
人工知能技術 ウェブ技術 知識情報処理技術 セマンティックウェブ技術 自然言語処理 機械学習技術 オントロジー技術 オントロジーマッチング技術
オントロジーマッチングより自然言語の類似性について。前回は文字列ベースの類似度のアプローチについて述べた。今回は言語ベースのアプローチについて述べる。
前回までは文字列は文字の並びとして考えてきたが、一般的な活用を考えると、単語単体ではなく文字列(文)として扱うことが重要となる。ここで例えばtheoretical peer-reviewed journal articleという文字列を、辞書の項目に由来して、容易に識別可能な文字の並びである単語(theoretical, peer, reviewed, journal, article)に分割する時、これらの単語は、情報検索で使われるようなBag of Wordではなく、文法的な構造を持った配列の中に入っているものとなる。ここではpeerのような単語は、意味を持ち、ある概念と関連しているが、文章の中で適切に扱われるべきより有用な概念は、peer-reviewやpeer-reviewed journalなどの用語になる。
用語とは、概念を特定するためのフレーズであり、オントロジーの概念のラベル付けによく用いられるものになる。そのため、オントロジーのマッチングでは、文字列の中の用語を認識・識別することで、大きなメリットを得ることができる。これは、Peer-reviewed journal という用語を、査読者によって査読された科学定期刊行物というラベルで認識することに相当する(journal review paper ではない)。
言語ベースの手法では、自然言語処理(NLP)技術を使用して、テキストから意味のある用語を抽出する。これらの用語とその関係を比較することで、オントロジーのエンティティの名前やコメントの類似性を評価することができる。これらは何らかの言語的知識に基づいているが、大きく分けて(1)アルゴリズムのみに依存する手法(内在的な方法)と、(2)辞書などの外部リソースを利用する手法(外在的な方法)とに区別することができる。
(1)内在的な方法。言語的正規化
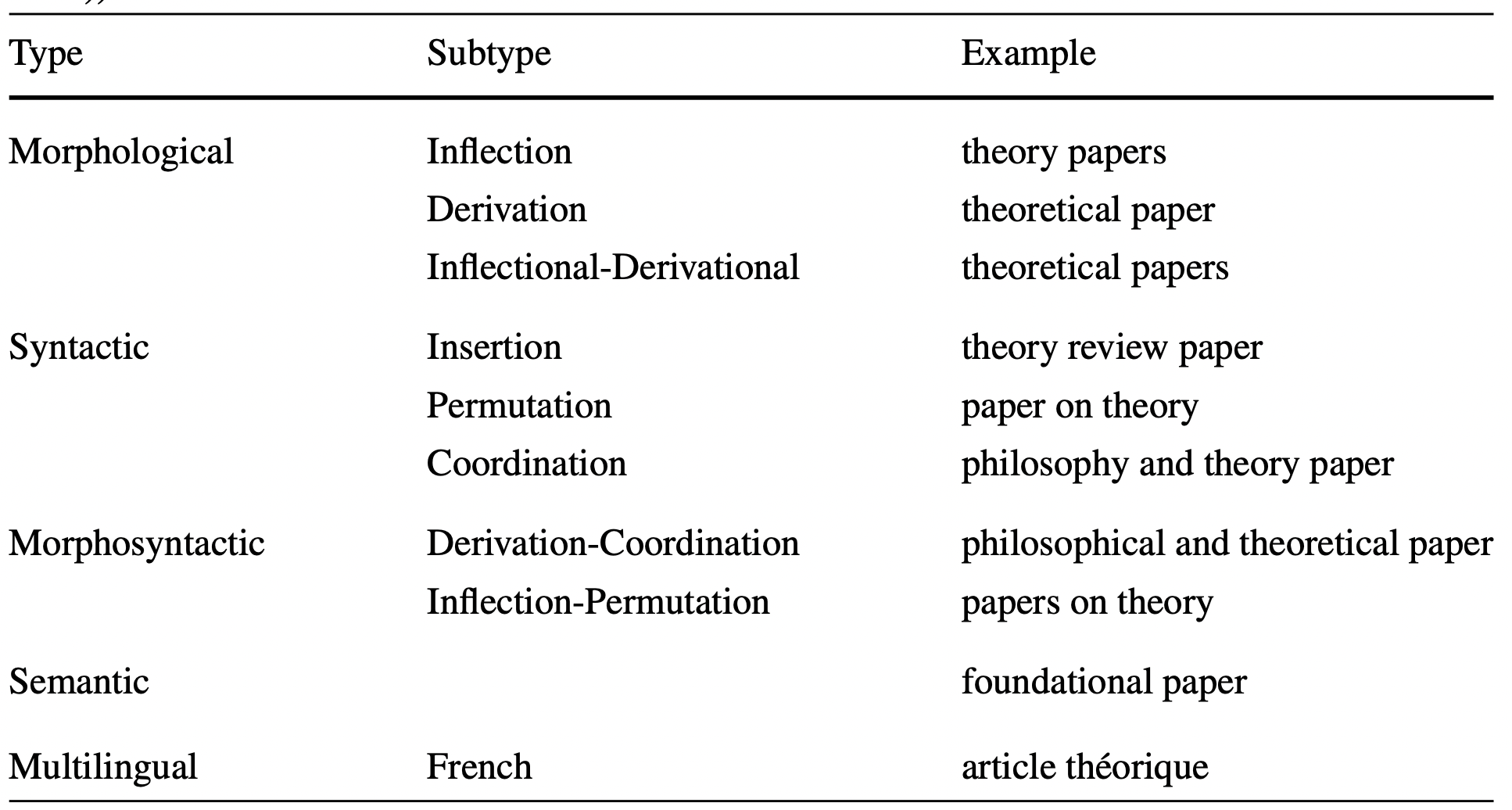
言語的な正規化は、用語の各形式を、簡単に認識できる標準化された形式にすることにより実現される。下表によると、同じ用語(theory paper)がさまざまな形で現れることが分かる。この用語のバリエーションには、主に次の 3 種類がある(Maynard and Ananiadou 2001)。すなわち、(1)形態学的(Morphological:同じ語源に基づく単語の形と機能に関するバリエーション)、(2)統語学的(Syntactic:用語の文法構造に関するバリエーション)、(3)意味学的(Semantics:通常、ハイパ-ニム(他の語の概念を包括する語)またはハイポニム(下位語)を使用して、用語の一側面に関するバリエーション)となる。多言語のバリエーション、すなわち、用語のバリエーションが異なる言語で表現されているようなものは、更にこれらに加えることができる。これらの大まかな分類の様々なサブタイプが下表に例示されている。さらに、これらのタイプのバリエーションは様々な方法で組み合わせることができる。


トークン化。トークン化とは、文字列を、句読点、大文字小文字、空白文字、数字などを認識して、一連のトークンに分割するものとなる。例えば、theoretical peer-reviewed journal article(査読付きの定期刊行物)は、⟨peer, reviewed, periodic, publication⟩ となる。
Lemmatisation: トークンの基礎となる文字列を形態学的に分析し、正規化された基本形に落とし込む機能を持つモジュール。形態学的分析により、語根の屈曲や派生を見つけることができ、これには、時制、性別、数のマークを抑制することが含まれる。それらルートを検索することを「レマチゼーション」と呼ぶ。システムでは、用語から接尾辞を取り除くステミング (Lovins 1968; Porter 1980) と呼ばれる機能もある。これはたとえば、reviewをre-view にするようなものになる。
