
ボルツマン分布について
ボルツマン分布(Boltzmann distribution)は、統計力学や物理学において重要な確率分布の一つであり、この分布は、系の状態がどのようにエネルギーに分布するかを記述するものとなる。特に、統計力学では、この分布が系のエネルギー状態の確率分布を決定するために使用されている。
ボルツマン分布は、ルートヴィッヒ・ボルツマンにちなんで名付けられ、一般的に、エネルギー \(E_i\) を持つ状態 \(i\) の確率 \(P_i\) は以下のように表されるものとなる。
\[ P_i = \frac{e^{-\beta E_i}}{Z} \]
ここで、\(e\) は自然対数の底であり、\(\beta\) は逆温度(\(1/kT\)、\(k\) はボルツマン定数、\(T\) は絶対温度)、\(Z\) は分配関数(partition function)と呼ばれる。
\[ Z = \sum_{i} e^{-\beta E_i} \]
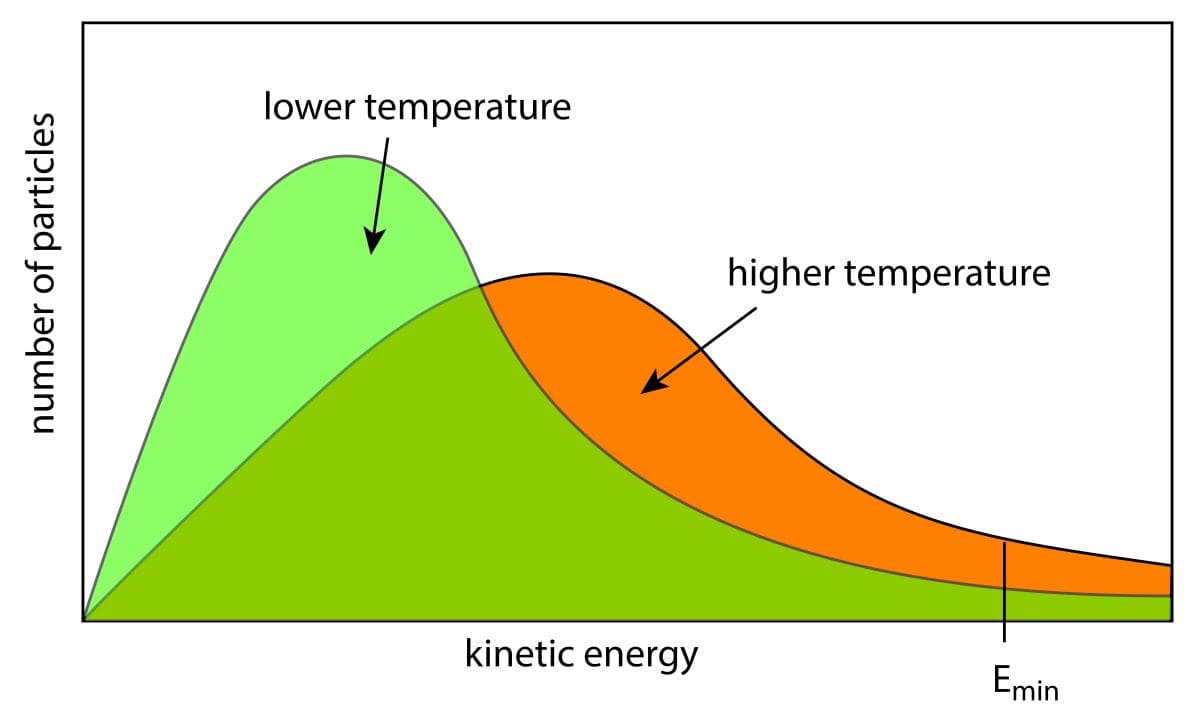
この分布は、系が平衡状態にあるとき、各エネルギー状態 \(E_i\) に系がある確率を表し、ボルツマン分布から分かるように、系は低エネルギー状態により高い確率で存在し、高エネルギー状態にはより低い確率で存在する傾向がある。


ボルツマン分布は、物質の熱力学的性質や物質の状態、相転移などの理解に不可欠なツールであり、例えば、固体や液体、気体の内部のエネルギー状態の確率分布を知りたい場合にボルツマン分布が使われている。
また、ボルツマン分布は機械学習や最適化アルゴリズムにも応用されていおり、例えば、シミュレーテッドアニーリング(simulated annealing)という最適化手法では、ボルツマン分布を使用して最適な解を探索している。以下に、機械学習でのボルツマン分布の役割について述べる。
ボルツマン分布と機械学習や最適化アルゴリズムとの関係
ボルツマン分布は、機械学習や最適化アルゴリズムにおいて重要な役割を果たす確率分布の一つであり、特に、確率的なアプローチやモンテカルロ法に基づく手法で以下のような広い範囲で利用されている。
1. モデルの学習と確率的アプローチ:
機械学習では、モデルの学習においてデータやパラメータの確率的な扱いが一般的であり、例えば、“確率的勾配降下法(Stochastic Gradient Descent, SGD)の概要とアルゴリズム及び実装例について“で述べている確率的勾配降下法(Stochastic Gradient Descent, SGD)は、最適化アルゴリズムの一種で、モデルのパラメータを更新する際にランダムなサンプルを用いて勾配を推定している。ボルツマン分布は、確率的なアプローチに基づく学習手法で重要な役割を果たし、例えば、ボルツマン分布に従う確率的な変数を用いたモデルや、”グラフィカルモデルの具体例“でも述べているボルツマンマシンと呼ばれるモデルがある。これらのモデルは、確率的な学習アルゴリズムを用いてパラメータを学習し、データのパターンを捉えることができる。


2. モンテカルロ法:
ボルツマン分布は、モンテカルロ法(Monte Carlo methods)においても重要な役割を果たしている。モンテカルロ法は、確率的なサンプリングを用いて積分や最適化問題の解を求める手法であり、例えば、ボルツマン分布に基づくサンプリング手法として、”マルコフ連鎖モンテカルロ法の概要と実装について“で述べているマルコフ連鎖モンテカルロ法(Markov Chain Monte Carlo, MCMC)がある。MCMCは、ボルツマン分布に従うサンプルを生成することで、確率分布の特性を調べたり、最適化問題を解決したりするのに使用されている。
3. シミュレーテッドアニーリング:
ボルツマン分布は、シミュレーテッドアニーリング(Simulated Annealing)という最適化手法にも使用されている。シミュレーテッドアニーリングは、物理的なアニーリング(金属を加熱し徐々に冷却することで結晶を整えるプロセス)を模倣した手法で、最適化問題を解決するのに用いられるものとなる。この手法では、ボルツマン分布を利用して、探索空間内の状態遷移の確率を定義し、シミュレーテッドアニーリングは、初期温度を設定し、その温度を徐々に下げながらボルツマン分布に基づいた確率的な探索を行い、最適解を探索している。
