Summary
From the Amazon Web Service Cloud Design Pattern Design Guide.
As cloud computing becomes more prevalent, a major shift is taking place in the procurement and operation of computing resources. The cloud has ushered in a new world of IT by making it possible to procure a wide variety of IT resources instantly and inexpensively, as and when they are needed.
In particular, Amazon Web Service (AWS), which has been providing cloud services since 2006, has evolved dramatically, offering a wide range of infrastructure services, including virtual servers, storage, load balancers, databases, distributed queues, and NoSQL services, at low initial costs. AWS offers a wide variety of infrastructure services such as virtual servers, storage, load balancing, databases, distributed queues, and NoSQL services on an inexpensive pay-as-you-use model with no initial costs. Users can instantly procure and use these highly scalable services as and when they need them, and when they no longer need them, they can immediately dispose of them and no longer pay for them from that moment on.
All of these cloud services are publicly available with APIs, so not only can they be controlled from tools on the web, but users can also programmatically control their infrastructure. Infrastructure is no longer physically rigid and inflexible; it is now software-like, highly flexible and changeable.
By mastering such infrastructure, one can build durable, scalable, and flexible systems and applications more quickly and inexpensively than previously thought possible. In this era of “new service components for the Internet age (=cloud),” those involved in designing system architecture will need a new mindset, new ideas, and new standards. In other words, the new IT world needs architects with new know-how for the cloud era.
In Japan, a cluster of AWS data centers opened in March 2011, and thousands of companies and developers are already using AWS to create their systems. Customers range from individual developers who use infrastructure as a hobby, to startups that quickly launch new businesses, small and medium-sized enterprises that are trying to fight the wave of cost reduction with cloud computing, large enterprises that cannot ignore the benefits of cloud computing, and government agencies, municipalities, and educational institutions.
Use cases for cloud computing range from cloud hosting of typical websites and web applications, to replacing existing internal IT infrastructure, batch processing, big data processing, chemical computation, and backup and disaster recovery. The cloud is being used as a general-purpose infrastructure.
There are already examples of businesses and applications that have taken advantage of the characteristics of the cloud to achieve success as new businesses, new businesses, and new services that were previously unthinkable, as well as examples of existing systems that have been migrated to reduce TCO.
However, we still hear of cases of failed attempts to use the cloud, and unfortunately, there are still not many architectures that take full advantage of the cloud. In particular, there are still few cases in which the unique advantages of cloud computing are fully utilized, such as design for scalability, design for failure, and design with cost advantages in mind.
This section describes the Cloud Design Pattern (CDP), a new architectural pattern for cloud computing.
The CDP is a set of typical problems and solutions that occur when designing architectures for cloud-based systems, organized and categorized so that they can be reused by abstracting the essence of the problems and solutions. The design and operation know-how discovered or developed by architects is converted from tacit knowledge to formal knowledge in the form of design patterns that can be reused.
By using CDP, it is possible to
- By leveraging existing know-how, better architectural designs for cloud-based systems will be possible.
- Architects will be able to talk to each other using a common language.
- The cloud will be more easily understood.
Among the CDP patterns described below, “Data Upload Pattern,” “Relational Database Pattern,” and “Asynchronous Processing/Batch Processing Pattern” have been previously This time, we discussed “Operation and Maintenance Patterns” and “Data Upload Patterns”. In this issue, we will discuss “Operation and Maintenance Patterns” and “Network Patterns”.
Operation and Maintenance Patterns
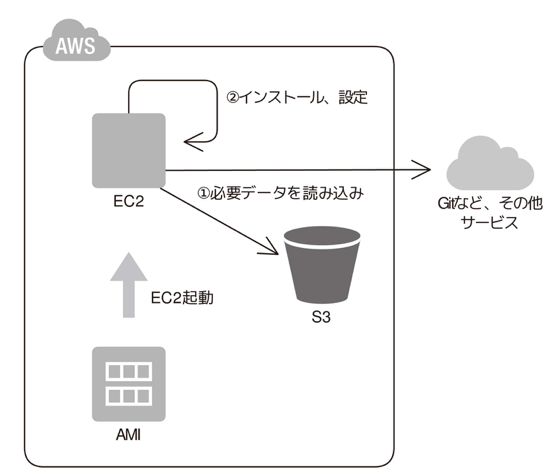
- Bootstrap: When applying the Stamp Pattern, which is a method of creating a server from a machine image, the frequency of acquiring a machine image is an issue of operational efficiency. In the Stamp Pattern, everything from middleware to applications can be pre-configured, and a machine image can be created that simply starts up and runs as-is. In this case, the virtual server starts up very quickly, but if one of the middleware versions needs to be upgraded, or if the application settings are changed, the machine image needs to be re-created. To address this issue, the cloud not only makes it easy to create a machine image, but also provides a function that allows parameters to be set at startup. The machine image is created to perform everything from installation, startup, and configuration.