用語の抽出。テキストから用語を抽出するモジュール(Jacquemin and Tzoukermann 1999; Bourigault and Jacquemin 1999; Maynard and Ananiadou 2001; Cerbah and Euzenat 2001)。一般的には、コーパス言語学と呼ばれるものに関連しており、比較的大量のテキストを必要とする。用語抽出器は、テキスト中の形態学的に類似したフレーズの繰り返しや、「noun1 noun2 → noun2 on noun1」などのパターンの使用から用語を特定する。例えば、noun1 noun2 → noun2 on noun1 のように、 theory paper という用語が paper on theory と同じ用語であることを認識することができる。
ストップワードの除去。冠詞、前置詞、接続詞などとして認識されるトークン(通常はtoやaなどの単語)は、マッチングのための無意味な(空虚な)単語とみなされるため、破棄するようマークされる。例えば、collection of articleはcollection articleとなる。(参考:clojureでの実装)
これらの技術が適用されると、オントロジーのエンティティは、単語ではなく用語のセットとして表現され、前回紹介したものと同じ技術を用いて比較することができる。
(2)外在的な方法
外在的な言語手法は、用語間の類似性を見つけるために、辞書や語彙などの外部のいくつかの種類の言語資源を使用する。
レキシコン(Lexicons):レキシコン(辞書)とは、一連の単語と、その単語の自然言語による定義となる。Articleなどの特定の単語に対して、そのような定義が複数存在することがある。辞書は、用語ベースの距離(下記参照)と一緒に使うことができる。
意味論的統語論的辞書(Semantico-syntactic lexicons):意味論的統語論的辞書や意味論的辞書は、自然言語分析装置で使用されるリソースとなる。これらの辞書には、名前だけでなく、無生物、液体などのカテゴリが記録されており、動詞や形容詞が取る動詞のタイプも記録されている。例えば、to flowは液体を主語とし、目的語を持たないというようなものとなる。これらは作成が難しく、オントロジーマッチングではあまり使われない。
シソーラス(Thesauri):シソーラスとは、ある種の辞書に関係情報を追加したものとなる。例えば、BiographyはAutobiographyよりも一般的な用語でありのhyponymとなる。PaperはArticleは同義語であり同じ意味になり、practiceはtheoryとは反意語で反対の意味となる。WordNet(Miller 1995)はこのようなシソーラスで、単語を同義語のセット(synset)にグループ化することで、語義を明確に区別している。
用語集。用語集とは、用語のシソーラスであり、単一の単語ではなくフレーズを含むことが多い。通常、ドメインに特化しており、辞書よりも曖昧さが少ない傾向がある。
これは、言語資源を網羅的に説明するものでも、公認のものでもありませんが、用語間の類似性を言語的に評価できる特性の類型を提供しています。
これらのリソースは、ある言語のために定義されている場合もあれば、あるドメインに特化している場合もある。後者の場合、特殊な意味や日常的な言語には存在しない意味を保持しているため、テキストやオントロジーがそのドメインに関係する場合には、より適合する傾向がある。また、ドメインで使用される固有名詞や一般的な略語が含まれることもある。例えば、企業であれば、CDをCompact Discとしたり、POをPurchase Orderとし、Post OfficeやProject Officerの代わりにしたりする。
