Artificial Intelligence Technology Web Technology Knowledge Information Processing Technology Semantic Web Technology Ontology Technology Natural Language Processing Machine learning Ontology Matching Technology
Continuing from the previous article on similarity in natural language from ontology matching. In the previous article, we discussed string-based similarity. This time, we will discuss language-based methods.
Previously, we considered a string as a sequence of characters, but for general use, it is important to treat it as a string (sentence) rather than a single word. Here, for example, when we divide the string “theoretical peer-reviewed journal article” into words (theoretical, peer, reviewed, journal, article), which are easily identifiable character sequences derived from dictionary entries In this case, the words are not in a bag of words as used in information retrieval, but in an array with a grammatical structure. Here a word like peer has a meaning and is associated with a concept, but a more useful concept that should be properly handled in a text would be a term like peer-review or peer-reviewed journal.
A term is a phrase that identifies a concept, and will be commonly used to label concepts in ontologies. Therefore, ontology matching can greatly benefit from the recognition and identification of terms in strings. This is equivalent to recognizing the term Peer-reviewed journal with the label peer-reviewed scientific periodical (not journal review paper).
The language-based approach uses natural language processing (NLP) techniques to extract meaningful terms from the text. By comparing these terms and their relationships, the similarity of names and comments of entities in the ontology can be assessed. Although they are based on some linguistic knowledge, we can broadly distinguish between (1) methods that rely only on algorithms (intrinsic methods) and (2) methods that use external resources such as dictionaries (extrinsic methods).
(1) Intrinsic method. Linguistic normalization
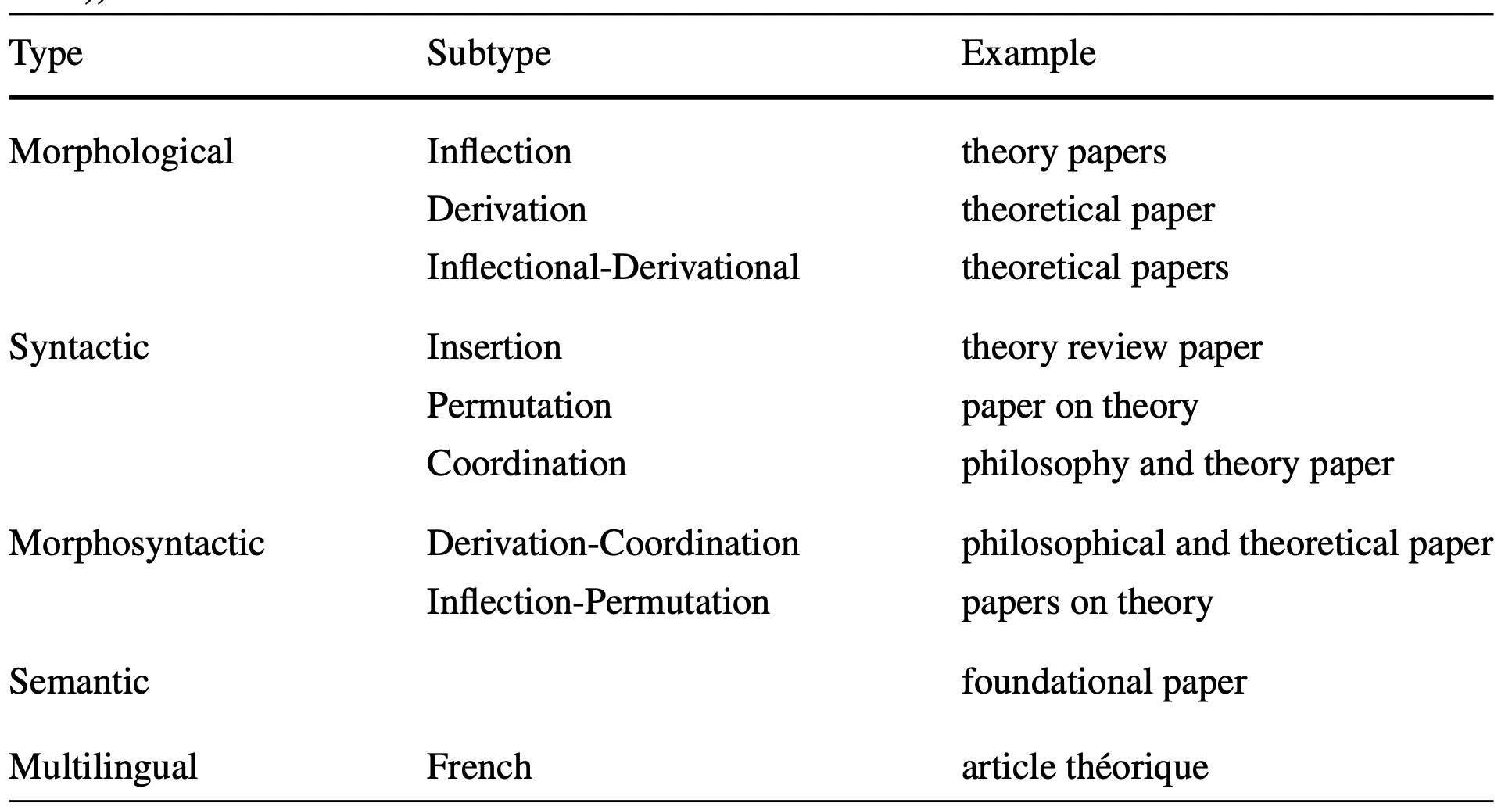
Linguistic normalization is achieved by making each form of a term into a standardized form that can be easily recognized. The table below shows that the same term (theory paper) can appear in different forms. The table below shows that the same term (theory paper) appears in different forms. There are three main variations of this term (Maynard and Ananiadou 2001). There are three main types of