Semantic Web Technologies
Semantic Web technology is “a project to improve the usability of the World Wide Web by developing standards and tools that make it possible to handle the semantics of Web pages” (source: WikiPedia), and it is also a way to evolve Web technology from the current “web of documents” to a “web of data” (source: WikiPedia). It is also a project to evolve web technology from the current “web of documents” to a “web of data” (source: Wikipedia).
This is the next generation of web technology proposed by Timothy “Tim” John Berners-Lee, who invented the foundations of the current web technology (WWW, URL, HTTP, HTML).
The current content on the World Wide Web is mainly written in HTML, which can convey the structure of a document, but cannot convey detailed meanings such as the meaning of individual words. The Semantic Web, on the other hand, uses RDF or OWL to add tags to documents written in XML or JSON. These tags, which describe the meaning of the data, formalize the meaning of the documents and enable computers to automatically collect and analyze the information.
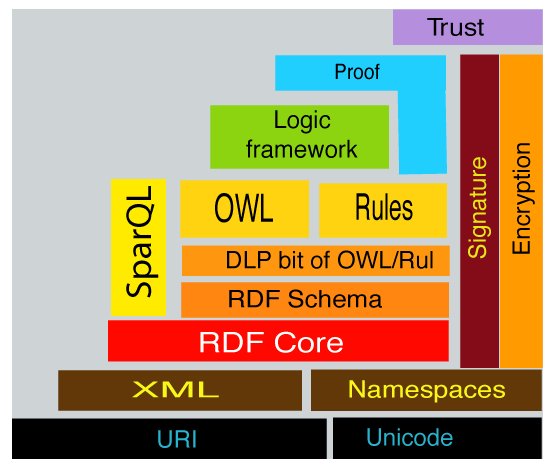
The technical structure (layer cake) of the Semantic Web is as follows.

The bottom layer is the data definition part (URI and Unicode to determine the location on the web, XML and Namespace as data definitions) to ensure the integration with web technologies, and the top layer is RDF and RDF scheme to ensure the semantics of the data, ontology, DLP, RATELLI, Rules and SPARQL to reasoning the semantics of the data. In addition, there is the Logic framework, Proof, Trust, etc. These have been standardized by the W3C.
This blog summarizes these Semantic Web technologies and ontology technologies from the perspective of digital transformation and artificial intelligence.
Reference information are as follows.
Implementation
RDF data is also known as a triplestore, which is a type of non-RDBMS graph data called a NoSQL database as introduced in the overview of DB. As for graph type DBs, there are databases composed of “nodes”, “edges”, and “properties” without RDF, such as Noo4J and DAtomic, each of which has its own query engine (Cypher, Datalog extended query). An RDF database is one that supports SPARQL, a query that conforms to the RDF data structure.
WoT (Web of Things) will be a standardized architecture and protocol for interconnecting various devices on the Internet and enabling communication and interaction between devices. The WoT is intended to extend the Internet of Things (IoT), simplify interactions with devices, and increase interoperability.
This article describes general implementation procedures, libraries, platforms, and concrete examples of WoT implementations in python and C.
CMS (Contents Management System) such as Media Wiki and Word Press are platforms that are used in various scenes. In order to run them in production, it is necessary to set up a server such as Apache and a database such as Postresql, but XAMPP and MAMP can be used for a simple start-up.
In this article, I will describe how to set up MAMP and Mediawiki (WordPress).
- Semantic Media Wiki -Semantic Web Extensions for MediaWiki
Semantic MediaWiki is a knowledge management system that can be seamlessly connected to other web systems by embedding a framework for describing the metadata of resources on the web called RDF (Resource Description Framework) in MediaWIki. It is a system that can be turned into a knowledge management system that can be seamlessly connected to other web systems.
Composer is an application-level package management system that provides a standard format for managing software and necessary library dependencies for the PHP programming language.
It runs on the command line and installs the libraries and other software on which the application depends. It can also install PHP applications available in the main “Packagist” repository, which contains available packages, and provides the ability to specify autoloading information for libraries to facilitate the use of third-party code.
It is also an important part of the functionality of well-known open source PHP projects, including Laravel
A knowledge graph is a graph structure that represents information as a set of related nodes (vertices) and edges (connections), and is a data structure used to connect information on different subjects or domains and visualize their relationships. This paper outlines various methods for automatic generation of this knowledge graph and describes specific implementations in python.