言語資源は、同義語に対応するために導入される(一致するエンティティは異なる名前であるため)。単語の解釈(意味)を増やすことで、一致する単語を見つける可能性(真の陽性)を高める。しかし、その一方で、同音異義語が増えたり(一致する語句が増えること)、一致しない語句が誤って一致してしまう可能性(偽陽性)ケースも出てくる。この問題への対処は、語義曖昧性解消(Lesk 1986; Ide and Véronis 1998)として知られている。(Leskに関しては”Leskアルゴリズムの概要と関連アルゴリズム及び実装例について“も参照のこと) これは、文脈から候補となる語義(およびマッチ候補)を制限しようとするもので、特に、他の関連する単語とその語義に関連して語義を選択することになる。語義曖昧性解消技術は、オントロジーマッチングで集中的に使用されてきた(Gracia 2009)。Blooms (Sect. 8.1.34) のように、オントロジーで使用されている用語の曖昧さを解消する方法として、Wikipediaの曖昧さ解消ページを使用するシステムもある。
ここでは、WordNet(Miller 1995; Fellbaum 1998)を用いて、外部リソースの利用方法を説明する。WordNetは英語の電子語彙データベースとなる(例えばEuroWordNetのように他の言語にも適応されている)。シンセットは、一群の用語の概念または意味を表す。WordNetでは、hypernym(上位概念/下位概念)構造や、meronym(関係の一部)などの他の関係も提供している。また、定義や例を含む概念のテキストによる説明(グロス)も提供している。ここでは、WordNetを部分的に順序付けられた同義語リソースとみなす。
定義 21 (Partially ordered synonym resource) 単語の集合W上の部分的に順序付けられた同義語資源Σは、 E⊆2Wが同義語の集合であり、≦が同義語間のハイパーニム関係であり、 λが同義語からその定義(ここではWの単語の袋として考えられるテキスト)への関数であるような、 三重の⟨E,≦,λ⟩である。ある用語tに対して、Σ(t)はtに関連するsynsetsの集合を表す。
例 として単語 author の WordNet (version 2.0) のエントリを以下に示す。それぞれの意味には上付き文字で番号が付けられている。
author1 noun: Someone who originates or causes or initiates something; Ex- ample ‘he was the generator of several complaints’. Synonym generator, source. Hypernym maker. Hyponym coiner. author2 noun: Writes (books or stories or articles or the like) professionally (for pay). Synonym writer2. Hypernym communicator. Hyponym abstractor, allit- erator, authoress, biographer, coauthor, commentator, contributor, cyberpunk, drafter, dramatist, encyclopedist, essayist, folk writer, framer, gagman, ghostwriter, Gothic romancer, hack, journalist, libretist, lyricist, novelist, pamphleter, paragrapher, poet, polemist, rhymer, scriptwriter, space writer, speechwriter, tragedian, wordmonger, word-painter, wordsmith, Andersen, Assimov. . . author3 verb.: Be the author of; Example ‘She authored this play’. Hypernym write. Hyponym co-author, ghost.
