
similarity(類似性)マッチング手法での戦略(4)アライメントのソートのための学習
前回はオントロジーマッチング戦略の一つである重み付けによる選択に対して述べた。今回はアライメントソートのための学習について述べる。
このセクションでは、多くの正しいアラインメント(正例)と正しくないアラインメント(負例)を提示することで、アラインメントのソート方法を学習するアルゴリズムについて説明する。これらのアプローチの主な違いは、本項の技術が学習のためにいくつかのサンプルデータを必要とすることにある。これは、アルゴリズム自身が提供し、判断対象となる対応関係のサブセットのみを用意するなどして、ユーザーが判断することもできるし、外部のリソースから持ってくることもできる。


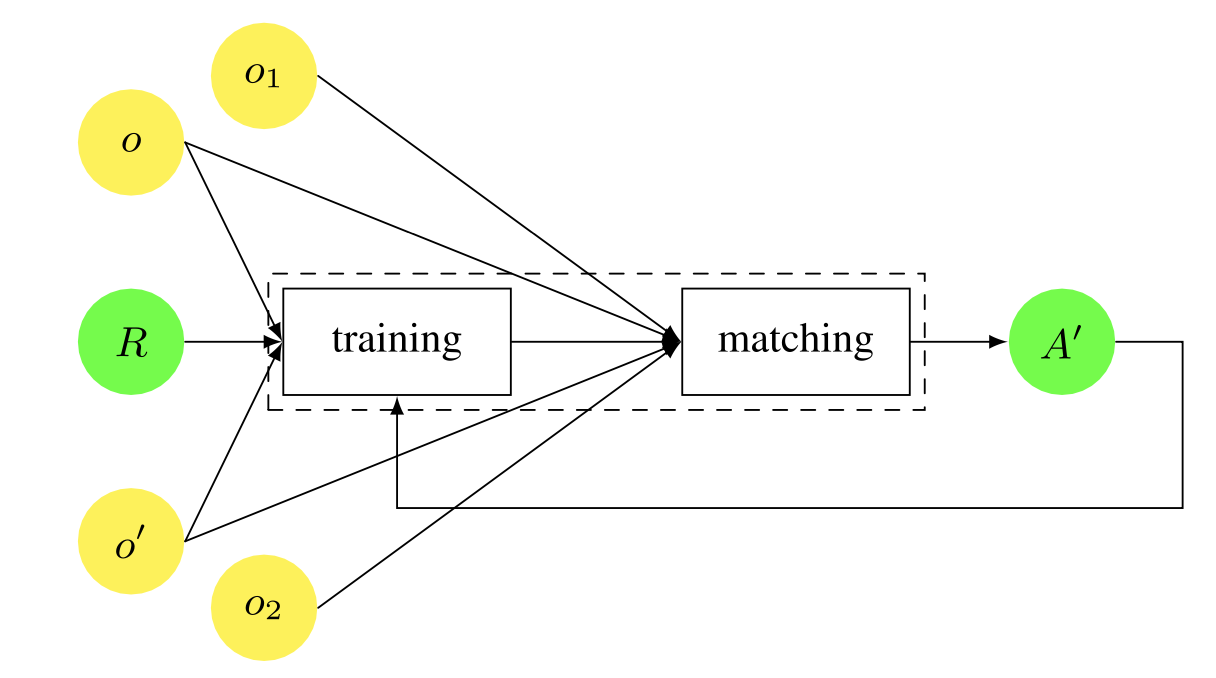
機械学習を用いたマッチャーは、通常、2つのフェーズで動作する。(1)学習またはトレーニング段階と、(2)分類またはマッチング段階である。第1フェーズでは、例えば、2つのオントロジーを手動でマッチングさせるなどして、学習プロセスのためのトレーニングデータを作成し、システムがこのデータからマッチャーを学習する。第2段階では、学習したマッチャーを新しいオントロジーのマッチングに使用する。得られたアラインメントに関するフィードバックが提供され、それが再びステップ(1)に反映されることもある。学習は、システムが継続的に学習できるように、オンラインで処理することもできるし、精度よりも速度を重視する場合はオフラインで処理することもできる。
通常、このプロセスは、データセット(アライメントの正例と負例のセット)を、学習セット(通常、データの80%)と、学習アルゴリズムの性能を評価するために使用される制御セット(通常、データの20%)に分割することによって行われる。
学習者が利用できる情報には多くの種類がある。例えば、単語の頻度、フォーマット、位置、値の分布の特性などになる。また、複数の学習器を用いて、それぞれの学習器が得意とするパターンを扱う場合には、多戦略学習法が有効となる。最後に、様々な学習者によって生成された結果は、メタラーナーの助けを借りて結合することができる(Doan et al. 2003)。
本節では、テキストの分類に用いられてきた有名な機械学習法である、ベイズ学習、WHIRL学習、ニューラルネットワーク、サポートベクター・マシーン、決定木などについて述べる。
ベイズ学習
ナイーブ・ベイズ学習(Good 1965)は、確率的な誘導アルゴリズムである。様々なマッチングアプローチにおいて、分類器として使用されている(Doan et al. 2004, Straccia and Troncy 2006, Lambrix and Tan 2006, Nandi and Bernstein 2009, Spiliopoulos et al. 2010, Esposito et al. 2010, Tournaire et al. 2011)。
あるオントロジーの属性xを,別のオントロジーの属性(y1, … , ym, i = 1, … , m)の1つ(yi)にマッチさせたいと仮定する。このアプローチでは、属性の値をトークンのセットと見なす。Vは、属性xの基本的な値のセットを表す。V = {t1,…,tn}, ここで tj は j 番目のトークンで,j = 1,…,n とする。トークンは,データ・インスタンス内の単語にレマチス化などの正規化技術を適用することで得られる。P (yi )は,先験的に x が yi にマッチする確率,つまり x のトークンを見たことがない状態での確率であるとする。次に,P (V ) は,x の中で値 V を観測する確率を表す. 最後に,P (V |yi ) は,x が yi にマッチすることを前提に,値 V を観測する条件付き確率を表す。ベイズの定理は,学習例が与えられたときに,それまで見たことのないデータインスタンスの属性を最適に予測する方法を示す。選択された属性は,値 V を見た後に x が yi に一致するという事後確率を最大化するものとなる。これは,P (yi |V ) で表され,次のように計算される。