variations in this term (Maynard and Ananiadou 2001): (1) morphological (variations on the form and function of words based on the same etymology), (2) syntactic (variations on the grammatical structure of a term), and (3) semantic (variations on the meaning of a term). (3) Semantics: variations on an aspect of a term, usually using hypernyms (words that encompass concepts of other words) or hyponyms (subordinate words). Multilingual variations, i.e. where variations of a term are expressed in different languages, can be further added to these. Various subtypes of these broad categories are illustrated in the table below. Furthermore, these types of variations can be combined in various ways.

A number of linguistic software tools have been developed to quickly obtain the canonical form of strings representing these terms. These include those available through shallow parsers and part-of-speech taggers (Brill 1992), Lucene5 (McCandless et al. 2010), which is an open framework and includes a lemmatiser (SnowBall), and Gate6 (Cunningham et 2011), which is a language workbench that covers all of the following features
Tokenization. Tokenization is the process of splitting a string into a series of tokens by recognizing punctuation, capitalization, whitespace, numbers, and so on. For example, a theoretical peer-reviewed journal article would be ⟨peer, reviewed, periodic, publication⟩.
Lemmatisation: A module that has the ability to morphologically analyze the underlying string of a token and reduce it to a normalized base form. Morphological analysis can find word root inflections and derivations, including suppressing tense, gender, and number marks. The search for those roots is called “lemmatization”. The system also has a feature called stemming, which removes suffixes from terms (Lovins 1968; Porter 1980). This would be, for example, turning a review into a re-view.
Term extraction. Modules that extract terms from text (Jacquemin and Tzoukermann 1999; Bourigault and Jacquemin 1999; Maynard and Ananiadou 2001; Cerbah and Euzenat 2001). It is generally associated with what is called corpus linguistics, which requires a relatively large amount of text. Term extractors identify terms from the repetition of morphologically similar phrases in the text or from the use of patterns such as “noun1 noun2 → noun2 on noun1”. For example, it can recognize that the term theory paper is the same term as paper on theory, as in noun1 noun2 → noun2 on noun1.