4. エネルギー最小化:
ボルツマン分布は、エネルギー最小化の問題においても役てられている。例えば、エネルギーが系の状態に対応し、ボルツマン分布が系の状態の確率を与えると考えることができ、そのため、最も確率が高い状態、つまりエネルギーが最小の状態を見つけることができる。
ソフトマックスアルゴリズムについて
“ソフトマックス関数の概要と関連アルゴリズム及び実装例について“でも述べているソフトマックスアルゴリズム(Softmax Algorithm)は、多クラス分類問題において、クラスの確率分布を計算するためのアルゴリズムで、主に機械学習やニューラルネットワークの分野で広く使用されているものとなる。
多クラス分類問題では、与えられた入力データがどのクラスに属するかを予測する必要があり、ソフトマックスアルゴリズムは、ニューラルネットワークの出力層でよく使用され、各クラスに対する確率分布を得るために使われている。
また、このアルゴリズムでは、温度パラメータと呼ばれるパラメータが重要な役割を果たしており、温度パラメータは、ソフトマックス関数の挙動を制御するために使用されている。
それらを考えるために、まず、ソフトマックス関数を振り返える。\(K\) 個の異なる値 \(z_1, z_2, …, z_K\) に対するソフトマックス関数は次のように定義される。
\[ \text{Softmax}(z_i) = \frac{e^{z_i}}{\sum_{j=1}^{K} e^{z_j}} \]
ここで、\(e\) はネイピア数(自然対数の底)であり、\(z_i\) は入力の \(i\) 番目の成分となる。この関数は、入力の指数関数を計算し、それをすべての入力の指数関数の合計で割ることで、各入力の確率分布を計算している。このとき、\(z_i\) は各クラス \(i\) に属する「エネルギー」と考えることができる。
この関数に、温度パラメータ \(T\) を導入すると、ソフトマックス関数は次のように変形できる。
\[ \text{Softmax}(z_i) = \frac{e^{z_i/T}}{\sum_{j=1}^{K} e^{z_j/T}} \]
この式では、\(z_i\) を \(T\) で割った値に変換しており、温度パラメータ \(T\) は、ソフトマックス関数の出力に影響を与え、確率分布の「平らさ」を調整するものとなる。
このような形に変形すると、ソフトマックスアルゴリズムは、前述のボルツマン分布の一般化と見なすことができ、前述のようにボルツマン分布が適用されいた機械学習のアプローチにソフトマックスアルゴリズムを適用することがてできる。
ここでは、バンディット問題への適用について以下に詳しく述べる。
バンディット問題とソフトマックスアルゴリズム
バンディット問題(Multi-armed Bandit Problem)は、探索と活用のトレードオフを扱う典型的な問題で、複数の選択肢(バンディットアーム)があり、各選択肢の報酬分布は未知であるとき、どの選択肢を選択するかを決定することで、最終的に最も高い報酬を得ることが目標の課題を解くアプローチとなる。
ソフトマックスアルゴリズムは、このバンディット問題の解決に使用される。ソフトマックスアルゴリズムを用いることで、各バンディットアームの期待報酬に基づいて選択確率を計算し、確率的にバンディットアームを選択することが可能となる。具体的な手順を以下に示す。
1. 各アームの価値の推定: 各バンディットアーム \(i\) の期待報酬(または価値)を推定する。これを \(Q_i\) とする。
2. ソフトマックス関数による選択確率の計算: 各アーム \(i\) の選択確率 \(p_i\) を次のように計算する。
\[ p_i = \frac{e^{Q_i / \tau}}{\sum_{j=1}^{k} e^{Q_j / \tau}} \]
ここで、\(\tau\) は温度パラメータであり、温度が高いほど、選択確率は均一に近づき、温度が低いほど、価値の高いアームが選択される確率が高くなる。
3. アームの選択: 計算された選択確率に基づいて、確率的にバンディットアーム \(i\) を選択する。
