
LoRAによるLLMのファインチューニングの概要
LoRA(Low-Rank Adaptation)は、”大規模言語モデルのファインチューニングとRLHF(Reinforcement Learning from Human Feedback)“でも述べている大規模な事前学習済みモデル(LLM)のファインチューニングに関連する技術で、2021年にMicrosoftに所属していたEdward Huらによって論文「LoRA: Low-Rank Adaptation of Large Language Models」で発表されたものとなる。
LLMのファインチューニングに関しては、2023年末にはChatGPTの新機能である、ユーザーがChatGPTを自由にカスタマイズ(ファインチューニングも)できる「GPTs」がリリースされた。誰もが簡単に学習済みモデルをファインチューニングできるようになりつつある。
LoRAは、元のモデルのパラメータを直接変更する代わりに、低ランクの行列を導入して、事前学習されたモデルの重みを固定し、変換器アーキテクチャの各層に低ランクの分解行列を注入することで、下流のタスク用の訓練可能なパラメータの数を大幅に削減するしくみとなる。
これは例えば、GPT-3 175Bモデルにおいては、LoRAは訓練可能なパラメータを10,000倍減らし、GPUメモリ要件を3倍削減することを実現するものとなる。


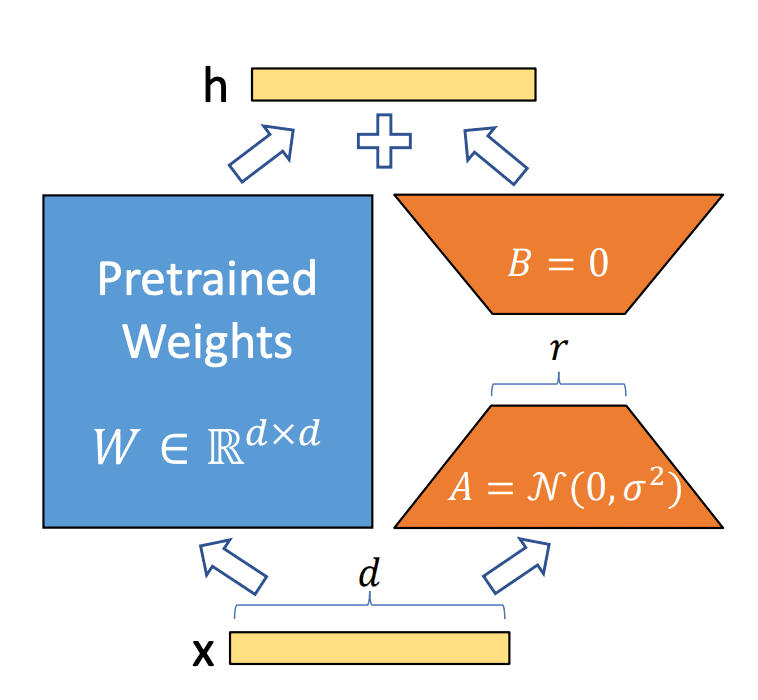
LoRA(Low-Rank Adaptation)の計算例を上図に示す。通常、変換器モデルでは、重み行列W ( m×n)があり、入力x に対してWx の形で適用される。LoRAでは、この重み行列W を直接変更するのではなく、低ランクの行列A (m×k)とB (k×n)を用いて、W ( m×n)+AB ( m×n) の形で変換を行う。ここで、A とB は小さな行列であり、元の重み行列W に比べてはるかに少ないパラメータを持つため、この方法により、全体のパラメータ数が減少し、計算の効率が向上する。 具体的な計算例を以下に示す。


重み行列Wのパラメータ数は合計24、行列AとBは合計8となり調整するパラメータ数が3倍削減されている。
LoRAの活用概要とGoogle Colab
<LoRAの活用概要>
“Huggingfaceを使った文自動生成の概要“で述べているHuggingFaceでは、LoRAやPromptTuning、AdaLoRAなどが実装されているライブラリ:PEFT(Parameter-Efficient Fine-Tuning)が提供されている。
PEFTに関しては、大きく分けて以下の3つのアプローチがある。
- トークン追加型: 入力層に仮想トークンを追加することで、特定のタスクに固有の特徴を学習。事前学習済みモデルのパラメータ自体は更新せず凍結させる。言語理解やテキストの翻訳・要約タスクに対しての適用が可能で画像分類などには適用できない。Huggingfaceでは、Prefix TuningとP TuningとPrompt Tuningの3つのアプローチがすでに実装されている。
- Adapter型: 事前学習済みモデルの外部に特殊なサブモジュールを追加しパラメータを更新。Adapterのパラメータを更新し、元の事前学習済みモデルのパラメータは凍結させる。言語理解やテキストの翻訳・要約タスクに対しての適用が可能。HuggingfaceにおいてPEFTのライブラリーとして取り込まれていない。
- LoRA型: 事前学習済みモデル自体は凍結させ、低ランク行列のみを更新。低ランク行列を更新した上で元の事前学習済みモデルの重みを加算しパラメータを更新する。言語理解やテキストの翻訳・要約タスクだけでなく、画像生成や画像分類のタスクにも適用可能。HuggingfaceのPEFTのライブラリーとしてはLoRAとAda LoRAが実装されている。LoRAは言語タスクのみに留まらず画像タスクに対しても効率的なファインチューニングが可能となっており、非常に応用範囲の広いアプローチとなっている。
以下にPEFTを用いたLoRAのファインチューニングの手順について述べる。
- ベースモデルとなるモデルを用意
- ベースモデルの層の一部をLoRAの層に置換
- LoRAの層以外の層を固定
- LoRA部分のみを学習
<Google Colab>
LLMの計算にはコンピューターリソースが必要であり、コード試行するのに最も簡易なアプローチはGoogle Colabを使うものとなる。Google Colabは、Googleが提供するクラウドベースのJupyterノートブック環境で、Googleのサーバーのリソースを利用して計算を行うことが可能な開発環境となる。利用するにはgoogleのアカウントを持っていれば可能となる。開発環境の設定の手順を以下に示す。
- Googleのアカウントを持った状態でGoogle Colabにアクセスする。
- Google Colabのホームページにアクセスすると、新しいノートブックを作成するためのボタンが表示される。それをクリックするか、メニューから
ファイル->新しいノートブックを選択して、新しいノートブックを作成する。 - 作成したノートブック上部にあるメニューの
ランタイムをクリックし、以下の設定を行う。- ランタイムタイプの変更:
ランタイムのタイプを変更をクリックし、Pythonのバージョンや使用するGPUの設定などを選択する。通常はPython 3を選択する。 - ハードウェアアクセラレータ:
ハードウェアアクセラレータを選択することで、無料で提供されているGPUやTPUを使用できます。一般的には、GPUを選択する。
- ランタイムタイプの変更:
- Google Colabでは、Pythonパッケージをインストールする際に
!を先頭につけることで、シェルコマンドを実行できる。例えば、以下のようにしてライブラリをインストールする。(ctrl-CRか、コード横にある▶️をクリックする)
!pip install pandas
- Google Colabでは、Google Driveとの連携が可能となる。以下のコードを実行することで、Google Driveをマウントできる。
from google.colab import drive
