Overview of deep learning methods
In my previous introduction to machine learning algorithms, I briefly discussed neural nets, but this time, I would like to go one step further and give a general overview of deep learning techniques. The following is from the preface of “Deep Learning” published by the Japanese Society for Artificial Intelligence: “Overall picture of deep learning methods”.
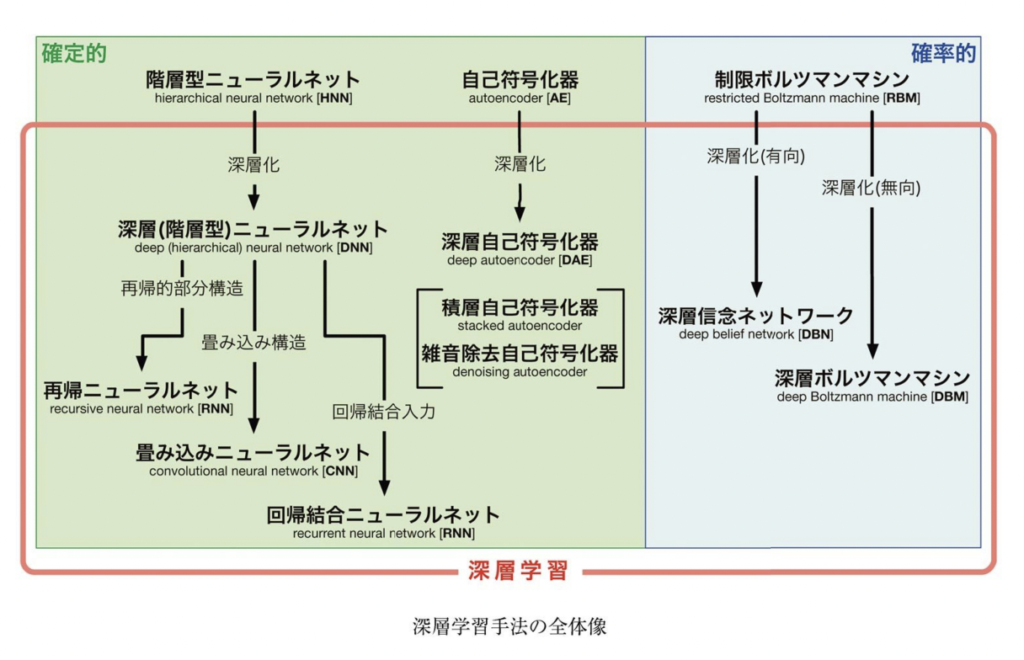
The overall picture of deep learning is as shown in the figure below.

深層学習deeplearningより
There are two main types: deterministic models, in which the output is determined deterministically with respect to the input, and stochastic models, which are based on probabilistic models. Most of the deterministic neural networks are classified as hierarchical neural networks and self-encoders.
Hierarchical neural networks have a feed-forward structure in which the code is propagated from input to output through coupling, and are mainly used for supervised learning. Hierarchical neural nets include perceptrons, multilayer perceptrons, deep (hierarchical) neural nets, recurrent neural nets, convolutional neural nets, and recurrent coupled neural nets.
The perceptron was the first neural network proposed that consists of only two layers. It has a limitation that it can only solve problems that satisfy a condition called linearly separable (i.e., data in an n-dimensional plane can be separated in an n-1 dimensional hyperplane). For solvable problems, it has been proven that the learning converges after a finite number of updates.
The multilayer perceptron is a hierarchical neural network with a feed-forward structure of about three layers, and was the most widely used neural network before the advent of deep learning. The error back propagation method is applied as a learning method, and it is mostly used for supervised learning, but it is sometimes used for unsupervised learning by applying the competitive learning rule (a learning rule that changes only the coupling coefficient of the neuron (and its neighbors) that gives the maximum output for the input data).
A deep neural network, in a broad sense, is a multilayer neural network in general, and in a narrow sense, it is a hierarchical neural network with a feed-forward structure that has been extended to four or more layers. This narrowly defined neural network has the logical advantage that even three layers can approximate any function as long as the number of nodes in the intermediate layers is sufficient, but it was not widely used due to the technical issues of local optimal solution and gradient vanishing. However, it was not widely used due to the technical issues of local optimum solution and gradient vanishing. It was discovered that deepening effectively improves the prediction performance rather than increasing the number of intermediate nodes, and new technologies such as pre-learning and DropOut, as well as innovations in activation functions and network structures, led to breakthroughs in the technical issues and made it widely used. (The details of these will be discussed separately)
A recursive neural network is a neural network with a recursive substructure. It is called a recursive neural network because it has a tree structure that recursively constructs a higher-level sub-tree structure from a lower-level sub-tree structure.
A convolutional neural network is a hierarchical neural network that incorporates a convolutional structure. They have been proposed as Neocognitron and LetNet before the advent of deep learning, and have become especially popular in the field of image recognition due to the development of distributed parallel computing technology in the 2010s and the increase in the scale of data for training.
Regression coupled neural network were invented to process time series data, and have a regression coupled input to convey the information of the input at the previous time to the information of the current input. Like the convolutional neural network, it was proposed before deep learning, but it has become popular in the fields of speech recognition and natural language processing with the increase in the scale of learning in the 2010s. Improvements have also been made, such as the long-short-term-emmory method to deal with the gradient vanishing problem.
Another deterministic model, the self-encoder, is an hourglass-shaped neural network that performs unsupervised learning. There are self-encoders, deep self-encoders, stacked self-encoders, denoising self-encoders, etc.
Self-encoders were invented for the purpose of acquiring a low-dimensional representation of the input through unsupervised learning. It has a three-layer hourglass structure that combines coding, which converts the input into a low-dimensional representation in the intermediate layer, and decoding, which returns this low-dimensional representation to its original dimensional representation. The system is trained to reduce the reconstruction error between the input and output signals.
Deep self-encoders become deep by increasing the total number of coding parts from the input to the middle layer and decoding parts from the middle layer to the output.
The multilayer self-encoder solves the gradient vanishing problem of the deep self-encoder by greedy learning in each layer.
The denoising self-coder improves robustness against unknown signals by adding noise to the input signal.
The stochastic model consists of Boltzmann machines, constrained Boltzmann machines, deep Boltzmann machines, and deep belief networks derived from Boltzmann machines (machines that approximate probability distributions).
A Boltzmann machine is a kind of probability model called a Markov probability field. It is described by a graphical model in which observed and hidden variables are drawn as nodes, and the dependencies between these nodes are shown as undirected connections. It is not widely used because it is difficult to learn due to the combinatorial explosion problem.
The constrained Boltzmann machine is a Boltzmann machine with a restriction that there are only dependencies between observed and hidden variables. This restriction greatly eases the learning constraints mentioned above and makes practical calculations possible. It was first proposed under the name of harmonium, but now the name restricted Boltzmann machine has taken hold.
A deep Boltzmann machine is a model that is deepened by making the hidden variables of a restricted Boltzmann machine as many as possible. The development of methods such as pre-learning and the Contrastive Divergence method has advanced and is widely used.
Deep belief networks are similar to deep Boltzmann machines in that they are deepened by adding multiple layers of hidden variables, but the dependency is not an undirected one, but a directed one. It has become popular in the 2000s because it can utilize techniques such as prior learning.

コメント