
イントロダクション
大規模言語モデルのファインチューニングとは、事前に大規模なデータセットで訓練されたモデルに対して、追加の学習を行うもので、汎用性の高いモデルを特定のタスクやドメインに適用することを可能にし、精度やパフォーマンスの向上を実現させることを目的としたものとなる。これは、以下のような特徴を持つ。
1. タスク固有のデータでの学習: 大規模言語モデルは一般的な言語理解に対して訓練されているが、特定のタスクに直接適用する際には、タスク固有のデータで再学習(ファインチューニング)する必要がある。例えば、感情分析、質問応答、テキスト生成などのタスクにおいて、これらのモデルをファインチューニングすることで、タスクの特徴に適応したモデルを作ることが可能となる。
2. タスク特定の性能向上: ファインチューニングにより、特定のタスクにおいて大規模言語モデルの性能を向上させることができる。例えば、医療文書の分類、金融情報の要約、法律文書の要約など、特定のドメインや業界において、大規模言語モデルをファインチューニングすることで、そのタスクにおける精度や効率を改善できる。
3. 小規模データセットの効果的な利用: 多くの場合、特定のタスクやドメインに関連するデータは限られている。このような場合でも、大規模言語モデルをファインチューニングすることで、少ないデータで効果的なモデルを構築可能となる。大規模モデルは、一般的な言語理解に関する知識を持っているため、少量のタスク固有データでも高い性能を発揮する。
4. ドメイン適応: 企業や研究機関は、独自のデータやドメインに特化したニーズを持っており、大規模言語モデルをファインチューニングすることで、その特定のドメインに適応したモデルを簡単に作成することが可能となる。例えば、医療、法律、金融など、さまざまな業界や分野に特化した言語モデルを作成することができる。
5. ラベル付きデータの利用: 大規模言語モデルのファインチューニングは、ラベル付きデータの効果的な利用を可能にする。ラベル付きデータは一般に入手が難しいが、大規模言語モデルを使えば、ラベルなしデータから自動的にラベル付きデータを生成し、それを使ってモデルをファインチューニングすることができる。
6. リソース効率の向上: 大規模言語モデルの事前学習には、膨大な計算リソースが必要だが、ファインチューニングには比較的少ないリソースで十分で、そのため、事前学習済みのモデルをファインチューニングすることで、リソースを節約しつつ高性能なモデルを作成可能となる。
Kerasを用いたCNNのファインチューニング
深層学習では、”PythonとKerasによるコンピュータービジョンのためのディープラーニング(3) 学習済みモデルを利用したのCNNの改善“でも述べているように、学習済みのモデルをファインチューニングすることはしばしば行われる。以下にKerasを用いたCNNでのファインチューニングの実装例について述べる。
import tensorflow as tf
from tensorflow.keras.applications import VGG16
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.layers import Dense, Dropout, Flatten
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
# ファインチューニングするクラス数
num_classes = 10
# 画像のサイズ
img_rows, img_cols = 224, 224
# 学習率
learning_rate = 0.0001
# 事前学習済みのVGG16モデルの読み込み
base_model = VGG16(weights='imagenet', include_top=False, input_shape=(img_rows, img_cols, 3))
# VGG16モデルの最後の層を取得
x = base_model.output
x = Flatten()(x)
# 新しい全結合層を追加
x = Dense(512, activation='relu')(x)
x = Dropout(0.5)(x)
# 新しい全結合層を追加(出力の数はクラス数に対応)
predictions = Dense(num_classes, activation='softmax')(x)
# 新しいモデルを作成(既存のVGG16モデルに新しい層を追加)
model = Model(inputs=base_model.input, outputs=predictions)
# 既存のVGG16の層は再学習しないようにする
for layer in base_model.layers:
layer.trainable = False
# モデルのコンパイル
model.compile(optimizer=Adam(lr=learning_rate), loss='categorical_crossentropy', metrics=['accuracy'])
# データ拡張の設定
train_datagen = ImageDataGenerator(
rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True
)
test_datagen = ImageDataGenerator(rescale=1./255)
# 訓練データとテストデータのディレクトリ
train_dir = 'path_to_training_data_directory'
test_dir = 'path_to_test_data_directory'
# 訓練データの生成
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(img_rows, img_cols),
batch_size=32,
class_mode='categorical'
)
# テストデータの生成
test_generator = test_datagen.flow_from_directory(
test_dir,
target_size=(img_rows, img_cols),