これは、HypernymとHy-ponymの機能と、考慮された感覚の明示的な言及を除けば、伝統的な辞書エントリに似ている。図5.1は、creator, writer, author, illustrator, personの各語のハイパーニーム関係を示したものとなる。
オントロジーエンティティで使用されている用語を照合するためのリソースとしてWordNetを使用する方法には、少なくとも3つの系列がある。
– 2つの用語が何らかの共通のシンセットに属しているために類似していると考える方法。
– 2つの用語に対応するシンセット間の距離を測定するために、ハイパニム構造を利用する。
– 2つの用語に関連するシンセット間の距離を評価するために、WordNetが提供する概念の定義を利用すること。

WordNetに基づいたマッチャーは,WordNetが提供する(語彙的な)再表現を,以下のルールに従って論理的な関係に変換することで設計できる(Giunchiglia et al.2004)。
- tがt′のハイポニムまたはメロニムである場合,t≦t′となる。例えば,authorはcreatorのhyponymであり,author ⊑ creatorと結論づけられる。
- tがt′のhypernymまたはholonymである場合,t≧t′となる。例えば、EuropeはFranceのholonymであり、したがって、Europe ⊒ Franceと結論づけられる。
- t = t′は,それらが同義語関係で結ばれているか,一つのシンセットに属している場合となる。例えば、writerとauthorは同義語であるから、writer = authorと結論づけることができる。
- t ⊥ t′, それらが反意語関係で結ばれているか、または階層の一部で兄弟である場合。例えば、ItalyとFranceはWordNetのパートオブヒエラルキーにおいて兄弟であり、したがって、Italy ⊥ Franceと結論づけられる。
ここでは単純な尺度を定義することができる(ここでは同義語のみを考慮しているが、これはWordNet同義語集合の基礎であるためで、他の関係を使用することもできる)。同義語の最も簡単な使い方は次の通りになる。
定義 23 (同義語の類似性) 2つの用語sとt、および同義語リソースΣが与えられた場合、 同義語とは以下のような類似性σ : S × S → [0 1] である。
\begin{eqnarray}\sigma(s,t)=\begin{cases} 1&(if \sum(s)\cap\sum(t)\neq \emptyset \\ 0& otherwise\end{cases}\end{eqnarray}
これは、authorとwriterの間の類似性が最大(1.)であり、authorとcreatorの間の類似性が最小(0.)であると考えられる。
illustrator, author, creator, Person, writer の例に対して同義語の類似度を計算した例を下表に示す。


このように同義語を厳密に利用すると、非同義語のオブジェクトがどれだけ離れているか、同義語のオブジェクトがどれだけ近いかを分析することができない。同義語は関係であるから、関係のグラフ上のすべての尺度は、WordNetの同義語に使用することができる。もう一つの尺度はcosynonymyの類似性を計算するものである。
定義 25 (Cosynonymy similarity) 2つの用語sとt、同義語リソースΣが与えられたとき、 cosynonymyは次のような類似性σ : S × S → [0 1] である。
\[\sigma(s,t)=\frac{|\sum(s)\cap\sum(t)|}{|\sum(s)\cup\sum(t)|}\]
illustrator, author, creator, Person, writerのcosynonymy類似度は次の表のようになる。


精巧な測定法の中には、用語が複数のシンセットの一部であることを考慮して、同義語集合間の下位概念-上位概念階層の測定法を用いるものがある。エッジカウントと呼ばれる単純な尺度は、Σ内の2つのsynsetsを隔てるエッジの数(または構造的位相的非類似性)を数える。さらに、Wu and Palmerによって提案されたように、エッジカウントを階層内のシンセットの位置で重み付けする方法もある。前述で定義されたすべての尺度は、根無し草の有向非循環グラフを扱うことができれば、WordNetのハイパーニーム・グラフに使用することができる。