drive.mount('/content/drive')
- コードを実装して実行する。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# データの読み込み
url = 'https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv'
df = pd.read_csv(url)
# データの前処理
df.dropna(inplace=True)
X = df[['Pclass', 'Age', 'SibSp', 'Parch', 'Fare']]
y = df['Survived']
# データの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# モデルの定義と学習
model = LogisticRegression()
model.fit(X_train, y_train)
# テストデータでの予測と評価
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
Google Colabを使ったPEFTによるファインチューニング
“Google Colab で PEFT による大規模言語モデルのファインチューニングを試す“のコードを参照。
パッケージをインストール。
# パッケージのインストール
!pip install -q bitsandbytes datasets accelerate loralib
!pip install -q git+https://github.com/huggingface/transformers.git@main git+https://github.com/huggingface/peft.git
モデルの読み込み。「OPT-6.7B」を読み込む。重みは半精度 (float16)で約13GB、8bitで読み込むと約7GBのメモリが必要になる。
# モデルの読み込み
import os
os.environ["CUDA_VISIBLE_DEVICES"]="0"
import torch
import torch.nn as nn
import bitsandbytes as bnb
from transformers import AutoTokenizer, AutoConfig, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"facebook/opt-6.7b",
load_in_8bit=True,
device_map='auto',
)
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-6.7b")8bitモデルに後処理を適用。学習を有効にするためには、8bitモデルに後処理を適用する必要がある。すべてのレイヤーをフリーズし、レイヤーノルムをfloat32にキャストして安定させ、 同じ理由で、float32の最後のレイヤーの出力もキャストする。
for param in model.parameters():
param.requires_grad = False # モデルをフリーズ
if param.ndim == 1:
# 安定のためにレイヤーノルムをfp32にキャスト
param.data = param.data.to(torch.float32)
model.gradient_checkpointing_enable()
model.enable_input_require_grads()
class CastOutputToFloat(nn.Sequential):
def forward(self, x): return super().forward(x).to(torch.float32)
model.lm_head = CastOutputToFloat(model.lm_head)PeftModelを読み込む。configでLoRAを使用することを指定する。
def print_trainable_parameters(model):
"""
モデル内の学習可能なパラメータ数を出力
"""
trainable_params = 0
all_param = 0
for _, param in model.named_parameters():
all_param += param.numel()
if param.requires_grad:
trainable_params += param.numel()
print(
f"trainable params: {trainable_params} || all params: {all_param} || trainable%: {100 * trainable_params / all_param}"
)
from peft import LoraConfig, get_peft_model
config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, config)
print_trainable_parameters(model)学習の実行。学習データは「Abirate/english_quotes」(偉人の名言集)を使用する。40分ほどかかる。
import transformers
from datasets import load_dataset
data = load_dataset("Abirate/english_quotes")
data = data.map(lambda samples: tokenizer(samples['quote']), batched=True)
trainer = transformers.Trainer(
model=model,
train_dataset=data['train'],
args=transformers.TrainingArguments(
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
warmup_steps=100,
max_steps=200,
learning_rate=2e-4,
fp16=True,
