマンスの面で好ましいという課題に対して、システムを疎結合にするために、システム間をキューで繋ぎ、ジョブの受け渡しをメッセージの送受信で行うことで非同期のシステム連携を実現する。この方法の場合、メッセージを受け取って処理する仮想サーバーの数を増やして並列処理できるため、ボトルネックを解消しやすく、仮想サーバーに障害が生じても、未処理のメッセージがキューに残っているので、仮想サーバーが復旧次第、処理の再開も容易になる。


- Priority Queue: 多くのバッチジョブを処理する必要があり、しかもジョブに優先順位があるケースが考えられる。例えばプレゼンテーションファイルをWebブラウザーからアップロードして公開できるサービスで、無料ユーザーと会員ユーザーでサービスレベル(公開までの時間)が異なる場合などが、そのケースに該当する。ユーザーがプレゼンテーションファイルをアップロードすると、システム側で公開するための変換処理などをバッチ処理で行い、変換後のファイルを公開する。そのバッチ処理の優先順位を会員種別ごとに、どのように優先順位付けするかが課題となる。そのような課題には、バッチジョブの管理としてキューを優先順位の数だけ準備し、ジョブリクエストをキューで管理し、キューのジョブリクエストをバッチサーバーで処理する形とする。


- Job Observer: バッチ処理の負荷分散として、ジョブリクエストをキューで管理し、キューのジョブリクエストを複数のバッチサーバーが並列に処理する方法がある。しかし、用意するバッチサーバー数はピークに合わせた数となるため、ピーク外の時間帯ではバッチサーバーのリソースがあまり、コスト効率が悪くたる課題に対応するため、クラウドで負荷をモニタリングして仮想サーバーを自動的に増減させることで、コスト効率をよくさせる。


- Fanout: あるデータを元に、複数の処理を実行したいケース、例えば、画像をアップロードした後に、サムネイル、画像認識、メタデータのスキャンの三つのタスクを実行するケースなどについて、画像アップロードを検知したアプリケーションからそれぞれの処理を呼び出して逐次処理を行うと、各処理の時間が長い場合、トータルで非常に長くなる。このような課題に対して、処理を呼び出すプロセスから直接処理を呼び出すのではなく、間にノーティフィケーション(通知)コンポーネントとキューインテグコンポーネントを入れることで、非同期かつ並列に処理が可能とする。処理を呼び出すプロセスは、通知先への通知の後に、処理を実行できる。また、通知先の処理については知っている必要がないため、処理を増やしたい場合も通知コンポーネントへの通知先登録を増やせば対応できる。また、キューごとに処理を割り当てて動作させれば、並列に処理を実行できる。




AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.

