AI is not about prediction.
It is about decision.
This concept has been compiled into a practical guide.
“AI is not prediction. It is decision.”
— Decision Trace Model Practical Guide —
Available now on Kindle
English edition coming soon
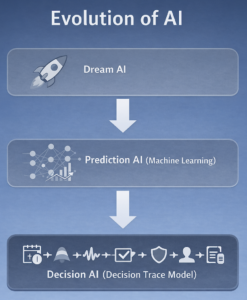
Where AI comes from — and where it is going
When I was building AI solutions at Xerox,
we were pursuing a certain vision.
An AI like Astro Boy—
an entity that could think,
make decisions,
and act like a human.
But in reality, AI took a different path.
It evolved into systems that predict,
classify, and optimize—
machines that produce answers from data.
And along the way,
something began to disappear.
It was the question:
“Who is making the decision?”
What should be done
Where should the system stop
Who takes responsibility
Decisions that were once made by humans
became buried inside systems.
AI can generate answers.
But that alone is not enough.
What we need is:
to bring decision back.
To involve humans,
to take responsibility,
and to treat decision as a structure.
That is why we need:
Decision Trace Model
This is not about making AI smarter.
It is about transforming AI
from a system that produces outputs
into one that executes decisions.
And ultimately,
it is a design
to bring human decision-making
back to the center of the system.
Source: Fujifilm Business Innovation (Facebook, February 8, 2019)
This video represents a time when AI was imagined as a “dream.”
But in reality, AI has evolved in a different direction.
That is why now,
what we need is not more intelligence,
but a system.

Decision Trace Model treats decision-making as a structured process:
Event → Signal → Decision → Boundary → Human → Log
In this structure, the output of AI is only a “Signal.”
Decisions can be defined even without AI.
AI can then be incorporated as a signal to enhance those decisions.
Decision comes first.
AI is only a part of it.
What truly matters is:
what decision is made,
how it is executed,
and where control is returned to humans.
Decision Trace Model makes this process explicit,
making decisions visible,
enabling human involvement,
and restoring accountability.
Introduction
AI today has made significant advances in prediction, classification, and generation.
In recent years, with the evolution of development environments such as Claude Code,
these capabilities can now be implemented by anyone, in a short period of time.
In other words,
AI outputs (Signals) are rapidly becoming commoditized.
However, what is truly required in real-world practice is not the output itself.
It is:
“What should be decided, and how should it be executed?”
This is where most AI systems stop.
They can predict.
But they do not define what to do.
In other words, the structure of decision-making is missing.
This site presents a way of thinking that reconstructs AI
—not as a mechanism for generating outputs—
but as infrastructure for decision-making.
Decision Structure
Decision-making inherently follows this flow:
Event → Signal → Decision → Boundary → Human → Log
- Event: What happened
- Signal: AI prediction
- Decision: What to do
This is how decisions actually work.
This is not just a concept.
Decision-making is already executed in this structure.
Decision Trace : the core concept of treating decision-making as a structured process
AI is not for prediction.
It is for decision-making.
This demo shows how decisions are structured, executed, and recorded.
This system transforms real-world changes into a clear and traceable decision-making flow.
Raw Change → Signal Extraction → Decision → Boundary → Human → Log
Unlike traditional AI, where decision logic is hidden inside the model,
this approach externalizes decision-making logic and treats it explicitly.
Each step is:
- Traceable — You can see how the decision was made
- Explainable — The reasoning is visible as a structure
- Executable — Decisions directly lead to actions
- Governable — Constraints and human intervention can be integrated
This is not just AI.
It is a decision-making system.
Multi-Agent : a decision-making system based on role-based decomposition
This demo shows how multiple AI agents, each with a specific role, collaboratively generate a single decision.
- Signal Agent: Extracts context and intent
- Decision Agent: Selects the optimal action
- Risk Agent: Evaluates risks and constraints
- Execution Agent: Initiates the execution process
The key point is that AI is not making decisions as a single entity.
Instead, decision-making is decomposed and handled by specialized roles.
This structure significantly improves:
- Transparency of decisions
- Reproducibility
- Ability to continuously improve
Architecture : the system structure for implementing decision-making
This section organizes how AI performs decision-making as a system architecture.
Traditional AI focuses on prediction and generation by individual models.
However, in real-world operations, what matters is the process of deciding what to do.
In this architecture, decision-making is enabled by combining the following components:
- Ontology — Defines meaning
- DSL (Domain-Specific Language) — Describes decision conditions
- Behavior Tree — Controls execution flow
- GNN (Graph Neural Network) — Learns relationships
By integrating these elements, the system enables decision-making to be structured, described, and executed.
Use Cases : real-world applications in business operations
With Decision Trace Model × Multi-Agent,
AI evolves from a tool for analysis and prediction
into a system that supports and executes decision-making.
Across various domains, the following transformations occur:
Manufacturing
- Anomaly detection → Automated response decisions
- Quality inspection → Shipment approval support
- Equipment maintenance → Decision-making for repair timing
On-site decisions become structured and reproducible
Retail
- Demand forecasting → Ordering decisions
- Customer analysis → Action selection
- Campaigns → Optimization of distribution and execution
Moving from revenue-only to ROI and LTV-based decision-making
Call Centers / Customer Support
- Inquiry handling → Response generation
- Knowledge search → Decision support
- Escalation → Branching decisions
Context-aware responses with clear accountability
Education
- Learning logs → Next learning decisions
- Understanding analysis → Timing of intervention
- Content recommendation → Design of learning paths
Dynamically optimizing what to teach
Legal / Compliance
- Contract review → Risk assessment
- Regulatory compliance → Identification of impact scope
- Approval processes → Visualization of decision flows
Toward explainable and auditable decision-making systems
What Changes
Traditional AI has been designed around a model-centric structure
that generates outputs from inputs.