A knowledge graph is a graph structure that represents information as a set of related nodes (vertices) and edges (connections), and is a data structure used to connect information on different subjects or domains and visualize their relationships. This section describes various applications of the knowledge graph and concrete examples of its implementation in python.
Semantic Web Technology Overviews
A Knowledge Graph is a representation of information in the form of a graph structure, which will play an important role in the field of Artificial Intelligence (AI). Knowledge graphs are used to represent the knowledge that multiple entities (e.g., people, places, things, concepts, etc.) have relationships between them (e.g., “A owns B,” “X is part of Y,” “C affects D,” etc.).
Specifically, knowledge graphs play an important role in search engine question answering systems, artificial intelligence dialogue systems, and natural language processing. These systems can use knowledge graphs to efficiently process complex information and provide accurate information to users.
LOD (Linked Open Data) is a mechanism for publishing and sharing data suitable for computer processing on the Web. While the conventional Web aims to build an information space for humans by hyperlinking HTML documents, LOD aims to build a “Web of data” that can be used by computers by linking structured data together, and is an important technology for the formation of the Semantic Web. It is an important technology for the formation of the Semantic Web. The four principles of LOD in the Semantic Web are as follows. (1) Use URIs as identifiers for all data, (2) use HTTP URIs (rather than URNs or other schemes) as identifiers to enable reference and access, (3) provide useful information in a standard format (such as RDF) when a URI is accessed, and (4) ensure that data contains include links to related information in other sources to support information discovery on the Web.
The book starts with the concept of Semantic Web technologies (Part 1), then covers the handling of metadata in the enterprise (Part 2), the overview of Semantic web technologies such as RDF, Ontology, SPARQL, etc. (Part 3), the domains in which they are applied (Part 4), the checklist of items to be considered when applying them, and the introduction of vendors (Part 5). The final part (Part 5) provides the steps to actually build a Semantic Web system, and answers the question “How is it different from existing systems? The final part (Part 5) is about the steps to actually build a Semantic Web system and answers the question, “How is it different from existing systems?
After many years of theoretical research, Semantic Web technology has now expanded to include applications such as bioinformatics, e-commerce, e-government, and the social web. Applications such as genomic ontology, semantic web services, automatic catalog alignment, ontology matching, or blogging and social networking are constantly increasing, often promoted by companies such as Google, Amazon, YouTube, Facebook, and or at least backed by companies such as Google, Amazon, YouTube, Facebook, and LinkedIn. These applications need to combine information in a meaningful way in order to benefit from the Web, and they need to combine techniques for various Semantic Web research.
This handbook is the first professional reference in the field, with contributions not only on the technical fundamentals of the Semantic Web, but also on its main uses in other scientific fields such as life sciences, engineering, business, and education.
The book is divided into two parts: Volume 1 provides a detailed introduction to the technologies, and Volume 2 describes the applications using them.
This book is a literature in German that applies the Semantic Web and Linked Data technologies applied to the World Wide Web to the enterprise domain.
The contents include an overview of Semantic Web technologies for handling data in the enterprise as linked data, and actual applications such as vehicle ontology, automobile ontology (mainly for the sales scene at DaimlerChrysler), Semantic Media Wiki, application to library information, and application to multimedia.
As for automotive ontology, in recent years, there have been reports in Japan that one assuming automatic driving is being considered, and one for improving development efficiency. As for the application of multimedia, there is a system in the BBC.
This section describes WoT (Web of Things) technology used in Artificial Intelligence and IOT technologies. WoT is an abbreviation for Web of Things, which was defined by W3C, the Internet standards organization, to solve existing IoT issues.
WoT addresses one of the challenges of the IoT, which is the lack of compatibility (at present, in many cases, sensors, platforms, or operating systems work only with certain systems), by addressing the issues of existing web technologies that are already widely used (HTML, Javascript, JSON, etc.) and By using protocols to provide IoT services and applications, we can increase interoperability of devices and add features such as security and access control at the application level, as well as semantic usage of data combined with Semantic Web technologies. The goal is to enable the creation of a wide variety of services.
- Semantic Web technology, IOT and smart city Markov logic network
- Knowledge Representation and Extraction for Business Intelligence from ISWC2008 Workshop
- Extracting Tabular Data from the Web and Documents and Semantic Annotation (SemTab) LearningThere are countless tables of information on the Web and in documents, which are very useful as knowledge information compiled manually. In general, tasks for extracting and structuring such information are called information extraction tasks, and among them, tasks specialized for tabular information have been attracting attention in recent years. Here, we discuss various approaches to extracting this tabular data.