batch_size=32,
class_mode='categorical'
)
# モデルの学習
history = model.fit(
train_generator,
steps_per_epoch=len(train_generator),
epochs=10,
validation_data=test_generator,
validation_steps=len(test_generator)
)この例では、CNNでのKerasを用いたVGG16モデルをファインチューニングして新しいデータセットに適用する方法について述べている。
HuggingFaceを用いたTransformerモデルのファインチューニング
Transformerモデルをファインチューニングする場合、通常は“Huggingfaceを使った文自動生成の概要“でも述べているHugging FaceのTransformersライブラリを使用する。ここでは、Hugging Face Transformersライブラリを使って、事前学習済みのTransformerモデル(例えば、BERT、RoBERTaなど)をファインチューニングする例を示す。
import torch
from transformers import BertTokenizer, BertForSequenceClassification
from torch.utils.data import DataLoader
from transformers import AdamW
from transformers import get_linear_schedule_with_warmup
from tqdm import tqdm次に、ファインチューニングのための設定を行う。
# デバイスの設定(GPUが利用可能な場合はGPUを使用)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# パラメータ
MAX_LEN = 128
BATCH_SIZE = 16
EPOCHS = 3
LEARNING_RATE = 2e-5
# データセットのパス
train_data_path = "path_to_train_dataset"
val_data_path = "path_to_validation_dataset"
# 事前学習済みのBERTモデルとトークナイザーを読み込む
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# モデルをデバイスに移動
model.to(device)
# データセットの読み込みとトークン化
class CustomDataset(torch.utils.data.Dataset):
def __init__(self, tokenizer, data_path):
self.tokenizer = tokenizer
self.data = []
with open(data_path, 'r') as f:
for line in f:
text, label = line.strip().split('\t')
self.data.append((text, int(label)))
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
text, label = self.data[idx]
inputs = self.tokenizer.encode_plus(
text,
None,
add_special_tokens=True,
max_length=MAX_LEN,
pad_to_max_length=True,
return_token_type_ids=True,
truncation=True
)
return {
'input_ids': torch.tensor(inputs['input_ids'], dtype=torch.long),
'attention_mask': torch.tensor(inputs['attention_mask'], dtype=torch.long),
'token_type_ids': torch.tensor(inputs["token_type_ids"], dtype=torch.long),
'labels': torch.tensor(label, dtype=torch.long)
}
# データセットを作成
train_dataset = CustomDataset(tokenizer, train_data_path)
val_dataset = CustomDataset(tokenizer, val_data_path)
# DataLoaderを作成
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=BATCH_SIZE, shuffle=False)
# オプティマイザーとスケジューラーの設定
optimizer = AdamW(model.parameters(), lr=LEARNING_RATE, eps=1e-8)
total_steps = len(train_loader) * EPOCHS
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=0, num_training_steps=total_steps)最後に、ファインチューニングのループを実行する。
# ファインチューニングのループ
for epoch in range(EPOCHS):
model.train()
train_loss = 0.0
for batch in tqdm(train_loader, desc=f"Epoch {epoch + 1}/{EPOCHS}"):
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
token_type_ids = batch['token_type_ids'].to(device)
labels = batch['labels'].to(device)
model.zero_grad()