\[P(y_i|V)=\frac{P(V|y_i)\times P(y_i)}{P(V)}\]
これをベイズ則という。ナイーブ・ベイズ分類器は,yi が与えられたとき,トークン tj は互いに独立して V に現れるという素朴な仮定を持つ。この仮定に基づいて、各属性のパラメータ(トークン)を別々に学習することができ、これにより学習が非常に簡単になる。このように、属性がクラスに依存しない場合、P(V|yi)はP(t1|yi)×–P(tn|yi)の積に分解され、P(V )は当然のことながらベイズ則から省略できる。以後、ベイズ則は次のように書き換えられる。
\[P(y_i|V)=P(y_i)\times \displaystyle\prod_{1\leq j \leq n}P(t_j|y_j)\]
独立性の仮定は実際には成り立たないことが多い。しかし、多くのアプリケーションでは、この仮定に違反しても、アプローチの有効性が損なわれることはない(Domingos and Pazzani 1996)。
後者の式の確率は,学習データを用いて計算することができる.P(yi )は yi にマッチした例の割合で推定でき,P(tj|yi)は k(tj,yi)/k(yi)として推定できる。ここで k(yi)は属性 yi を持つすべてのトレーニングインスタンスのトークンの総数であり,k(tj , yi )は属性 yi を持つすべてのトレーニングインスタンスにおけるトークン tj の出現回数である。上の式に基づいて、対応する信頼度スコアを明白な方法で設計することができる。
ナイーブベイズ学習の学習の例。 あるオントロジーの属性creatorとnameが、別のオントロジーの属性authorとtitleにそれぞれ一致することを手動で確認したとする。このプロセスは2つのステップで構成されている。
学習段階。Bertrand Russellがcreator属性のインスタンスであり、My lifeがname属性のインスタンスであると仮定する。したがって、この情報に基づいて、次の学習例を分類器に与えることができる: ⟨{‘Bertrand’, ‘Russell’}, author⟩ and ⟨{‘My’,’life’},title⟩. 2つ目の宣言は、{‘My’,’life’}がタイ トルであり、2つのトークンを持つことを宣言している。学習者は学習インスタンスを調べることで、内部の分類モデルを構築する。例えば、「life」のような単語が、タイトルに関連するデータインスタンスに頻繁に出現し、他の分野に関連するデータインスタンスにはあまり出現しない場合、その基本属性はタイトル属性と一致する可能性が高いことに気づき、データインスタンスの分類方法を決定する。学習セットが統計的に代表的なものであれば、これらの頻度は確率に変換され、ベイズ則を使用することができる。これは、例えば、⟨{title:My title:life}, class:biography⟩のように、インスタンスをクラスに分類することにも適用できる。
マッチング段階。Life of Piを、上記の第2のオントロジーの属性と照合したい、ウェブサイトの構造から得られる属性h1のインスタンスとする。学習者は内部の分類モデルを使って、与えられたインスタンスの属性とその信頼度スコアを予測する。例えば、⟨author, 0.2⟩, ⟨title, 0.8⟩。信頼度スコアに基づいて、h1はtitleにマッチすると結論付けられる。
WHIRL学習器
WHIRLは、従来のリレーショナルデータベースを拡張したもので、テキスト識別子の類似性(原子値の等価性に基づくものだけではない)に基づいてソフト結合を行う(Cohen 1998)。WHIRLはテキストの帰納的分類にも使用されており,ディシジョンツリーなどの他の帰納的分類システムに負けないことがわかっている(Cohen and Hirsh 1998).WHIRLのテキスト分類アプローチは,一種の最近傍分類アルゴリズムとみなすことができる.すなわち,すべての学習データがメモリに格納され,k個のインスタンスがEu-clidean距離によって選択され,(kNN)分類に用いられる(Nottelmann and Straccia 2006; Spiliopoulos et al. 2010).