- Cloud DI: In a large system, the number of servers will increase as the number of accesses increases. In such cases, manually installing and configuring the servers one by one can be very time-consuming and difficult to complete in a short period of time. One way to automate server construction is to use a system management tool, but there is the problem of cost. Especially when there is a lot of information (DB connection destination IP address, server name, recognition number, etc.) that you want to keep out of the system, the Cloud DI pattern will allow for flexible server initialization.

- Stack Development: In system development and operation and maintenance, it is common to prepare test and staging environments. Since these environments are not used all the time, it is not cost-effective to prepare the same number of servers as in the production environment. This is why virtual servers are used. However, if the system is complex and the number of virtual servers is large, building the environment and starting and stopping the related virtual servers can be complicated, time-consuming, and error-prone. To solve this problem, a template for starting up a group of servers can be prepared and automatically started up all at once according to the template. By describing the cloud components required for the environment to be built in a template and following the template to build the environment, a complex system can be prepared easily and without errors.

- Server Swapping: When a server fails, there is a lot of work to do to restore it. There are many causes of server failure, but in many cases, the disks are not the problem. In such cases, the problem-free disk can be moved to another server for quick recovery, but this requires time-consuming work at the data center, arrangements for a replacement server, and replacement of the disk. In contrast, using virtual disks that can be replaced in virtual servers, when a failure occurs in a virtual server, the disk of the failed virtual server can be replaced in another virtual server for failure recovery.

- Monitoring Integration: Monitoring (service/resource monitoring, etc.) is essential for system operations, and monitoring services are provided in the cloud. However, cloud monitoring services cannot monitor within virtual servers (OS/middleware/applications, etc.), so original monitoring is necessary, but this requires multiple monitoring systems, which complicates operations. In contrast, virtual servers are monitored by a cloud monitoring service, while OS/middleware/applications are monitored by their own system. Since the cloud monitoring service provides an API, it is possible to use the monitoring service to obtain information from the cloud monitoring service via the API, enabling centralized management including the cloud side.

- Weighted Transtion: This may be a case where you want to migrate an entire system from one region to another, for example, from an on-premise data center to the cloud, or from one region of the cloud to a different region. In this case, we would like to make a smooth transition without changing the domain name of the system and without shutting down the system. In order to migrate the entire system without changing the domain name, the DNS server can use a weighted round-pin function to switch from the existing system to the new system before resolving the names. At first, only a small portion of the system is allocated to the new system, and if there are no problems, the allocation to the new system can be gradually increased.

- Log Aggregation: In systems with a large number of AP servers, if access logs and other data are distributed to each server, log collection, analysis, and troubleshooting require time-consuming collection of the distributed logs. In addition, in an auto-scaling environment, the logs on the servers are deleted because the servers are automatically shut down at scale-in. To address these problems, Internet storage is used as a log collection destination to store large volumes of logs inexpensively and with high durability. This can be achieved by having a log collection agent reside on the AP server, etc., and sending logs to be aggregated to the Internet storage.

- Ondemand Activation: To secure the system, external access (inbound) to the servers is usually restricted to the minimum necessary. In addition, when logging into each server for maintenance, etc., logins are often routed through a stepping stone server (Bastin) to restrict the source of logins. In addition, to prevent information leakage to the outside, access from the server to the outside (outbound) is prohibited in some cases. When those measures are taken to increase security, maintenance becomes less easy. In the cloud, it is possible to start and stop virtual servers, change firewall settings, and perform other configuration changes that would conventionally require manual intervention via APIs. Therefore, it is possible to create a mechanism whereby a stepping stone server is started only when it needs to be accessed from the outside, and NAT is started only for maintenance such as OS package updates, thereby increasing security and ease of maintenance. At the same time, since the firewall can be changed at any time, it is possible to flexibly reinforce communication only when it is necessary.

Network Patterns
- Backnet: Servers (e.g., Web servers) that are open to the Internet and accessed by an unspecified number of users are often accessed for administrative purposes through the same network interface. However, if a high level of security is required, it is a challenge to avoid using the same network interface for trusted and untrusted access. To address this issue, multiple network interfaces are installed on the Web server for public access, and the network interface for management (called the backnet) and the network interface for public access are separated.

- Functional Firewall: Hierarchical access control using firewalls is a common security measure in conventional systems. However, as the number of access restriction rules increases, the firewall configuration becomes more and more complicated, resulting in higher operating costs. Traditionally, firewalls have often used dedicated equipment to manage rules without grouping them. Even if they could be grouped, it was difficult to easily apply them on a per-server basis. In the cloud, firewalls are virtualized and can be configured more flexibly, and rules can be grouped, configured on a group basis, and applied to each server.

- Operational Firewall: For large systems, there are multiple organizations that perform development and maintenance. For example, a system development company and a log analysis and operational monitoring company may be divided into two separate organizations. If firewall rules are defined in groups by function, it is necessary to change the rules grouped by function each time the access source changes or when access itself is no longer needed, which is not only time-consuming but also prevents centralized management of which servers each organization can access. In addition, it is not possible to centrally manage which servers each organization can access. To address this issue, a virtualized firewall in the cloud can be used to centrally manage settings related to organizations by using the unit of group as the organization when grouping rules.

