
RDF Technology Overview
RDF (Resource Description Framework) is a technical framework for the metadata of resources on the Web, which was standardized by W3C in February 1992, as mentioned in LOD.
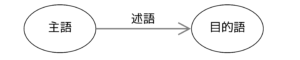
The structure of RDF is based on the triple data model. RDF is based on the triple data model, which expresses relational information about resources using three elements: subject, predicate, and object. (The figure below shows a graphical representation of these elements.)

Of these, the subject refers to the resource to be described, and the identification of the resource is based on the Uniform Resource Identifier (URI), which is an extension of the Uniform Resource Locator (URL) and guarantees a single ID.
The predicate indicates the characteristics of the subject or the relationship between the subject and the object, and the object indicates something related to the subject or, if the predicate is a characteristic, the value of the characteristic.
RDF itself is only a framework and an abstract definition, and various data formats are defined as actual data syntax. Each of them is shown below with examples.
The first one is RDF/XML
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:dc="http://purl.org/dc/elements/1.1/"> <rdf:Description rdf:about="https://en.wikipedia.org/wiki/Tony_Benn"> <dc:title>Tony Benn</dc:title> <dc:publisher>Wikipedia</dc:publisher> </rdf:Description> </rdf:RDF>
Then N-triple
<http://example.org/#spiderman>
<http://www.perceive.net/schemas/relationship/enemyOf>
<http://example.org/#green-goblin> .Notation3
@prefix dc: <http://purl.org/dc/elements/1.1/>. <https://en.wikipedia.org/wiki/Tony_Benn> dc:title "Tony Benn"; dc:publisher "Wikipedia".
TTL
@base <http://example.org/> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
@prefix rel: <http://www.perceive.net/schemas/relationship/> .
<#green-goblin>
rel:enemyOf <#spiderman> ;
a foaf:Person ; # マーベル・ユニバースのコンテキストで
foaf:name "Green Goblin" .
<#spiderman>
rel:enemyOf <#green-goblin> ;
a foaf:Person ;
foaf:name "Spiderman", "Человек-паук"@ru .
JSON-LD
{
"@context": "https://json-ld.org/contexts/person.jsonld",
"@id": "http://dbpedia.org/resource/John_Lennon",
"name": "John Lennon",
"born": "1940-10-09",
"spouse": "http://dbpedia.org/resource/Cynthia_Lennon"
}
For data that is easy for humans to understand, there is the option of using TTL, or JASON-LD if you want to think in terms of affinity with web applications.
Furthermore, ontology can be said to be a model of concepts in a snapshot of a certain moment, and time changes of concepts are not considered very much, but there are many cases where time changes must be considered for data in the real world. (For example, when using an ontology as lexical data, we want to process across past and current dictionaries.
The simplest way to deal with this is to use the triple structure as it is, with the name sapce part representing a different time axis. This approach makes it possible to handle a certain amount of time axis information (e.g., version changes in a dictionary), but makes it difficult to handle complex time changes.
On the other hand, for example, in N-triple, it is possible to add a fourth element, as shown below.
<http://example.org/bob#me> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://xmlns.com/foaf/0.1/Person> <http://example.org/bob> . <http://example.org/bob#me> <http://xmlns.com/foaf/0.1/knows> <http://example.org/alice#me> <http://example.org/bob> .
Here, the first line is the data corresponding to the aforementioned namespace. This structure allows for a more flexible representation of the model of the passage of time, since the data are independent nodes, compared to the handling of namespaces in triples.
In the next article, we will discuss the RDF store, the database that actually handles this RDF data, and SPARQL, the query system that runs on it.


コメント