
本ブログは、 DEUS EX MACHINA- “機械仕掛けの神の創り方に述べている通り、人工知能システムをゼロから作り上げる為に必要な情報を集めている。さらにそれらの断片を用いることで、技術者が実業務解決の為のヒントを提供することも意図している。
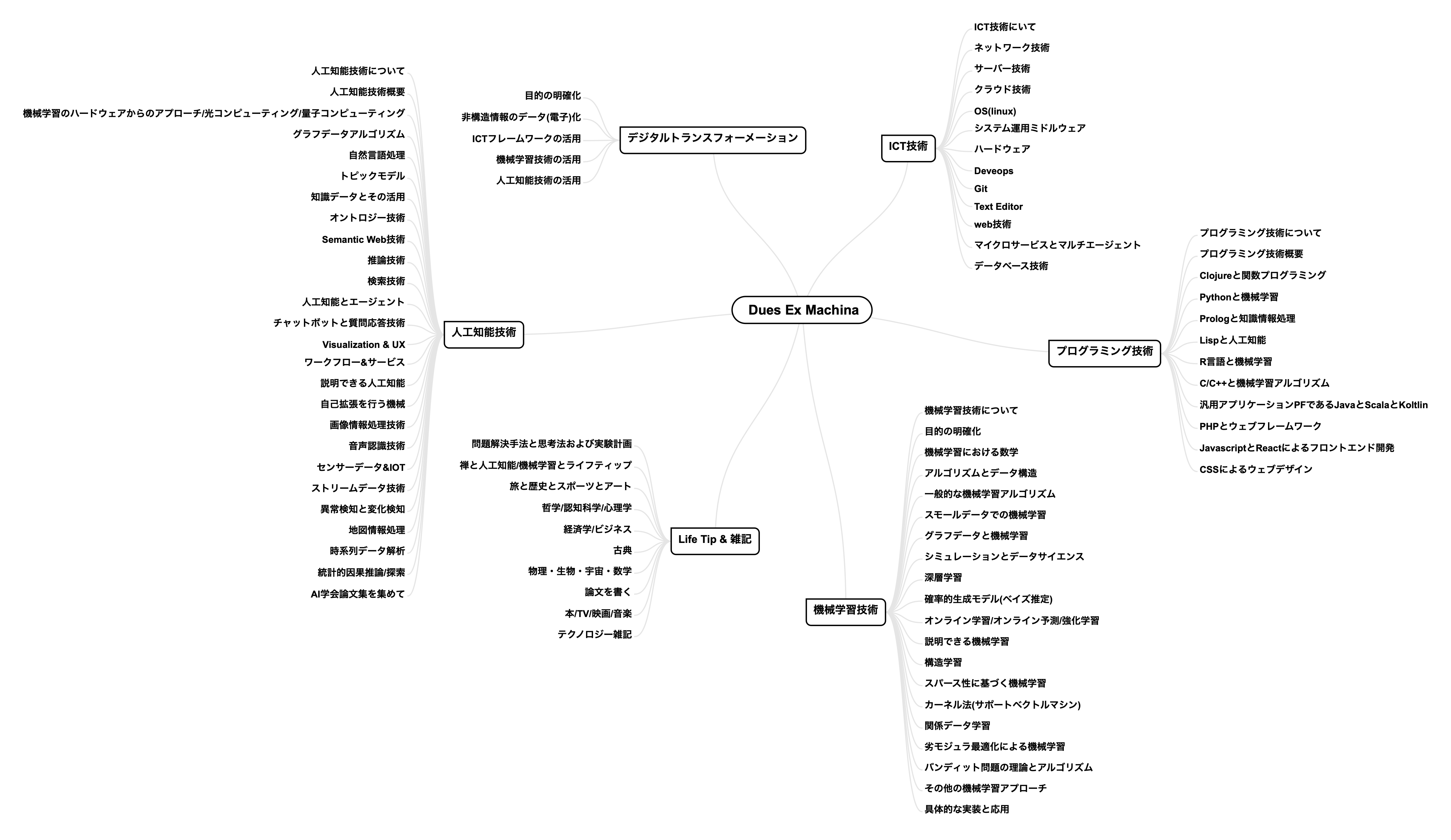
本ブログの中に記載されている内容の見取り図は以下のようになり、ITのインフラから始まり、プログラミング技術、様々な機械学習技術とAI技術、それらのデジタルトランスフォーメーションへの適用、そして最後にlife tips&雑記について述べている。これらを全てマスターすることができれば、人工知能システムをゼロから作り上げることも十分可能ではないかと考えている。


以下、それぞれの詳細について述べる。
ICTの基本技術
まず ICT技術のベースとなる インフラ技術について、 Amazon Web Servicesネットワーク入門のシリーズでAWS上でのネットワークの設定、サーバー構築、セキュリティの設定等について学べることが出来、一通りのクラウドインフラ構築ができる知識を獲得できると共に、オンプレミスのインフラ構築に対する知識を得ることができる。
次に、 Linuxについてにて、立ち上げたインフラ上でのサーバーの基礎知識を得ることができ、後日掲載予定のubuntu、centosの記事で個別のOSの扱いについて知ることができる。
ハードウェアの章では、FPGAやASIC等の構築を主に機械学習の観点から述べる予定で、さらに簡易なPCとしてのRaspbery Piや、Arduino、各種センサーデバイスについても述べる予定である。
サーバーを構築した後のウェブ技術全般に関しては Web技術についてにて述べる。ここではまず インターネット技術概要から始まる記事でウェブ技術の概要(インターネット技術概要、HTTPプロトコル、ウェブサーバー、ウェブブラウザ、ウェブアプリケーションとJavascriptやReact等のプロジラミング技術)について俯瞰した後、 Javascriptによるフロントエンド開発や CSSによるウェブデザインにてフロントエンド技術について述べると共に、 PHPとウェブフレームワークや Clojureと関数型プログラミングにてバックエンド技術にいて述べる。これらの記事は具体的なコードも掲載されているため、読みながら動く実装を行うことができる。
さらに実用という観点では、 Node.jsとReactを使ったchatbotの実装でのチャットボットの実装や MAMPとmedia wikiの立ち上げと簡単な使い方での簡易なCMS(contents management system)システムとしてのmediawikiの立ち上げ、 検索ツールFESS 5分で立ち上げられるOSS検索ツールや 検索ツールElastic Search -ElasticSearchでのオープンソースの検索システムの立ち上げ、さらに データクレンジングツールOpenRefineや D3やReactを用いたナレッジグラフ(関係データ)の可視化、 ストリームデータや大量データを高速に処理するPF:Apache Sparkについても具体的な実装の手順を記載し、これらの記事を読むことでそれらを実際に使うことができるようにしている。