Data is provided as input
The model processes it
An output (prediction or generation) is returned
This approach is powerful.
And today, such systems themselves have become easy to implement.
However, there is a critical problem.
AI can produce outputs,
but it does not define decisions.
As a result:
We do not know why a decision was made
Accountability becomes unclear
The same situation can lead to different outcomes
In practice, what is required is not just prediction,
but decision-making —
determining what to do.

In the Decision Trace Model,
decision-making is treated not as something embedded within a model,
but as an explicit structure.
Event: What happened
Signal: Interpretation of the situation (e.g., LLM outputs)
Decision: What action to take
Boundary: Constraints and policy checks
Execution: Action is carried out
Log: The decision process is recorded
By decomposing decision-making in this way,
• Transparency of decisions
• Reproducibility
• Continuous improvement
become possible.
AI shifts from something that predicts,
to a system that executes decisions.
■ Beyond Knowledge: The Accumulation of Decisions
Traditionally, AI adoption in enterprises has focused on:
• Data accumulation
• Knowledge sharing
• Improving searchability
In other words, managing knowledge.
However, what truly matters in real-world operations is:
What decisions were made,
based on that knowledge.
In the Decision Trace Model,
• Under what circumstances
• Based on which Signals
• What decisions were made
• Where human intervention occurred
are all captured as structured data.
This is not just knowledge.
It is the history of decisions.
And this accumulation of decisions
becomes a true organizational asset.
Decisions that can be reproduced
Decisions that can be improved
Decisions that can be transferred
As these accumulate,
the organization’s decision-making capability itself evolves.
And this accumulated decision asset does not stop at being recorded.
By applying Decision Trace GNN Core,
stored decisions are learned as relational structures,
and become reusable, optimizable,
and continuously evolving entities.
In other words,
decisions shift from something that is merely recorded
to something that is actively learned.
■ From Concept to System
Decision Trace Model is not just a concept.
Decision-making can already be:
- defined as a structure
- executed as a system
- continuously improved
And now, the concrete implementations to realize this are emerging.
■ Decision Trace Studio (Designing and Improving Decisions)
Decision-making is not something you create once and finish.
It requires a continuous cycle:
- Design
- Execute
- Compare
- Improve
an environment for designing, validating, and improving decisions
Within this environment, you can:
- design decision flows as nodes
- simulate them with scenarios
- compare results before and after changes
- generate improvement suggestions
In other words:
It turns decision-making into something that can be operated and managed
While traditional AI focuses on outputs,
Decision Trace Studio focuses on:
Decision itself
■ Light DTM Starter Kit (Starting from the Minimum)
“It’s difficult to build something this comprehensive from the start.”
That is a natural concern.
That’s why we provide:
This is a minimal implementation that separates:
- Signal (AI outputs)
- Decision (simple rules)
Even this minimal structure enables:
- visibility into why the same AI produces different outcomes
- reduction of decision variability
- a baseline level of reproducibility
In other words:
the first step from AI output to decision
■ The Path to Full Implementation
Starting from Light DTM, you can gradually introduce:
- Boundary (constraints and policies)
- Human (human-in-the-loop)
- Multi-Agent (role-based decomposition)
- Trace (decision history)
Eventually, this evolves into:
a fully structured decision system
■ Overview
- Decision Trace Model
→ The structure of decision-making (Concept) - Decision Trace Studio
→ Environment for designing and improving decisions (Design / Simulation / Compare) - Light DTM Starter Kit
→ Entry point for minimal adoption (Entry Point)
Together, these transform AI from a mere tool into:
decision infrastructure
Latest Insights
- Why Government AI Excels — and What Is Still Not Designed Yet■ Introduction In recent years, the development of government AI has been accelerating across countries. For e […]
- How to Find Knowledge in the Depths of the Long Tail — The Limits of Search and Exploration with Decision Trace Model × Multi-Agent■ Introduction When I was working on providing solutions in manufacturing environments,I realized one importan […]
- AI Generates Worlds. Decision-Making Selects Reality — Understanding the Nature of Decisions through Possible Worlds, ASP, and the Decision Trace Model■ 1. The World Is Not Singular We usually assume that reality is singular. However, in logic, this is not the […]
- Structure Changes the World — Making Information UsableThe other day, I visited an exhibition and saw works by Shiba Kōkan. The painting depicted an Edo landscape. A […]
- Interposer Technology Accelerating Optoelectronic Convergence — Semiconductors Evolve from “Computation” to “Connectivity” —■ Introduction The evolution of AI has so far been driven by improvements in compute performance. Parallel pro […]
- Decision Trace Model × Multi-Agent Transforming Logistics (Delivery & Transportation) — Evolving from Optimization to Execution-Driven Decision Systems —Introduction In logistics operations, the following challenges occur on a daily basis: Delivery delays Variabi […]
Technical Reference
The Decision Trace Model is not just a concept.
All of its components can be implemented as code.
- Ontology (definition of meaning)
- DSL (decision conditions)
- Behavior Tree (execution control)
- Multi-Agent (role-based decomposition)
- LLM integration (signal generation)
All of these are explained with actual code examples.
AI is not only about predicting the future,
but about supporting decision-making in the present moment.