This is a collection of papers from a workshop held at the European University Institute in Florence on December 1 and 2, 2006, with the aim of building computable models (i.e., models that enable the development of computer applications for the legal domain) for different ways of understanding and explaining modern law.
The techniques are described with a focus on various specific projects, especially Semantic Web technologies.
- Agent-Based Semantic Web Service CompositionThe fundamental goal of the Semantic Web is to create a layer on top of the existing Web that allows for highly automated processing of Web content, further enabling the sharing and processing of data by both humans and software. Semantic Web services can be defined as self-sufficient, reusable software components that can be used to perform specific tasks.Here, we focus primarily on agent-based Semantic Web service compositions. Multi-agent-based Semantic Web service composition is based on the argument that a multi-agent system can be regarded as a service composition system, where different involved agents represent different individual services. Services are viewed as intelligent agent capabilities implemented as self-sufficient software components.
Semantic Web, using formal languages to represent document content and providing facilities for aggregating information spread around, can improve the functionalities provided nowadays by KM tools. This paper describes a Knowledge Management system, targeted at lawyers, which has been enhanced using Semantic Web technologies. The system assists lawyers during their everyday work, and allows them to manage their information and knowledge. A semantic layer has been added to the system, providing capabilities that make system usage easier and much more powerful, adding new and advanced means for create, share and access knowledge.
- Definitions Management: A semantics-based approach for clinical documentation in healthcare delivery
Structured Clinical Documentation is a fundamental component of the healthcare enterprise, linking both clinical (e.g., electronic health record, clinical decision support) and administrative functions (e.g., evaluation and management coding, billing). Documentation templates have proven to be an effective mechanism for implementing structured clinical documentation. The ability to create and manage definitions, i.e., definitions management, for various concepts such as diseases, drugs, contraindications, complications, etc. is crucial for creating and maintaining documentation templates in a consistent and cohesive manner across the organization. Definitions management involves the creation and management of concepts that may be a part of controlled vocabularies, domain models and ontologies. In this paper, we present a realworld implementation of a semantics-based approach to automate structured clinical documentation based on a description logics (DL) system for ontology management. In this context we will introduce the ontological underpinnings on which clinical documents are based, namely the domain, document and presentation ontologies. We will present techniques that leverage these ontologies to render static and dynamic templates that contain branching logic. We will also evaluate the role of these ontologies in the context of managing the impact of definition changes on the creation and rendering of these documentation templates, and the ability to retrieve documentation templates and their instances precisely in a given clinical context.
In this paper, we present a demonstrator system which applies semantic web services technology to business-to-business integration, focussing specifically on a logistics supply chain. The system is able to handle all stages of the service lifecycle – discovery, service selection and service execution. One unique feature of the system is its approach to protocol mediation, allowing a service requestor to dynamically modify the way it communicates with aprovider, based on a description of the provider’s protocol. We present the architecture of the system, together with an overview of the key components (discovery and mediation) and the implementation.
- Do not use this gear with a switching lever! Automotive industry experience with semantic guides
One major trend may be observed in the automotive industry: built-toorder. This means reducing the mass production of cars to a limited-lot-production. Emphasis for optimization issues moves then from the production step to earlier steps as the collaboration of suppliers and manufacturer in development and delivering. Thus knowledge has to be shared between different organizations and departments in early development processes. In this paper we describe a project in the automotive industry where ontologies have two main purposes: (i) representing and sharing knowledge to optimize business processes for the testing of cars and (ii) integration of life data into this optimization process. A test car configuration assistant (semantic guide) is built on top of an inference engine equipped with an ontology containing information about parts and configuration rules. The ontology is attached to the legacy systems of the manufacturer and thus accesses and integrates up-to-date information. This semantic guide accelerates the configuration of test cars and thus reduces time to market.
Since mobile Internet services are rapidly proliferating, finding the most appropriate service or services from among the many offered requires profound knowledge about the services which is becoming virtually impossible for ordinary mobile users. We propose a system that assists non-expert mobile users in finding the appropriate services that solve the real-world problems encountered by the user. Key components are a task knowledge base of tasks that a mobile user performs in daily life and a service knowledge base of services that can be used to accomplish user tasks. We present the architecture of the proposed system including a knowledge modeling framework, and a detailed description of a prototype system. We also show preliminary user test results; they indicate that the system allows a user to find appropriate services quicker with fewer loads than conventional commercial methods.