Remove stop words. Tokens that are recognized as articles, prepositions, conjunctions, etc. (usually words such as to and a) are marked for discard because they are considered meaningless (empty) words for matching. For example, collection of article becomes collection article.(clojure implementation)
When these techniques are applied, the entities in the ontology are represented as a set of terms instead of words, and can be compared using the same techniques introduced in the previous section.
(2) Extrinsic methods
Extrinsic language methods use several kinds of external language resources, such as dictionaries and lexicons, to find similarities between terms.
Lexicons: A lexicon is a set of words and a natural language definition of those words. A dictionary can be used in conjunction with term-based distance (see below).
Semantico-syntactic lexicons: Semantico-syntactic or semantic lexicons are resources used by natural language analyzers. These lexicons record not only names, but also categories such as inanimate objects, liquids, etc., and the types of verbs and adjectives they take. For example, to flow would have liquid as its subject and no object. These are difficult to create and are not often used in ontology matching.
Thesauri: A thesaurus is a kind of dictionary with additional relational information. For example, Biography is a more general term than Autobiography and is a hyponym; Paper is a synonym for Article and has the same meaning; practice is an antonym for theory and has the opposite meaning. WordNet (Miller 1995) is a thesaurus that clearly distinguishes word meanings by grouping words into sets of synonyms (synsets).
Glossary. A glossary is a thesaurus of terms, often containing phrases rather than single words. It is usually domain-specific and tends to be less ambiguous than a dictionary.
It is not an exhaustive or authorized description of language resources, but it does provide a typology of properties that allow linguistic assessment of similarities between terms.
These resources may be defined for a given language, or they may be domain-specific. In the latter case, they hold special meanings or meanings that do not exist in everyday language, and thus tend to fit better when the text or ontology is related to that domain. It may also contain proper nouns and common abbreviations used in the domain. For example, a company might use Compact Disc for CD, or PO for Purchase Order, instead of Post Office or Project Officer.
Language resources are introduced to deal with synonyms (since matching entities have different names). Increasing the number of interpretations (meanings) of a word increases the likelihood of finding a matching word (true positives). However, on the other hand, it also increases the number of homonyms (more words to match) and the possibility of incorrectly matching words that do not match (false positives) cases. Dealing with this problem is known as word sense disambiguation (Lesk 1986; Ide and Véronis 1998). (For more information on Lesk, see “Overview of Lesk Algorithm and Related Algorithms and Example Implementations.)This attempts to limit the number of candidate senses (and candidate matches) from the context, in particular, selecting senses in relation to other related words and their senses. Word sense disambiguation techniques have been used intensively in ontology matching (Gracia 2009), and some systems, such as Blooms (Sect. 8.1.34), use Wikipedia’s disambiguation page as a way to disambiguate terms used in ontologies. There are also
Here we use WordNet (Miller 1995; Fellbaum 1998) to illustrate the use of external resources; WordNet serves as an electronic lexical database for English (it has been adapted for other languages, for example, EuroWordNet8). A synset represents the concept or meaning of a set of terms; WordNet also provides hypernym (higher/subordinate concept) structures and other relations such as meronym (part of a relation). It also provides textual descriptions (glosses) of concepts, including definitions and examples. Here, we consider WordNet as a partially ordered synonym resource.
definition 21 (Partially ordered synonym resource) A partially ordered synonym resource Σ on a set of words W is a triple ⟨E,≤,λ such that E⊆2W is a set of synonyms, ≤ is a hypernym relation between synonyms, and λ is a function from a synonym to its definition (the text considered here as the bag of words in W). ⟩. For a term t, Σ(t) denotes the set of synsets associated with t.