WHIRLはスキーマレベルとインスタンスレベルの情報を学習するためのマッチングに使用されている(Doan et al. 2003; Bilke and Naumann 2005)。例えば、⟨location′,address⟩は、オントロジーの実体がlocationというラベルを持っていれば、addressにマッチするというものである。ラベル′の拡張は、例えば、その同義語を含めることで得られるが、同義語は、関心のあるドメインのために手動で作成されたコーレスポンデンステーブルから得られる。WHIRLは見たことのあるすべての学習例を保存している。別のオントロジーo′をオントロジーoにマッチングさせたいと仮定する。o′からラベル′′が与えられると、WHIRLはコレクション内のラベル′′に類似するすべての例のラベルに基づいて、oの対応するラベルを計算する。この類似性は,例の拡張ラベル間のTFIDFに基づいている.例えば,o′のラベルphoneが与えられた場合,WHIRLは以下のように予測を生成することができる.⟨address, 0.1⟩, ⟨description, 0.2⟩, ⟨agent-phone, 0.7⟩. 信頼度スコアに基づいて、phoneはagent-phoneにマッチすると結論付けられる。
インスタンスレベルの情報の場合,このマッチャーは,展開されたラベルの代わりにデータテントを使用する。この場合の学習例は、⟨data instances′,label⟩という形式で、data instances′はオントロジーo′に属し、labelはオントロジーoに属している。新しいオントロジーo′をオントロジーoにマッチングさせる場合、任意の2つの例の間のTFIDF距離は、o′のデータインスタンスとWHIRLコレクションのデータインスタンスの間の距離となる。
ニューラルネットワーク
人工ニューラルネットワークは、ノード(またはニューロン)とそれらの間の重み付けされた接続で構成されている。ノードは、入力、出力、および何もないか1つ以上の隠れ層を持つ層にグループ化される。通常、隠れ層の各ノードは、前の層と次の層のすべてのノードに接続される。ニューラルネットワークは、その適応性の高さから、実際に広く使用されている。いくつかのタイプのニューラルネットワークが、オントロジーマッチングのさまざまなタスクに使用されている。たとえば、カテゴリ化と分類によって属性間の対応関係を発見したり(Li and Clifton 1994、Esposito et al.2010)、特定のマッチングタスクに関してマッチングシステムを調整するためにマッチャーウェイトなどのマッチングパラメータを学習したりする(Ehrig et al.2005、Mao et al.2010、Gracia et al.2011)。ここでは、上述の最初のタスクに焦点を当て、マッチングパラメータの学習については後節で述べる。
スキーマレベルおよびインスタンスレベルの情報が与えられた場合、データをさらに操作する際の計算の複雑さを軽減するために、この入力をm個のカテゴリーに分類することが有用な場合がある。この目的のために、”自己組織化マップ(SOM)の概要とアルゴリズム及び実装例“で述べている自己組織化マップネットワークとそれに対応する自己組織化学習アルゴリズムを使用することができる(Koho-nen 2001)。自己組織化マップネットワークは,入力層のn個のノードを出力層のm個のカテゴリーに分類する。通常,mは,クラスタの半径を設定することにより,カテゴリをどの程度詳細にすべきかに基づいて事前に定義される。入力パターンや属性(フィールドの長さやデータの種類など)は、n次元の特徴空間における次元と見なされる。ネットワーク内のニューロンは、与えられた入力パターンの特徴に応じて組織化される。これにより、類似した特性を持つニューロンがマップ上の関連する領域に配置される、クラスター化されたニューロン構造が形成される。出力層の各ノードは、クラスターの中心を表している。