他の尺度は、情報理論的な観点に基づいている。これらは、概念の可能性が高ければ高いほど、その概念が持つ情報は少なくなるという仮定に基づいています。つまり、概念の情報量は、その出現確率に反比例する。(Resnik 1995, 1999)で提案された類似性では、各シンセット(c)は、特定のコーパスにおけるその概念のインスタンスの出現確率(π(c))と関連付けられる。通常、π(c)はsynsetの単語の出現率の合計を概念の総数で割ったものである。この確率はコーパスの調査から得られる。この確率は、概念が具体的であればあるほど、低くなる。2つの用語間のレスニク意味的類似性は、両方の用語に共通するより一般的なシンセットの関数である。これは、出現確率の対数の否定として、そのようなシンセットの最大情報量(またはエントロピー)を考慮したものになる。
定義 27 (Resnik semantic similarity) 2つの用語sとt、および確率測度πが与えられた部分的に順序付けられた 同義語資源Σ = ⟨E, ≤, λ⟩が与えられた場合、 Resnik semantic similarityは、以下のような類似性σ : S × S → [0 1] である。
\[\sigma(s,t)=\displaystyle \max_{k;\exists c,c’\in E;s\in c∧t\in c’∧c≤k∧c’≤k }(-log(\pi(k)))\]
コーパスベースの類似性の例は、結果がベースとなるコーパス(ここではπを定義するためのもの)に依存するため、ここでは提供しない。Brownコーパス9に基づく類似度測定の例は(Budanitsky and Hirst 2006)に記載されている。
この尺度は最大値を用いているが、代わりに平均値や、2つの用語に関連するすべてのシンセットのペアの合計を選択することも可能である。
他の情報理論的な類似性は、共有された情報量ではなく、用語からその共通のハイパニムまでの情報量の増加に依存している。これは、Jiang-Conrath法(Jiang and Conrath 1997)やLin情報理論的類似性(Lin 1998)がそうである。(参考:事例間類似度の帰納に基づく分類手法)この方法では、2つのsynsetの間のオーバーラップの度合いを確率的に指定する。
定義 28 (情報理論的類似性) 2つの用語sとt、および確率πで提供される部分的に順序付けられた 同義語資源Σ = ⟨E , ≤, λ⟩が与えられた場合、 林情報理論的類似性は、以下のような類似性σ : S × S → [0 1] である。
\[\sigma(s,t)=\displaystyle \max_{k;\exists c,c’\in E;s\in c∧t\in c’∧c≤k∧c’k}\frac{2xlog(\pi(k))}{log(\pi(s))+log(\pi(t))}\]
これらの類似性は正規化されていない。
WordNetのようなシソーラスを使って文字列中の用語を比較する最後の方法は、これらの用語に与えられた定義(グロス)を使うことになる。この場合、任意の辞書エントリs∈Σは、λ(s)に対応する単語のセットによって識別される。そして、5.2.1節で定義した任意の尺度を文字列の比較に用いることができる(Lesk 1986)。
定義 29 (Gloss overlap) 部分的に順序付けられた同義語資源Σ = ⟨E,≦λ⟩が与えられた場合、 2つの文字列sとtの間の用語の重複は、それらの用語のJaccard類似度によって定義される。
\[ \sigma(s,t)=\frac{\lambda(s)\cap\lambda(t)|}{\lambda(s)\cup\lambda(t)|}\]
例として、 illustrator、author、creator、Person、writerの用語の重なりの類似度を計算するために、次の処理を行っ た結果は、単語のセット(バッグではないので、繰り返しはない)として扱われ、構文的に比較され、以下の表が得られた。


この結果は、これまでの測定法と一致している。なぜなら、これまで唯一一致していたペア(author-writer)が、依然として最高得点を得ているからである。この尺度は、creator-illustratorのような新しい関係を導入してい.が、creatorとauthorの間の(可能性のある)関係はまだ見つかっていない。これは、WordNet の用語集の質に完全に依存している。