As an example, the WordNet (version 2.0) entry for the word author is shown below. Each meaning is numbered with a superscript.
author1 noun: Someone who originates or causes or initiates something; Ex- ample ‘he was the generator of several complaints’. Synonym generator, source. Hypernym maker. Hyponym coiner. author2 noun: Writes (books or stories or articles or the like) professionally (for pay). Synonym writer2. Hypernym communicator. Hyponym abstractor, allit- erator, authoress, biographer, coauthor, commentator, contributor, cyberpunk, drafter, dramatist, encyclopedist, essayist, folk writer, framer, gagman, ghostwriter, Gothic romancer, hack, journalist, libretist, lyricist, novelist, pamphleter, paragrapher, poet, polemist, rhymer, scriptwriter, space writer, speechwriter, tragedian, wordmonger, word-painter, wordsmith, Andersen, Assimov. . . author3 verb.: Be the author of; Example ‘She authored this play’. Hypernym write. Hyponym co-author, ghost.
This is similar to a traditional dictionary entry, except for the function of Hypernym and Hy-ponym and the explicit mention of the considered sense. Figure 5.1 will show the hypernym relations of the words creator, writer, author, illustrator, and person.
There are at least three families of ways to use WordNet as a resource for matching terms used in ontology entities.
– A method that considers two terms to be similar because they belong to some common synset.
– Using a hyponym structure to measure the distance between the synsets corresponding to the two terms.
– Using the definition of concepts provided by WordNet to evaluate the distance between synsets associated with two terms.

WordNet-based matchers can be designed by transforming the (lexical) re-presentations provided by WordNet into logical relations according to the following rules (Giunchiglia et al. 2004)
If t is a hyponym or meronym of t′, then t≤t′. For example, author is a hyponym of creator, and we can conclude that author ⊑ creator.
If t is a hypernym or holonym of t′, then t ≥ t′. For example, Europe is a holonym of France, and we therefore conclude that Europe ⊒ France.
t = t′ if they are connected by a synonymy relation or belong to a single synset. For example, since writer and author are synonyms, we can conclude that writer = author.
t ⊥ t′, if they are connected by an antonymic relation or are siblings in some part of the hierarchy. For example, Italy and France are siblings in the WordNet part-of-hierarchy, and thus we can conclude that Italy ⊥ France.
Here we can define a simple measure (here we only consider synonyms, because they are the basis of WordNet synsets, and other relations can be used). The simplest use of synonyms would be as follows.
Definition 23 (Synonym Similarity) Given two terms s and t, and a synonym resource Σ, a synonym is a similarity σ : S × S → [0 1] such that
\begin{eqnarray}\sigma(s,t)=\begin{cases} 1&(if \sum(s)\cap\sum(t)\neq \emptyset \\ 0& otherwise\end{cases}\end{eqnarray}
This is considered to be the maximum similarity between author and writer (1.) and the minimum similarity between author and creator (0.).
As an example, the table below shows the calculation of similarity of synonyms for illustrator, author, creator, person, and writer.

This strict use of synonyms makes it impossible to analyze how far apart non-synonymous objects are from each other and how close synonymous objects are to each other. Since synonyms are relations, all measures on the graph of relations can be used for synonyms in WordNet. Another measure is the one that calculates the cosynonymy similarity.
Definition 25 (Cosynonymy similarity) Given two terms s and t and a synonym resource Σ, cosynonymy is the following similarity σ : S × S → [0 1].
\[\sigma(s,t)=\frac{|\sum(s)\cap\sum(t)|}{|\sum(s)\cup\sum(t)|}\]
As an example, the table below shows the cosynonymy similarity calculated for illustrator, author, creator, person, and writer.

Some elaborate measures use a measure of the hyponym-hypernym hierarchy between synsets, taking into account that a term is part of more than one synset. A simple measure, called edge count, counts the number of edges (or structural topological dissimilarities) separating two synsets in Σ. In addition, there is a way to weight the edge count by the position of the synsets in the hierarchy, as proposed by Wu and Palmer (see Section 6.1.1). All the measures defined in Section 6.1.1 can be used for hypernym graphs in WordNet, provided that they can handle rootless directed acyclic graphs.