- Multi Load Balancer: When supporting multiple devices (PCs, cell phones, and smartphones) for a Web application, if settings such as SSI and contact sorting are configured for each access device on an EC2 instance, it becomes troublesome to change the settings when the number of servers increases. By assigning multiple virtual load balancers with different settings to the virtual server hosting the web application, it is possible to change the behavior of network accesses via the virtual load balancer without having to modify the server (session, health check, HTTPS, etc. settings). HTTPS, etc.)

- WAF Proxy: Websites that handle important personal information (e.g., credit card information), such as e-commerce, often deploy a WAP (Web Application Firewall) to increase security. However, many systems on the cloud have been started small, and in most cases, the introduction of a WAF has not been considered. To address those issues, cloud systems can be operated with only a small number of licenses by building a proxy server that functions only with AWF upstream.

- CloudHub: When a full-mesh VPN (Virtual Private Network) connection is established between multiple locations, the configuration of VPN routers at each location becomes more complicated as the number of locations increases, and maintenance costs increase. To solve this problem, if a star VPN is de-owned, the VPN router at each site only needs to be connected to the VPN hub. However, if the VPN hub fails, all VPN connections are affected, making the availability of the VPN hub a critical issue. Conventional VPN hubs require a high initial investment, such as redundant communication devices used for VPNs, to increase availability. In contrast, some clouds provide VPN equipment, which can be used as a VPN hub.

- Sorry Page: There are times when a website cannot be accessed due to a glitch in the program code or server/network overload/failure. In addition, there are cases where a website may need to be temporarily closed down during major system modifications or security incidents. In such cases, site visitors want to be able to view alternative content, as their inability to access the website will lead to a poor customer experience. To address this issue, the cloud can host static sites using low-cost, highly reliable Internet storage, allowing for the hosting of Sorry Pages or backup sites consisting solely of static pages.

- Self Registration: When servers are started/stopped, the associated monitoring, backup, and other settings must also be changed. If the number and frequency of servers are small, this is often done manually. However, if the number of servers is large, operational errors and the time required to set up the servers in the first place become impractical, and an automated system is needed. In contrast, by using virtual servers in the cloud, the number of virtual servers can be increased or decreased according to the load and processing volume. In this situation, it is easy to keep up with the increase or decrease of virtual servers by registering the information of the user (virtual server) in the virtual database at startup, monitoring it periodically, and minimizing the information to be backed up.

- RDP Proxy: When connecting to a Windows instance on EC2 via Remote Desktop Protocol (RDP), TCP-3389 is used by default, so it is necessary to open this port when connecting via the company firewall, for example. However, there are cases where opening RDP is not permitted due to company security policies, or where RDP itself has been discovered to have security vulnerabilities, making it unsafe to use. It is also necessary to give the instance an EIP (Elastic IP) in order to connect to instances in the VPC; using the Remote Desktop Gateway (RD Gateway), a standard feature of Windows, it is possible to use SSL (HTTPS) to connect to Windows instances over the Internet in a more Secure connection to Windows instances over the Internet using SSL (HTTPS).

- Floating Gateway: When developing a system, it is preferable to build several environments, including a development environment, a test environment, and a staging environment, with no differences in system configuration between each environment. Also, in cases where an existing system is to be upgraded, it is less risky to build a new environment without modifying the existing environment. The cloud makes it easy to achieve these goals, but if the IP address range of the newly constructed environment is different from the existing one, system configuration and other changes will be necessary. On the other hand, the cloud enables the instant procurement of a virtual network environment, making it possible to create multiple virtual networks with identical settings for development, testing, and system environment upgrades, and because IP addresses and routing can be the same for virtual networks with identical settings, there is no need to change settings. This reduces the impact of system environment differences between files and stages.

- Shared Service: Log collection servers, monitoring system host servers, WAFs, virus definition distribution servers, etc. are common services provided for multiple systems, but if these services are created for each system, system costs and operation/maintenance man-hours will However, if these services are built into each system, system costs and operation/maintenance man-hours become significant. In contrast, individual systems should be built in a network independent of each other, and services to be used in common should be built in an independent network for common services. The common system and individual systems are logically connected using the network connection function in the cloud. This allows each individual system to use the systems in the common service network.

- High Availability NAT: To secure the system configuration, servers that do not need to be exposed to the Internet are often placed in a network segment (private subnet) where direct communication with the Internet is not possible. In this case, outbound communication from the private subnet to the outside world goes through a NAT server or proxy server, but if this server fails, outbound communication from the server in the private subnet will not be possible, leading to failure of the entire system. In response to this, redundant NAT servers/proxy servers are provided using cloud virtual servers.


AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.