(WordNetの)用語集を使用してマッチャーを構築する別の例としては、ソース入力センスのラベルがターゲット入力センスの用語集に出現する数をカウントすることが挙げられる。この数が閾値(例えば1)に等しい場合、一般性の低い関係を返すことができる。一般性の低い関係を返す理由は、より一般的な用語を介して用語集の用語を定義する一般的なパターンによる。例えば、WordNetでは、creatorは「物を育てたり、作ったり、発明したりする人」と定義されている。したがって、この戦略に従えば、creator ⊑ person を見つけることができる。用語集ベースのマッチャーの他のバリエーションとして、WordNet is a (part of) hierar- chy で入力感覚の親ノード (子ノード) の用語集を考慮するものがある (Giunchiglia and Yatskevich 2004)。これらのマッチャーが生成する関係は、マッチングタスクのコンテキストに大きく依存するため、これらのマッチャーをすべてのケースに適用することはできない(Giunchiglia et al.2006c)。(参考:コモンセンス知識ベースを用いた推論)
多言語対応の方法
オントロジーは、そのラベルがすべて1つの自然言語のみで利用可能な場合は単言語、複数の異なる言語を使用している場合は多言語となる。さらに、OWLやSKOSなどのオントロジー言語では、明示的に識別された言語で複数のラベルを宣言することができるため、オントロジーエンティティが識別される言語を評価することができる(例えば、Article@frはフランス語の「article」という単語になる)。
同様に、ラベルとして使用される2つの用語は、同じ自然言語に属する場合はモノリンガルに、2つの異なる自然言語に属する場合はクロスリンガルにマッチさせることができる。最初のオプションは、前のセクションで検討された技術に対応している。しかし、オントロジーが記述される言語が多様化していることから、言語横断的なマッチングが重要になってきている。これにはいくつかの方法があり、ピボット言語との比較や相互翻訳がある(Trojahn et al.2010b)。
ピボット言語との比較は、2つのオントロジーの用語を1つの特定の言語に翻訳するものである(Jung et al. これにより、必要な翻訳の数が減り、多言語オントロジーの複数の言語を一度に扱うことができる。1つのオントロジー内で、異なる言語のラベルで識別された同じエンティティがあると、ピボット言語のターゲットタームを曖昧にするのに役立つ場合がある。例えば、英語のPaperはスペイン語ではPapelやArticuloと訳されるが、フランス語のラベルがArticleであれば、適切な意味はArticuloとなる。通常、ピボット言語法が選択されるのは、異なる言語の用語を比較するための言語資源が利用できるからとなる。
相互翻訳では、一方のオントロジーのすべての用語を他方のオントロジーの言語に翻訳する(Fu et al. 2012)。翻訳には、言語間辞書などの言語間リソースの使用から、英語のPaperがフランス語のArticleに対応するなど、定義が他の言語の同等の用語に置き換えられている辞書まで、さまざまな技術が使用される。このような辞書は、オントロジーのラベルが異なる言語で表現されている場合に非常に有用となる。このような辞書は、マッチングだけでなく、マッチングの前に用語の曖昧さを解消する(つまり、意図された意味を特定する)ためにも使用できる。翻訳には、オンライン統計翻訳機などの他のリソースを使用することもできる(Trojahn et al.2010b)。
すべての用語が1つの言語(軸となる言語または相互翻訳の対象言語)だけで構成されている場合、通常の(単一言語の)技術を使って比較することができる。このことは、言語的マッチング技術に影響を与え、次のような区別をもたらします。
- 単言語マッチング:英語などの単一言語で書かれたラベルに基づいて2つのオントロジーをマッチングする。
- 多言語マッチング:英語、フランス語、スペイン語など、さまざまな言語のラベルに基づいて2つのオントロジーをマッチングする。これは、用語のパラレル・モノリンガル・マッチングや、異なる言語の用語のクロスリンガル・マッチングによって実現することができる。
- クロスリンガルマッチングとは、英語とフランス語など、2つの異なる言語で書かれたラベルに基づいて2つのオントロジーをマッチングさせること。
これらの定義は、Spohrら(2011)の定義とは若干異なり、2つ目の選択肢である多言語マッチングをcrosslingualと呼んでいる。また、多言語マッチングは、他の2つのオプション(1つの言語ペアのみでの多言語マッチング)よりも一般的なものとなっている。
多言語オントロジーが提供する興味深い技術に、Crosslingual val-idationがある。これは、フランス語とフランス語、英語と英語のように、異なる言語で2つのオントロジーを並行して照合し(7.2節)、これらの並行照合を集約してコンセンサスを得るというものになる。通常、十分な数のマッチャーが特定の対応関係を見つけた場合、その対応関係を保持する。この方法は、マッチングの精度を高めるのに有効であることがわかっている(Spohr et al.)