ニューラルネットワークでは、マッチングを分類問題として捉える。この目的のために、バックプロパゲーション・アルゴリズムを使用することができる。バックプロパゲーションは、入力パターンを認識し、それに対応するスコアを与えるようにネットワークを訓練するために使用されるスーパーヴィジョン学習アルゴリズムとなる。まず,特徴量の重みが入力ノードに読み込まれ、そして,その重みは,出力を生成するために前方に伝搬される。誤った分類が行われた場合,そのエラーはネットワーク内の接続の重みを変更するために逆伝播される。重みは,出力層の誤差が最小化されなくなるまで変更される。
例 7.20 (ニューラルネットワーク-(Li and Clifton 1994)より引用) あるオントロジーが与えられた場合、Employee.id、Dept.Employee、Payrol.SSNなどの属性は、その入力特性と傾向的な意味が互いに近いため、1つのカテゴリにクラスタリングすることができます。対応するクラスターセンターウェイトのベクトルは以下のようになります。⟨0,0.1,0,…⟩ここで、ベクトル成分は特徴を表し、最初の位置はデータタイプ、2番目の位置は長さなどを表しています。上述の属性をグループ化するための重要な特徴は、フィールドの長さで、その値(0.1)は他の値(0.0)よりも高いからです。実際、IDフィールドは一般的に非常に規則的(常にフルフィールドを使用する)であるのに対し、名前フィールドはより可変的です。
図7.11は、n個の特徴が与えられ、m個のカテゴリーのパターンを認識するための3層ネットワークを示している。隠れ層のノード数は任意である。通常は、最短の学習時間を得るために、実験に基づいて選択されます。
学習段階。ニューラルネットワークの学習データは,クラスタ中心の重みとその対象カテゴリのベクトルで構成される.例えば,先に述べたベクトル,すなわち,⟨0, 0.1, 0, 0, … …は次のようになります.⟩というベクトルには、ターゲットとなるカテゴリーである3番がタグ付けされます。そして,逆伝播アルゴリズムは,これらの属性に対応するat-tributesの特性が,出力ベクトルができるだけ⟨0, 0, 1, 0, … に近くなるように重みを調整します。⟩に限りなく近い出力ベクトルが得られ、最も可能性の高いカテゴリーが3であることを示します。
マッチング段階。マッチングフェーズでは、オントロジーoの特徴でトレーニングされたネットワークに、別のオントロジーo′から、例えば属性health_Plan.Insured#のようなn個の特徴の新しいパターンを入力する。ネットワークの内部分類モデルに基づいて、このパターンとm個のカテゴリーのそれぞれとの類似性を決定します。例えば、この属性は、カテゴリ3(ID番号)にスコア0.92で一致し、カテゴリ1にスコア0.05で一致します。
サポートベクターマシン
サポートベクターマシン(SVM)は、分類や回帰などのタスクに使用される教師付き学習法となる(Cristianini and Shawe-Taylor 2000)。基本的なSVMは、非確率的な二値線形分類器になる。しかし,カーネル関数を利用することで,非線形分類も効率的に行うことができる。これにより、SVMの入力を高次元特徴空間に暗黙のうちに変換またはマッピングし、元々線形非分離であったデータを特徴空間で(おそらく)分離しやすくすることができる(Boser et al. 1992; Vapnik 2000)。SVMはいくつかのマッチングアプローチで分類器として用いられている(Ehrig et al. 2005; Spiliopoulos et al. 2010; Tournaire et al. 2011)。
トレーニングインスタンスは、一致するものと一致しないものの2つのカテゴリに分かれている。SVMはこれらに基づいて,高次元空間,すなわち(w,b)に最大分離超平面を構築する。ここで,wは重みベクトル,bはバイアスを表す。決定関数は f (x) = w × x + b であり、マージンまたは最も近いデータポイント間の距離が最大となる(これはソフト的にも可能であり、すなわちノイズや誤った例を考慮することで可能となる(Cortes and Vapnik 1995))。カーネルを用いた超平面決定関数は以下のように表される。