4. 報酬の取得: 選択されたバンディットアームから報酬 \(r\) を受け取る。
5. 価値の更新: 選択されたアーム \(i\) の価値 \(Q_i\) を更新する。報酬 \(r\) を用いて、次のように更新する
\[ Q_i \leftarrow Q_i + \alpha (r – Q_i) \]
ここで、\(\alpha\) は学習率で、新しい情報にどれだけ影響を受けるかを調整するものとなる。
6. 繰り返し: 2.から5.のステップを繰り返し、報酬を最大化するようなアームの選択を行う。
ソフトマックスアルゴリズムにおける温度パラメータ \(\tau\) は、探索と活用のバランスを調整するために使用され、温度が高い場合 (\(\tau\) が大きい場合)は、すべての選択肢がほぼ等しい確率で選択されるため、探索が促進され、新しい情報を獲得するための探索が優先される。また温度が低い場合 (\(\tau\) が小さい場合)は、価値の高い選択肢が高い確率で選択されるため、活用が促進され、既知の情報を活用し、報酬の最大化を目指すものとなる。
このように、ソフトマックスアルゴリズムを用いることで、温度パラメータの設定により、探索と活用の間のバランスを調整し、最適な解の発見を支援することができる。実際には、探索の初期段階では温度を上げ探索を促進し、探索が進んだ時点で温度を下げ活用を促進するように調整される。
ソフトマックスアルゴリズムをバンディット問題に適用した実装例について
以下は、Pythonを使用してソフトマックスアルゴリズムをバンディット問題に適用した簡単な実装例となる。
import numpy as np
class SoftmaxBandit:
def __init__(self, num_actions, temperature):
self.num_actions = num_actions
self.temperature = temperature
self.action_values = np.zeros(num_actions)
self.action_counts = np.zeros(num_actions)
self.total_reward = 0
def softmax(self, action_values):
exp_values = np.exp(action_values / self.temperature)
return exp_values / np.sum(exp_values)
def select_action(self):
probabilities = self.softmax(self.action_values)
action = np.random.choice(self.num_actions, p=probabilities)
return action
def update(self, action, reward):
self.total_reward += reward
self.action_counts[action] += 1
self.action_values[action] += (reward - self.action_values[action]) / self.action_counts[action]
# バンディット問題のシミュレーション
def bandit_simulation(num_actions, num_steps, temperature):
bandit = SoftmaxBandit(num_actions, temperature)
rewards = []
for _ in range(num_steps):
action = bandit.select_action()
# 仮の報酬を設定(ここではランダムな報酬とする)
reward = np.random.normal(loc=0, scale=1)
bandit.update(action, reward)
rewards.append(reward)
return rewards
# シミュレーションの実行
num_actions = 5 # アームの数
num_steps = 1000 # ステップ数
temperature = 0.5 # ソフトマックスの温度パラメータ