logging_steps=1,
output_dir='outputs'
),
data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False)
)
model.config.use_cache = False # 警告を黙らせる。 推論のために再度有効にすること。
trainer.train()推論の実行。“Two things are infinite: “に続く言葉を推論する。
batch = tokenizer("Two things are infinite: ", return_tensors='pt')
with torch.cuda.amp.autocast():
output_tokens = model.generate(**batch, max_new_tokens=50)
print('\n\n', tokenizer.decode(output_tokens[0], skip_special_tokens=True))参考までに、PEFTのGitHubのページにあるQuick Startは以下のようになる。
pip install peft
ベースモデルとPEFT設定をget_peft_modelでラップして、LoRAのようなPEFTメソッドでトレーニングするモデルを準備する。
from transformers import AutoModelForSeq2SeqLM
from peft import get_peft_config, get_peft_model, LoraConfig, TaskType
model_name_or_path = "bigscience/mt0-large"
tokenizer_name_or_path = "bigscience/mt0-large"
peft_config = LoraConfig(
task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1
)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
"trainable params: 2359296 || all params: 1231940608 || trainable%: 0.19151053100118282"推論のためにPEFTモデルをロードする:
from peft import AutoPeftModelForCausalLM
from transformers import AutoTokenizer
import torch
model = AutoPeftModelForCausalLM.from_pretrained("ybelkada/opt-350m-lora").to("cuda")
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
model.eval()
inputs = tokenizer("Preheat the oven to 350 degrees and place the cookie dough", return_tensors="pt")
outputs = model.generate(input_ids=inputs["input_ids"].to("cuda"), max_new_tokens=50)
print(tokenizer.batch_decode(outputs, skip_special_tokens=True)[0])
"Preheat the oven to 350 degrees and place the cookie dough in the center of the oven. In a large bowl, combine the flour, baking powder, baking soda, salt, and cinnamon. In a separate bowl, combine the egg yolks, sugar, and vanilla."LoRAによるLLMのファインチューニングの適用事例について
LoRAの活用としては、現在は画像系のファインチューニングが活況を呈している。特に”Stable DiffusionとLoRAの活用“でも述べているStable Diffusionとの組み合わせの記事がネット上に多々ある。”LoRA(ローラ)とは|今年注目の画像生成AI (Stable Diffusion) のファインチューニングを試してみた“、”【Stable Diffusion Web UI】追加学習モデルLoRAの使い方“、”LoRAって何?使い方とおすすめLoRAを解説。Stable Diffusion“、以下に適用事例について述べる。
カスタマイズされたチャットボット: 企業はLoRAを使用して、自社のリソースを学習させ大規模なLLMから自社専用のチャットボットを作成することができる。社内独自のQ&Aを行えるチャットボットが使用されている。
AI写真集: LoRAを使用して、基盤モデルとなるStable Diffusionをファインチューニングすることで、「アジア人女性」などの特定の画像を生成できる。 Amazon.co.jpの電子書籍読み放題サービス「Kindle Unlimited」をAI生成画像の「写真集」が席巻している。SNSで話題になり、ニュースサイトも相次いで報じるなど、社会現象といってよい状態だ。生成AIの技術が進化し、実際に存在しないがリアルに見えるモデルの画像が生み出され、グラビア界に新たな波をもたらしている。
AIモデル: 自社ブランドのファッションアイテムを学習させ、AIモデルに着用させることができる。 AI model株式会社は、2022年6月14日にサービス「AI model モデル撮影サービス 」を提供開始した。撮影場所・費用の確保、起用タレント・モデルの不祥事など「人ならでは」のリスクを回避しつつ、ECの顧客に合わせたブランド専属モデルを生み出せる。
参考情報と参考図書
参考図書としては”大規模言語モデル入門“等がある。




AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.