\[ f(x)=w\times x+b=\displaystyle\sum_{i=1}^ny_i\alpha_iK(x_i,x)+b \]
nは学習例の数、yi∈{+1, -1}は例iの一致・非一致ラベル、Kはカーネル関数である。αiは各学習点のラグランジュ乗数であり,αi≧0,αi yi=0である. 判定境界に近い位置にある学習例(xi )のみがαi>0であり,それを除去すると解が変わってしまうものをサポートベクトルと呼ぶ。
サポート・ベクトル・マシンの例。 2つのオントロジーが与えられたとき、⟨name, title⟩や⟨id, isbn⟩など、マッチングさせるべきエンティティのペアが抽出される。これらのそれぞれについて、SMOA、n-gram、またはWordNetなどを用いた類似性計算により、特徴の選択が行われる。この操作の最終結果は、類似性キューブとして見ることができる。ここで、第1の次元は第1のオントロジーのエンティティを表し、第2の次元は第2のオントロジーのエンティティを表し、第3の次元は適用された特徴を表す。各エンティティ・ペアには、ターゲット値、すなわちマッチまたはノーマッチ・ラベルが追加される。上の例では、両方のエンティティが一致している。これは、通常、ドメイン・エキスパートがトレーニング・データ・セットを準備する際に設定する。つまり、類似性キューブからベクトルを切り出し、それに目標値を与えます。これらの類似性ベクトルは、ベクトル空間を形成し、最大分離超平面を構築するためのトレーニングが行われる。最終的な結果の質を左右するのは、特徴やカーネルの種類の選択となる。マッチング問題に適したカーネル、つまり、無関係な特徴を避けるカーネルを選択すると、結果が向上する。多項式カーネル、ガウス放射基底関数カーネル、文字列カーネル、Bag of wordsカーネルなど、さまざまなカーネルを使用できる。マッチングの段階では,学習したモデルに,エンティティのペアに対応する新たな未知の特徴を与え,SVMによって一致または不一致に分類する。
決定木
決定木分類器は,連続的に適用されるルールのセットを学習し、最終的に判断を下すことができる。
従来の手法は、数値で表現されるため、人間が簡単に解釈できないという欠点があったが、決定木にはこのような欠点はない。あるカテゴリーの決定木を学習する方法としては、分割統治戦略が考えられる。それらを用いると特徴とそのカテゴリで特徴付けられたインスタンスの学習セットTにおいて、母集団を(カテゴリのセットに関して)最もよく識別する特徴f1が選択される。そして、Tは2つの部分集合に分割されたとき、特徴f1に対応する部分集合T yesと、この特徴を持たない部分集合no 1 yes no T1の2つの部分集合に分けられる。
この手順をT1とT1に再帰的に適用する。サブセット内のすべてのインスタンスが同じカテゴリーに割り当てられた場合は停止する。決定木学習器は、実際のカテゴリへの割り当てを葉に持つルールの木を生成する。決定木学習器は、木を大幅に単純化することができれば、インスタンスの一部が誤って分類されていても許容し、受け入れることができる。これは、トレーニングセットにエラーがある場合に有効となる。
決定木は、オントロジーマッチングにおいて、エンティティ間の対応関係の発見(Xu and Embley 2003; Duchateau et al. 2009; Spiliopoulos et al. 2010; Tournaire et al. 2011)や、与えられたマッチングタスクに自動的に適応するためのマッチングシステムのパラメータ(しきい値など)の学習(Ehrig et al. 2005; Duchateau et al. 2008)など、さまざまなタスクに使用されている。ここでは、前者に焦点を当て、マッチングパラメータの学習については後節で述べる。