言語学的手法に関するまとめ
このセクションで紹介する多くの手法は、PerlパッケージのWordNet::similarity (Pedersen et al. 2004)とJavaパッケージのSimPack4に実装されている(表5.3参照)。これらは(Budanitsky and Hirst 2006)で徹底的に比較されている。
ステマー、品詞タガー、レキシコン、the-sauriなどの言語リソースは、オントロジーの表現に使用されている用語の解釈を可能にするため、非常に貴重なリソースとなる。オントロジーの表現に使われている用語を解釈することで、ラベルをより正確に理解することができる。
しかし、ある言語で適切なリソースが利用できる場合、2つの用語が同じ概念を表すことを認識するため、主にエンティティ間の新しいマッチの可能性を開く。残念なことに、これらの技術は、同じ用語が同時に複数の概念を表す可能性があることも認識しているため、多くのマッチの可能性を提供している。
これらの表現を選択する一つの方法は、オントロジーエンティティの構造を考慮して、最も首尾一貫したマッチを選択することとなる。


以上言語的なアプローチについて述べた。次回は内部構造に基づく手法について述べたいと思う。


AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.


コメント
[…] 以上文字列ベースの類似度について述べた。次回は言語ベースの手法について述べる。 […]
[…] 前回は言語ベースのアプローチについて述べた。今回は内部構造に基づいたアプローチについて述べる。 […]
[…] 前回は内部構造を用いたアプローチについて述べた。今回は外部構造に基づいたアプローチについて述べる。 […]
[…] 前回はグラフパターンを用いたアプローチの概要とTaxonomicなアプローチについて述べた。今回はグラフパターンのもう一つのアプローチである目レオロジックなアプローチについて述べる。 […]
[…] 自然言語の類似性(similarity)(3)言語ペースのアプローチ […]
[…] 前回はグラフパターンを用いたアプローチの概要とTaxonomicなアプローチについて述べた。今回はグラフパターンのマッチングに対して反復的な類似性の計算を行うアプローチについて述べる。 […]
[…] 前回は類似性を表す方程式のセットを用いた反復的な類似性計算アプローチについて述べた。今回はそれらを更に拡張した最適化アプローチについて述べる。今回はそれらの中からまず、期待値最大化と粒子群最適化の2つの手法について述べる。 […]
[…] 類似性(similarity)について(3)言語ベースのアプローチ […]
[…] 前回は類似性を計算する為の、期待値最大化と粒子群最適化の2つの手法について述べた。今回はそれらの確率的アプローチに拡張したものに対して述べる。 […]
[…] 前回は類似性を計算する為に、確率モデルであるベイジアンネットワークモデル、マルコフモデル、マルコフロジックネットワークのアプローチについて述べた。今回は意味的アプローチに対して述べる。 […]
[…] 概要 2.類似性(similarity)の基礎(2)文字列からのアプローチ 3.類似性(similarity)の基礎(3)言語ベースのアプローチ […]
[…] そこで、次の段階として、人間が使う辞書の代わりに、コンピューターに単語の意味を教えることを念頭に置いて作られた辞書を考える。この様な辞書としては、英語ではWordNet、PropBank、FrameNetなどが有名なものとしてある。ここでは、WordNetについて述べる。 […]