outputs = model(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
labels=labels)
loss = outputs.loss
train_loss += loss.item()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
scheduler.step()
# バリデーションの評価
model.eval()
val_loss = 0.0
val_corrects = 0
val_total = 0
with torch.no_grad():
for batch in tqdm(val_loader, desc=f"Validating Epoch {epoch + 1}/{EPOCHS}"):
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
token_type_ids = batch['token_type_ids'].to(device)
labels = batch['labels'].to(device)
outputs = model(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
labels=labels)
loss = outputs.loss
val_loss += loss.item()
_, preds = torch.max(outputs.logits, 1)
val_corrects += torch.sum(preds == labels).item()
val_total += labels.size(0)
train_loss /= len(train_loader)
val_loss /= len(val_loader)
val_acc = val_corrects / val_total
print(f"Epoch {epoch + 1}/{EPOCHS}, Train Loss: {train_loss}, Val Loss: {val_loss}, Val Acc: {val_acc}")この例では、BERTモデルを文の二値分類タスクに適用している。
RLHF(Reinforcement Learning from Human Feedback)について
RLHF(Reinforcement Learning from Human Feedback)は、人間からのフィードバックを利用して”様々な強化学習技術の理論とアルゴリズムとpythonによる実装“でも述べている強化学習エージェントを訓練するための手法となる。
具体的には、後述する指示チューニング済みモデルが実際に生成したテキストに対して人間の好みを反映した報酬をスカラー値で付与し、この報酬を最大化するように指示チューニングモデルのファインチューニングをするものとなる。
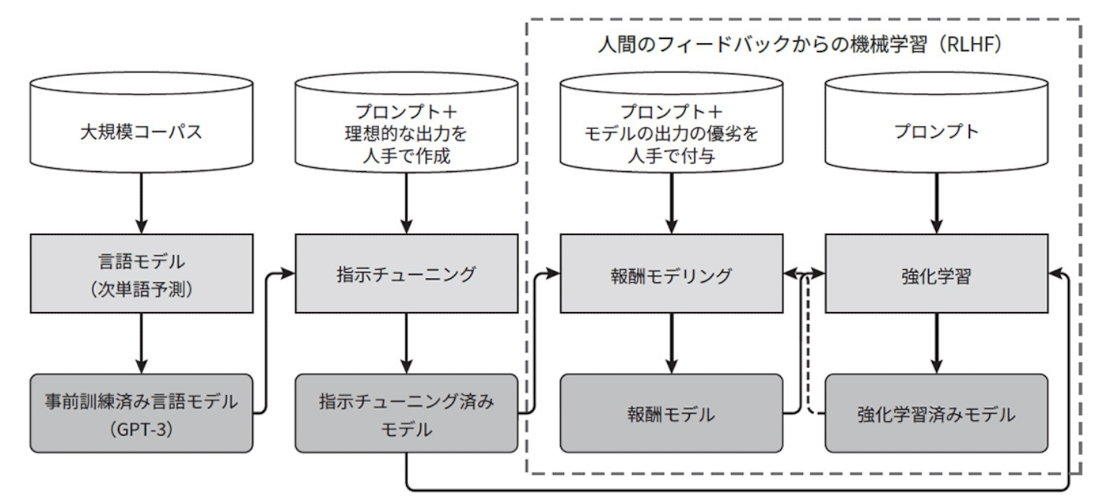
具体的な構成としては、下図に示すようなものとなる。”RLHF: Reinforcement Learning from Human Feedback“より。


上図の波線で示している部分がRLHFで繰り返して行う部分となる。
このようにRLHFでは人間の割り当てた報酬をそのまま使って学習するのではなく、報酬を予測するモデルを学習するものとなり、このようなモデルは報酬モデリング(reward modeling)と呼ばれる。
ここでのステップは、まずプロンプトとテキストの組にら対して人手で優越のラベル付けを付与したデータセットを構築する。次に、このデータセットを使って任意のプロンプトとテキストに対して報酬をスカラー値で予測する報酬モデルを学習する。
このアプローチで重要なものは、データセットの作成方法で、最も単純なものは、人間がテキストに対してスカラー値を直接付与する方法だが、複数人で作業した場合に作業者の間でのスケールを揃えることが難しく、ノイズが大きくなるため、一つのプロンプトに対して複数のテキストを生成し、それらを順位づけすることでデータセットを作成するアプローチを取る。
例えばあるプロンプトに対して、K=4からK=9個のテキストを生成して、順位づけし、損失関数としてシグモイド関数のようなものを使って、好ましいものとそうでないもののスコアの差を大きくし、それらに強化学習を行う。さらに、強化学習を行う際に、過学習を防ぐために正則化の制約をかけ、特定のモデルに偏ることを防いでいる。
このような強化学習のアプローチではさまざまなアプローチが行われているが、方策勾配法として”REINFORCE (Monte Carlo Policy Gradient)の概要とアルゴリズム及び実装例について“で述べているREINFORCE(モンテカルロ勾配法(Monte-Carlo Plocy gradient))や、”Proximal Policy Optimization (PPO)の概要とアルゴリズム及び実装例について“で述べているPPO(proximal policy optimization)などが用いられている。
RLHFは、特に、教育、医療、ロボット工学、デジタルアシスタントなどの領域で有用性が高いと考えられており、人間の知識やフィードバックを効果的に取り入れることで、エージェントのパフォーマンスや学習速度を向上させることができ、実世界の複雑な環境においてもより柔軟で効果的な行動を取ることができるようになる。
RLHF(Reinforcement Learning from Human Feedback)の実装例
RLHF(Reinforcement Learning from Human Feedback)の実装例として、人間からのフィードバックに基づいてエージェントを訓練する方法を示す。ここでは、”Q-学習の概要とアルゴリズム及び実装例について“で述べているQ学習(Q-Learning)を用いたシンプルな状況でのRLHFの例となる。
import numpy as np
# エージェントの状態数と行動数
num_states = 5
num_actions = 2
# Qテーブルの初期化
Q_table = np.zeros((num_states, num_actions))