決定木の例。 下図の2つのオントロジーからのインスタンス間の大きなトレーニングアラインメントが与えられた場合、決定木学習、例えばC4.5決定木誘導システム(Quinlan 1993)を適用して、新しいインスタンスを識別するためのルールを生成する。

下図は、学習可能な決定木の断片を示している。決定はまず、第1のオントロジーから第2のオントロジーへの書籍のマッチングのみが可能であることを示す。次に、著者に教授が1人いる書籍と、著者に教授がいない書籍を区別する。そして、著者が本のトピックである場合、その本は自伝に分類されるべきであり、そうでない場合はエッセイに分類されるべきであると考えることができる。


決定木はある程度の許容範囲を持って作られている。タールゲットカテゴリーの後の数字は、トレーニングセットの中で正しく認識されたインスタンスと誤って認識されたインスタンスの数を示している。
バイナリ決定木の断片。各ノードには,分類するアイテムが満たすべき条件が付けられている。これ以上の分類が不可能な場合は,結果として得られるターゲットカテゴリが,トレーニングセット内で正しく分類されたアイテムと誤って分類されたアイテムの数(括弧内)とともに示される。
上図の決定木は、ソースオントロジーからターゲットオントロジーへのマッピングと書き換えることができる。Autobiographyの枝に対応するマッピングルールは次のように書ける。
Book(e) ∧ ∃e′; author(e, e′) ∧ Professor(e′) ∧ ∃e′; author(e, e′) ∧ topic(e, e′)
⇒ Autobiography(e)
このようなルールは、表現力のある言語ではあるが、対応関係に変換することができる。同様の手法を、インスタンスではなく構造体からの学習に用いることも可能となる。(Xu and Embley 2003)は、決定木を使ってWordNetの用語をマッチングするルールを学習する方法を示している。
マッチャー学習のまとめ
本節では、基本的に分類問題として捉えた基本的なマッチャー学習について述べた。Naive Bayes、kNN、SVM、C4.5など、提示された多くの手法は、データマイニングソフトウェアWeka3(Witten et al.2011)の上に構築することで、マッチングに使用されている。ニューラルネットワーク用のNeu-roph4やサポートベクターマシン用のlibSVM5など、いくつかの特定のフレームワークも、マッチングの目的で利用され、成功を収めている。これらの手法、そのバリエーション、および他の学習手法は、GLUE、CSR、YAM++のマッチングアプローチで詳細に比較されている。
技術的に言えば,学習データセットとテストデータセットを用意して,上記のパッケージのメソッドを直接実行しても,すぐに良い結果が得られることはほとんどない。多くの場合、許容できる結果を得るためには、オーバーフィッティングや適切な手法のパラメータ選択などの問題に対処する必要がある。応用面では、機械学習アプローチは、通常、垂直的なドメイン(セクション1.2参照)で発生するデータ統合シナリオにおいて、新しいオントロジーを既存のオントロジーのプールと照合しなければならない場合に役立つ。そのため、以前に学習したマッチャーを容易に再利用することができる。
次回はオントロジーマッチングのチューニングについて述べる。


AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.


コメント
[…] similarity(類似性)マッチング手法での戦略(4) アライメントのソートのための学習 […]
[…] similarity(類似性)マッチング手法での戦略(4) アライメントのソートのための学習 […]
[…] 次回はアライメントのソートのための学習について述べる。 […]
[…] […]
[…] オントロジーとSVM […]
[…] オントロジーと深層学習 […]
[…] ベイズ学習とオントロジー […]
[…] 決定木とオントロジー […]
[…] 4.similarity(類似性)マッチング手法での戦略(4) アライメントのソートのための学習 […]
[…] 決定木とオントロジー […]