.In this paper, we show how to use ontology as a bootstrap for the knowledge acquisition process of extracting product information from tabular data in web pages. Furthermore, we use logic rules to infer product-specific properties and derive higher-order knowledge about product features. We also describe the knowledge acquisition process, including both ontological and procedural aspects. Finally, we provide a qualitative and quantitative evaluation of our results.
Clinical trials are studies in human patients to evaluate the safety and effectiveness of new therapies. Managing a clinical trial from its inception to completion typically involves multiple disparate applications facilitating activities such as trial design specification, clinical sites management, participants tracking, and trial data analysis. There remains however a strong impetus to integrate these diverse applications – each supporting different but related functions of clinical trial management – at syntactic and semantic levels so as to improve clarity, consistency and correctness in specifying clinical trials, and in acquiring and analyzing clinical data. The situation becomes especially critical with the need to manage multiple clinical trials at various sites, and to facilitate meta-analyses on trials. This paper introduces a knowledge-based framework that we are building to support a suite of clinical trial management applications. Our initiative uses semantic technologies to provide a consistent basis for the applications to interoperate. We are adapting this approach to the Immune Tolerance Network (ITN), an international research consortium developing new therapeutics in immune-mediated disorders.
The healthcare industry is rapidly advancing towards the widespread use of electronic medical records systems to manage the increasingly large amount of patient data and reduce medical errors. In addition to patient data there is a large amount of data describing procedures, treatments, diagnoses, drugs, insurance plans, coverage, formularies and the relationships between these data sets. While practices have benefited from the use of EMRs, infusing these essential programs with rich domain knowledge and rules can greatly enhance their performance and ability to support clinical decisions. Active Semantic Electronic Medical Record (ASEMR) application discussed here uses Semantic Web technologies to reduce medical errors, improve physician efficiency with accurate completion of patient charts, improve patient safety and satisfaction in medical practice, and improve billing due to more accurate coding. This results in practice efficiency and growth by enabling physicians to see more patients with improved care. ASEMR has been deployed and in daily use for managing all patient records at the Athens Heart Center since December 2005. This showcases an application of Semantic Web in health care, especially small clinics.
Conference Papers
A collection of papers from the first international Semantic Web conference. Many of the papers deal with the integration of Web services, which is the flexible processing of data after it has been connected. In detail, the research papers cover matching, retrieval, ontologies, RDF, etc., the position papers cover European implementations and steps to implement the Semantic Web, and the final system overview covers research papers on Semantic Web systems, enterprise applications, and using agents. The final system overview describes the Semantic Web systems in the research paper, enterprise applications, agent-based scheduling, visual analytics, etc. The table of contents is as follows. For example, in the poster session “Learning Organizational Memory”, the paper itself cannot be found on the Internet, but there are some knowledge management papers on handling organizational memory and personal memory inspired by it. However, there are many papers on knowledge management and human resource management related to organizational memory and individual memory.
Specific examples of organizational and individual knowledge management include the visualization of knowledge in an organization through cluster analysis using machine learning of text contents, and the combination of visualization of the number of repeats of text contents with word clouds. The approach of 20 years ago was to focus on structured data as text content, which was not dense enough to visualize the patterns extracted from the data, but not deep enough to visualize the knowledge. However, with the development of technology in recent years, it has become possible to approach organizational memory, which has been called “tacit knowledge” for a long time, by using voice recognition of information on conversations exchanged within an organization as unstructured data. By using voice recognition of conversations exchanged within an organization as data, it is possible to approach organizational memory, which has been called “tacit knowledge” for a long time, and it is becoming possible to add depth to the visualization of knowledge.
For example, it is now possible to visualize clustered knowledge domains using Zoomable Circle Packing, and to visualize the hierarchical structure of knowledge in an organization using tools such as Sequences Sunburst. For example, we can use Zoomable Circle Packing to visualize clustered knowledge domains, or we can use tools such as Sequences Sunburst to present the hierarchical structure of knowledge in an organization, or we can use tools such as Temporal Force-Directed Graph to visualize changes in the time series of relationships between people and contexts by focusing on information in conversations.
Similarly, various approaches are possible for recognizing patterns in data. The application of relational data learning methods such as spectral clustering, topic model approaches, and simulation methods such as Bayesian models make it possible to extract patterns in knowledge that were difficult to extract when only simple machine learning methods were available.
A collection of papers from the second International Semantic Web Conference. Compared to the first ISWC2002, the contents are much more diverse. In the basic part, OWL and RDFS are discussed for web integration, followed by ontology-based reasoning, Semantic Web services, which were discussed in the previous conference, data reliability and security, and agent systems for web service integration. This is followed by agent systems, information retrieval, and multimedia.