また、ウェブ技術と切っても切り離せないデータベース技術に関しては データベース技術についてにて述べてあり、これらの中では データベースのアルゴリズムにて基本的なデータベースの理論(アルゴリズム)について述べた後に、 RDBMSとSQL -SQLについてにて一般的なRDBを、さらに RDF storeとSPARQLや RedisについてでNoSQLのハンドリングについて述べている。また Schema Matching and MappingでDBの応用技術であるスキーママッチングに関しても述べている。
さらに、 検索技術についてや、 ユーザーインターフェースとデータビジュアライゼーション、 ストリームデータ技術、 センサーデータとIoTとWoT技術にてさまざまなシステム技術の具体的な例について述べるとともに、未来のウェブ技術としては Semantic Web技術にて、web2.0や3.0に対応した技術や各種学会の最新情報( AI学会論文を集めて)について述べている。
プログミング言語について
上記のICT技術を具体的に構築する プログラミング言語に関しては、 プログラミング技術概要にて、 プログラミングについてから始まり オブジェクト指向言語、 関数型言語、 web技術の現在等の記事にて、概要あるいはプログラミング言語の歴史について述べている。
さらに個別の言語に関しては、 Clojureと関数型プログラミング、 Pythonと機械学習、 PHPとウェブフレームワーク、 Prologと知識情報処理、 LISPと人工知能技術、 R言語と機械学習、 C/C++と各種機械学習アルゴリズム等のバックエンド側のプログラミング言語では、主に人工知能、機械学習、ウェブ技術の観点から、言語の概要とさまざまな応用に関して、具体的なコードをベースに述べている。また、 Javascriptによるフロントエンド開発、 CSSによるウェブデザイン等のフロントエンド言語に関しても具体的なコードを中心に述べており、これらを使うことでスムーズなプロトタイピングが可能になる。
本ブログの主テーマである 人工知能技術と 機械学習技術に関しては多くのコンテンツを掲載している。
機械学習技術について
まず 機械学習技術にいて。最初に 科学的思考や KPI,KGI,OKR等の記事にて、機械学習を考える上で重要な課題の科学的/方法論的分析手法について述べ、 確率的生成モデルを用いた機械学習等などによる少数データの機械学習、 K近傍法,カーネル密度推定による局所学習等などによる局所学習と集団学習、 確率と論理の融合等など論理やルールと機械学習の融合、 シミュレーションとデータの同化等などによるシミュレーションデータの同化や、 統計的処理によるノイズ低減等ノイズ除去やデータクリーニング、 モンテカルロ検定等によるモデルの検定、 高度なオンライン学習等による分散並列処理など様々なトピックについての記事を記載している。
さらに、代表的な機械学習技術の深掘りとして、 機械学習における数学にて数学的基礎を述べ、 機械学習のアルゴリズムとデータ構造や 一般的な機械学習アルゴリズムにて基本的な機械学習のアルゴリズムやデータ構造について述べている。