# フィードバックに基づいてQ値を更新する関数
def update_Q(state, action, feedback, alpha):
if feedback > 0:
Q_table[state, action] += alpha * feedback
# エージェントの学習と行動選択
def agent_action(state):
# エージェントの行動選択(例:ε-greedy法)
epsilon = 0.2
if np.random.rand() < epsilon:
action = np.random.randint(num_actions)
else:
action = np.argmax(Q_table[state])
return action
# エピソードごとの学習とフィードバックを受け取りながらの更新
def train_agent(num_episodes):
alpha = 0.1 # 学習率
for episode in range(num_episodes):
# エージェントの初期状態設定
state = np.random.randint(num_states)
# エージェントの行動選択
action = agent_action(state)
# 人間からのフィードバックをシミュレート(例:1は正解、-1は不正解)
feedback = np.random.choice([1, -1])
# Q値の更新
update_Q(state, action, feedback, alpha)
# 学習の進捗を出力
print(f"Episode {episode + 1}/{num_episodes}, State: {state}, Action: {action}, Feedback: {feedback}")
# エージェントの学習を実行
train_agent(num_episodes=10)
この例では、状態数が5、行動数が2の単純な状況でのものとなる。エージェントはQ学習を用いて学習し、各状態で人間からのフィードバックに基づいてQ値を更新している。
実際には、このような簡単な例ではなく、現実の問題にRLHFを適用する際には、次のような工夫が必要となる。
- フィードバックの取得: 実際のアプリケーションでは、人間からのフィードバックを取得する方法が重要で、例えば、ユーザーインターフェースを介してユーザーにフィードバックを求めることがある。
- エージェントの状態と行動: 実際の問題に合わせて適切な状態と行動を定義する必要があり、また、状態や行動の表現方法も重要となる。
- エージェントの学習アルゴリズム: Q学習以外にも、強化学習アルゴリズムやその他の機械学習アルゴリズムを使用することがある。タスクの性質や問題設定に合わせて適切なアルゴリズムを選択する。
- ハイパーパラメータの調整: 学習率やε-greedy法のεなどのハイパーパラメータを適切に調整する必要がある。
- 実世界の応用: RLHFを実際の問題に適用する際には、セキュリティ、プライバシー、倫理などの側面も考慮する必要がある。
その他のファインチューニングの手法
その他のファインチューニングの手法としては、指示チューニング(instruction tuning)という手法がある。これは、指示を含んだプロンプトと理想的な出力テキストの組で構成されるデータセットを使ったファインチューニングで、例えば2021年にGoogleが提案したFLAN(Finetuned Language Net)の論文”Finetuned Language Models Are Zero-Shot Learners“では、GPT3と同等規模の1370億パラメータの大規模モデルを62個のデータセットを集約してファインチューニングした結果、多数のタスクでのzero-shot学習の性能がGPT3を上回ったことが報告されている。
ここでは、以下のようなテンプレートを使って、さまざまなタスクのデータセットをプロンプトと出力テキストの組で構成される指示チューニングのデータセット形式に変換する。


ただし、指示チューニングでは、(1)大規模で高品質なデータセットを作ることが難しい、(2)モデルの出力に対してフィードバックを行えない等の課題がある。
“LoRAによるLLMのファインチューニングの概要と実装例について“でものべているように、モデルを圧縮してファインチューニングする手法も近年多く提案されている。それらは大きく分けて以下の3つのアプローチとなる。
- トークン追加型: 入力層に仮想トークンを追加することで、特定のタスクに固有の特徴を学習。事前学習済みモデルのパラメータ自体は更新せず凍結させる。言語理解やテキストの翻訳・要約タスクに対しての適用が可能で画像分類などには適用できない。Huggingfaceでは、Prefix TuningとP TuningとPrompt Tuningの3つのアプローチがすでに実装されている。
- Adapter型: 事前学習済みモデルの外部に特殊なサブモジュールを追加しパラメータを更新。Adapterのパラメータを更新し、元の事前学習済みモデルのパラメータは凍結させる。言語理解やテキストの翻訳・要約タスクに対しての適用が可能。HuggingfaceにおいてPEFTのライブラリーとして取り込まれていない。
- LoRA型: 事前学習済みモデル自体は凍結させ、低ランク行列のみを更新。低ランク行列を更新した上で元の事前学習済みモデルの重みを加算しパラメータを更新する。言語理解やテキストの翻訳・要約タスクだけでなく、画像生成や画像分類のタスクにも適用可能。HuggingfaceのPEFTのライブラリーとしてはLoRAとAda LoRAが実装されている。LoRAは言語タスクのみに留まらず画像タスクに対しても効率的なファインチューニングが可能となっており、非常に応用範囲の広いアプローチとなっている。
参考情報と参考図書
参考図書としては”大規模言語モデル入門“等がある。




AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.


コメント
[…] 大規模言語モデルのファインチューニングとRLHF(Reinforcement Learning from Human Feedback) […]