Other measures are based on an information-theoretic perspective. They are based on the assumption that the more probable a concept is, the less information it has. In other words, the information content of a concept is inversely proportional to its probability of occurrence. In the similarity proposed in (Resnik 1995, 1999), each synset (c) is associated with the probability of occurrence of an instance of that concept in a particular corpus (π(c)). Typically, π(c) is the sum of the occurrences of the words in the synset divided by the total number of concepts. This probability is obtained from a survey of the corpus. The more specific the concept, the lower this probability; the resnik semantic similarity between two terms is a function of the more general synset common to both terms. This will take into account the maximum information content (or entropy) of such a synset as the negation of the logarithm of the probability of occurrence.
Definition 27 (Resnik semantic similarity) Given two terms s and t, and a partially ordered synonym resource Σ = ⟨E, ≤, λ⟩ given a probability measure π, Resnik semantic similarity is the following similarity σ : S × S → [0 1].
\[\sigma(s,t)=\displaystyle \max_{k;\exists c,c’\in E;s\in c∧t\in c’∧c≤k∧c’≤k }(-log(\pi(k)))\]
Examples of corpus-based similarity are not provided here, as the results depend on the underlying corpus (which is used here to define π. An example of a similarity measure based on the Brown corpus9 can be found in (Budanitsky and Hirst 2006).
This measure uses the maximum value, but it is also possible to choose instead the average value or the sum of all synset pairs associated with the two terms.
Other information-theoretic similarities depend not on the amount of information shared, but on the increase in the amount of information from a term to its common hyponym. This is the case with the Jiang-Conrath method (Jiang and Conrath 1997) and Lin information-theoretic similarity (Lin 1998). In this method, the degree of overlap between two synsets is specified probabilistically.
Definition 28 (Information Theoretic Similarity) Given two terms s and t, and a partially ordered synonym resource Σ = ⟨E , ≤, λ⟩ provided with probability π, the Lin information theoretic similarity is the similarity σ : S × S → [0 1] such that
\[\sigma(s,t)=\displaystyle \max_{k;\exists c,c’\in E;s\in c∧t\in c’∧c≤k∧c’k}\frac{2xlog(\pi(k))}{log(\pi(s))+log(\pi(t))}\]
These similarities are not normalized.
The last way to compare terms in a string using a thesaurus like WordNet is to use the definitions (glosses) given to these terms. In this case, any dictionary entry s ∈ Σ is identified by the set of words corresponding to λ(s). Then, any measure defined in section 5.2.1 can be used to compare strings (Lesk 1986).
Definition 29 (Gloss overlap) Given a partially ordered synonym resource Σ = ⟨E,≤ λ⟩, the overlap of terms between two strings s and t is defined by the Jaccard similarity of those terms.
\[ \sigma(s,t)=\frac{\lambda(s)\cap\lambda(t)|}{\lambda(s)\cup\lambda(t)|}\]
As an example, to calculate the similarity of the overlap of the terms illustrator, author, creator, person, and writer, the following process was performed and the results were treated as a set of words (not a bag, so no repetition) and compared syntactically, yielding the following table .

This result is consistent with previous measures. This is because the only pair that has been consistent so far (author-writer) still gets the highest score. This measure introduces new relations such as creator-illustrator, but the (possible) relation between creator and author has not yet been found. This is entirely dependent on the quality of the WordNet glossary.
Another example of using a (WordNet) glossary to build a matcher is to count the number of occurrences of a label in the source input sense in the glossary of the target input sense. If this number is equal to a threshold (e.g., 1), a low generality relation can be returned. The reason for returning a relation of low generality is due to the general pattern of defining glossary terms via more general terms. For example, in WordNet, creator is defined as “a person who grows, makes, or invents things”. Thus, if we follow this strategy, we can find a creator ⊑ person. Another variation of glossary-based matchers is WordNet is a (part of) hierar- chy that considers the glossary of parent (child) nodes of the input sense (Giunchiglia and Yatskevich 2004). The relations generated by these matchers are highly dependent on the context of the matching task, so these matchers cannot be applied to all cases (Giunchiglia et al. 2006c).