rewards = bandit_simulation(num_actions, num_steps, temperature)
print("Total reward:", sum(rewards))このコードでは、SoftmaxBanditクラスがソフトマックスアルゴリズムを実装し、select_actionメソッドでソフトマックス関数によりアクションが選択され、updateメソッドで報酬を元にアームの価値を更新している。bandit_simulation関数はバンディット問題のシミュレーションを行い、指定されたステップ数の報酬の合計を返す。このコードを実行すると、指定されたステップ数の間に得られる報酬の合計が表示される。
ソフトマックスアルゴリズムをバンディット問題に適用した場合の課題と対応策について
ソフトマックスアルゴリズムをバンディット問題に適用する際には、様々な課題があり、それに対処するための対応策がある。以下にそれらについて述べる。
1. 温度パラメータの選択:
課題: ソフトマックス関数には温度パラメータがあり、これがアクションの選択に与える影響を制御している。適切な温度パラメータの選択は重要であり、これがアルゴリズムの性能に影響を与える。温度が高すぎると、アクション間の選択確率がほぼ一様になり、温度が低すぎると、最も報酬の高いアクションがほぼ常に選択される。
対策: 温度パラメータの初期値を設定し、実験やシミュレーションを通じて最適な値を見つけるか、温度を動的に調整する方法を採用することが考えられる。
2. 探索と活用のバランス:
課題: バンディット問題では、探索(新しいアクションを試すこと)と活用(過去の経験に基づいて報酬の高いアクションを選択すること)のバランスが重要となる。ソフトマックスアルゴリズムは確率的な方法で探索を行うが、過剰な探索は報酬の最大化を妨げる可能性がある。
対策: “ε-グリーディ法(ε-greedy)の概要とアルゴリズム及び実装例について“で述べているε-greedy法や”UCB(Upper Confidence Bound)アルゴリズムの概要と実装例“で述べているUCB法など、他の探索方法と組み合わせることでバランスを取ることができる。例えば、初期段階では高い探索率を設定し、徐々に探索率を減少させる方法がある。
3. 局所最適解への収束:
課題: ソフトマックスアルゴリズムは確率的であり、選択されたアクションが最適でない場合でも、一定の確率で他のアクションを選択することがある。これにより、局所最適解に収束する可能性がある。
対策: 温度パラメータを調整したり、動的な探索手法を導入することで、局所最適解への収束を回避することができる。また、複数のアルゴリズムを組み合わせて利用することも有効となる。
参考情報と参考図書
バンディット問題に対する詳細は”バンディット問題の理論とアルゴリズム“に述べている。そちらも参照のこと。
ウェブ上の情報としては”Netflixも使っている!Contextual Banditアルゴリズムを徹底解説“、”Contextual Bandit LinUCB LinTS“、”バンディットアルゴリズムを用いた推薦システムの構成について“、”Contextual Bandit を用いた賃貸物件検索システム“等がある。
参考図書としては”バンディット問題の理論とアルゴリズム“


“Bandit problems: Sequential Allocation of Experiments“.


“Regret Analysis of Stochastic and Nonstochastic Multi-armed Bandit Problems“






AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.


コメント
[…] “ε-グリーディ法(ε-greedy)の概要とアルゴリズム及び実装例について“で述べているε-greedy法や”ボルツマン分布とソフトマックスアルゴリズム及びバンディット問題“で述べているソフトマックスアルゴリズムでは、腕の探索は確率的に行われ、そのときにアルゴリズムが注目するのは”腕から得られた報酬がいくらか”となる。 […]
[…] ボルツマン分布とソフトマックスアルゴリズム及びバンディット問題 […]