グラフデータアルゴリズムや 構造学習ではデータの持つ構造(グラフ構造など)に注目したアルゴリズムと実装についてのべ、さらに 説明できる機械学習ではそれらを利用した学習モデルの説明可能性について述べている。近年大幅に発展した 深層学習に関しては、 特徴量はどこから来るのかにて近年の深層学習の草分けとなったヒントンの論文をベースに分散表現とボルツマンマシンについて述べ、 オートエンコーダーや 畳み込みニューラルネットワーク、 Word2Vec、 深層学習による自然言語処理、 グラフニューラルネットワークにて画像・音声・自然言語等への応用について述べている。具体的な実装としては、最もシンプルに利用できるpythonを用いたKerasフレームワークを使った様々な応用例を pythonとKerasによるディープラーニングから述べており、これらを読むことで、一般的なニューラルネットから、CNN、RNN、LSTMまでの実際の深層学習を行うことができる。さらに PyTorchによる発展ディープラーニングにてOpenPose, SSD, AnoGAN,Efficient GAN, DCGAN,Self-Attention, GAN, BERT, Transformer, GAN, PSPNet, 3DCNN, ECO等の最近のモデルの概要とサンプルコードへのリンクについても述べている。
深層学習とは異なるアプローチである 確率的生成モデルに関しては、 ベイズ統計の歴史とSTANを用いたベイズ推定にて、ベイズ統計の基本的な原理について述べると共に、 ベイズ推論とMCMCのフリーソフトにて、ベイズ推論の強力なツールであるMCMCのライブラリSTANとその具体的な利用について述べると共に、 マルコフ連鎖モンテカルロ(MCMC)法にてMCMCの原理と実装、 変分ベイズ学習についてや、 ベイズ推論による機械学習、 ノンパラメトリックベイズとガウス過程についてで様々なベイズ推論の手法について述べている。
スパース性に基づく機械学習において、様々な機械学習での正則化(パラメータ数の最適化)モジュールとして利用されているLassoを中心とした理論と実装にについて述べている。また、 カーネル法(サポートベクトルマシン)にてLassoと並んで機械学習技術のブレークスルーと言われたカーネル関数と双対問題(ラグランジュ不等式)による様々な機械学習のタスクへの応用について述べている。 時系列データ解析は、時間軸上で自己相関があると仮定されたデータを用いて、状態空間モデルと呼ばれるモデルをベースとして、機械制御やビジネス応用に利用されるカルマンフィルターやパーティクルフィルター等の様々な確率的アプローチを使ったデータ解析技術について述べ、 関係データ学習では、関係性を表すデータを行列あるいはテンソルデータとして解析し、自然言語や購買指向等の幅広いタスクに活用されている理論と実装について述べている。 トピックモデルは文書データの中からそれぞれの文書がどのような持っており、大量の文書集合から話題になっているトピックを抽出するためのモデルとなる。この技術を用いることで、トピックが近い文書を見つけたり、トピックに基づいた文書の整理を行うことが可能となり、検索等ソリューションに利用できる技術となる。また、文書データの解析だけはなく、画像処理、推薦システム、ソーシャルネットワーク分析、バイオインフォマティクス、音楽情報処理等多くの分野で応用されている。 