How to support multiple languages
An ontology is monolingual if all its labels are available in only one natural language, and multilingual if it uses several different languages. Furthermore, ontology languages such as OWL and SKOS allow multiple labels to be declared in explicitly identified languages, so that the language in which the ontology entity is identified can be evaluated (e.g., Article@fr becomes the French word “article”).
Similarly, the two terms used as labels can be matched monolingually if they belong to the same natural language, or cross-lingually if they belong to two different natural languages. The first option corresponds to the techniques discussed in the previous section. However, cross-lingual matching is becoming more and more important as the languages in which ontologies are described become more diverse. There are several ways to do this, including comparison with pivot languages and cross-translation (Trojahn et al. 2010b).
Pivot-language comparison translates terms from two ontologies into one specific language (Jung et al. 2010b). This reduces the number of translations required and allows multiple languages in a multilingual ontology to be handled at once. entities, identified by different language labels in one ontology, may help to disambiguate the target term of the pivot language. For example, the English word Paper may be translated as Papel or Articulo in Spanish, but if the French label is Article, the proper meaning would be Articulo. Usually, the pivot language method is chosen because of the availability of language resources for comparing terms in different languages.
Inter-translation involves translating all terms in one ontology into the language of the other ontology (Fu et al. 2012). A variety of techniques are used for translation, ranging from the use of interlanguage resources such as interlanguage dictionaries, where definitions are replaced by equivalent terms in the other language, e.g., Paper in English corresponds to Article in French. Such dictionaries can be very useful when ontology labels are expressed in different languages. Such dictionaries can be used not only for matching, but also for disambiguating terms (i.e., identifying the intended meaning) prior to matching. Other resources, such as online statistical translators, can also be used for translation (Trojahn et al. 2010b).
If all terms are composed in only one language (the axis language or the target language for inter-translation), they can be compared using normal (monolingual) techniques. This has implications for linguistic matching techniques, leading to the following distinctions
- Monolingual matching: Matching two ontologies based on labels written in a single language, such as English.
- Multilingual matching: matching two ontologies based on labels in different languages, such as English, French, Spanish, etc. This can be achieved by parallel monolingual matching of terms or cross-lingual matching of terms in different languages.
- Cross-lingual matching is the matching of two ontologies based on labels written in two different languages, such as English and French.
These definitions are slightly different from those of Spohr et al. (2011), who refer to the second option, multilingual matching, as crosslingual. Multilingual matching is also more common than the other two options (multilanguage matching with only one language pair).
An interesting technique offered by multilingual ontologies is crosslingual val- idation. This involves matching two ontologies in different languages in parallel, such as French against French and English against English (Section 7.2), and then aggregating these parallel matches to reach a consensus. Usually, if a sufficient number of matchers find a particular correspondence, it is retained. This method has been found to be effective in increasing the accuracy of matching (Spohr et al., 2006).
Summary on Linguistic Methods
Many of the methods presented in this section have been implemented in the Perl package WordNet::similarity (Pedersen et al. 2004) and the Java package SimPack4 (see Table 5.3). These have been thoroughly compared in (Budanitsky and Hirst 2006).
Linguistic resources such as stemmers, part-of-speech taggers, lexicons, the-sauri, etc. are very valuable resources because they allow the interpretation of the terms used in the representation of the ontology. Interpreting the terms used in the representation of the ontology allows for a more accurate understanding of the label.
However, when appropriate resources are available in a language, they open up the possibility of new matches between entities, mainly because they recognize that two terms represent the same concept. Unfortunately, these techniques also recognize that the same term may represent more than one concept at the same time, thus providing many match possibilities.
One way to select these representations would be to consider the structure of the ontology entity and select the most coherent match.

In the next article, I would like to discuss the internal structure based approach.

AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.

コメント