統計的因果推論/探索は膨大なデータの中から単なる「相関」ではなく、原因のと結果の関係である「因果関係」を導き出す機械学習アプローチで医療や製造業をはじめとした様々なシチュエーションでの応用について述べている。 劣モジュラ最適化と機械学習では「離散」的なデータに対する機械学習で主に組合せ最適化の領域で、センサ配置やコンピュータビジョンのグラフカット等のタスクについて述べられている。 シミュレーションとデータサイエンスと人工知能では、シミュレーションの側から出発して、シミュレーションの途中経過に「データ」を取り込んでいく機械学習的アプローチであるデータ同化や、実世界のデータの代わりに、シミュレーションの出力を模倣して機械学習を行う「エミュレーション」等を使って従来の機械学習技術を拡張している。アルファ碁や自動運転技術で有名になった強化学習技術に関しては、 オンライン学習/オンライン予測/強化学習や バンディット問題の理論とアルゴリズム、 人工生命とエージェント技術等で述べられている。
人工知能技術
本ブログで紹介する機械学習以外の 人工知能技術としては、人が発する情報(言語情報)を機械が扱えるようなデータに変換する 自然言語処理技術、データとデータの意味関係を使って様々なデータを自動生成する セマンティックウェブ技術、知識情報を扱う 知識情報処理技術や オントロジー技術、人と機械との会話を実現させる チャットボットと質疑応答技術、機械が様々な推論を行う 推論技術、それら以外にも 画像情報処理技術、 音声認識技術、 異常検知と変化検知技術、 ストリームデータ技術、 センサーデータ&IOT技術、 人工生命とエージェント等様々なアプローチがある。
さらにそれらを可能とする為の理論的バックグラウンドとして、情報理論、離散数学、圏論、グラフ理論、論理学、動的計画法に遺伝的アルゴリズムやPSO等の理論的バックグラウンドについても個別のテーマとして述べている。
自然言語処理は人間が操る言葉を、コンピューターが扱えるようにするための技術であり、「ことばとは、このようなものだ」という規則を書き連ねたり、「言葉が実際にどのように使われているのか」という統計的なモデルをたてて問題を解いたりとさまざまで、 コンピューターでシンボルの意味を扱うにあるように言葉の意味を扱うには、哲学的/数学的なアプローチが必要となる。また適用される 機械学習技術も、 深層学習技術、 確率的生成モデル、 トピックモデル等さまざまなアプローチがある。life tips & 雑記
上記以外のトピックとしては 問題解決手法と思考法及び実験計画にて、 フェルミ推定や 科学的思考に基づいた仮説検証の為の推論パターンあるいは、 KPI,KGI,OKR等による課題分析のメソドロジー 因果関係推論の為の実験計画による実験計画の考え方等が述べられている。
さらに、 禅と人工知能/機械学習とライフティップにて、禅の思想を中心に 仏教的学びと愉快な生き方や 禅的生活による禅の思考と生き方のヒント、そして 人工無能が語る禅とブッダぼっどに禅と人工知能との関係について述べている。
最後に、 旅と歴史とスポーツとアートにて国内外の紀行と歴史とスポーツとアートについても述べられている。