Finally, we move on to various tools and their applications and practical applications (Industrial Track). The industrial track covers knowledge portals in the enterprise, task computing, semantic annotation tools, and applications in the automotive and chemical industries. The table of contents is as follows.
A collection of papers from the 3rd International Semantic Web Conference. Compared to the previous ISWC2003, Data Semantics, such as thesaurus, context, bipartite graph as an intermediate data representation of RDF, etc. are discussed. In addition, P2P systems, user interfaces and visualization, and large-scale knowledge management are newly discussed.
In the deepening of the previous discussion, the application of Semantic Web services to the real world is discussed, such as the application to biotechnology and the automation of chemical experiments, and discussions on inference (related to OWL) and search (various approaches to search queries) are advanced, as well as middleware, data interoperability, and ontology maintenance.
In the final industrial track, business applications and the ontology platform at NASA are introduced. In the section on Semantic Web services, the application to bioinformatics, automation of chemical experiments using Semantic Grid, consideration of web service workflows, semi-automatic annotation, eScience, etc. are also discussed. The table of contents is as follows.
There are only three major tracks: the Research Track, the Industrial Track, and the Semantic Web Challenge. The Research Track discusses semantic search ranking, handling ontologies over time, multimedia support, encryption, dynamic community search using biographies, and probabilistic ontology mapping tools. The Industrial Track discusses legal knowledge management systems, applications in the medical field, how to develop requirements specifications for knowledge processing, applications in logistics, and applications in automotive systems.
Workshops include Modular Ontology, Ontology Matching, Semantic Web Policy, Semantic Authoring and Annotation, Healthcare and Life Sciences, Sensor Networks, Terra-Cognica Geospatial Semantic Web, Uncertain Reasoning Semantic Ewb (ERSW), and Content Mining with Natural Language Processing. Uncertain Reasoning Semantic Ewb (ERSW), and content mining with natural language processing.
Workshops being held include Terra-Cognica Geospatial Semantic Web in Ubiquitous Healthcare, Semantic Web, Uncertain Reasoning Semantic Ewb (ERSW), Privacy and Accountability, Finding Experts Using Semantic Web, Ontology Matching, Ontology Tools, Semantic Web in Buildings/Products/Engineering, Text to Knowledge, etc. Using the Semantic Web to Find Experts, Ontology Matching, Ontology Tools, Semantic Web in Buildings/Products/Engineering, Semantic Web Service Matchmaking, Text to Knowledge, etc.
Workshops being held include Social Data and the Semantic Web, Scalable Web-based Systems, Uncertain Reasoning Semantic Ewb (ERSW), Ontology Matching, Ontology Patterns, Ontology Supported Business Intelligence, Ontology Dynamics, and Semantic Web Service Matchmaking. supported business intelligence, ontology dynamics, Semantic Web service matchmaking, etc.
Workshops being held include: Structured Knowledge Sharing/Building, Ontology Matching, Ontology Patterns, Role of the Semantic Web in History Management, Service Matching in the Semantic Web, User Interaction, Social Data and the Semantic Web, scalable web-based systems, Uncertain Reasoning Semantic Ewb (ERSW), sensor networks, etc.
Workshops held include Uncertain Reasoning Semantic Ewb (ERSW), sensor networks, ontology matching, LOD (e-government), OWL2, semantic search, the role of the Semantic Web in history management, knowledge-based systems, service matching in the Semantic Web, social data and the Semantic Web, ontology patterns, etc. The role of the Semantic Web in knowledge base systems, service matching in the Semantic Web, social data and the Semantic Web, ontology patterns, etc.
In this article, I will describe the ISWC 2011 held in Bonn, Germany. The workshops include Terra-Cognica Geospatial Semantic Web, Uncertain Reasoning Semantic Ewb (ERSW) and Sensor Networks, Ontology Matching, Event Detection on the Semantic Web, Multilingual Semantic Web Multilingual Semantic Web, personalized information management, knowledge-based systems, ontology dynamics, LOD (science), web-scale knowledge extraction, etc.
This time, I would like to talk about ISWC2012 held in Boston, USA. This year’s ISWC 2012 continued the discussion on Uncertain Reasoning Semantic Ewb (ERSW), sensor networks, ontology matching, scalable systems for practical use, integration with cloud services, recommender systems, multilingual semantics, semantic web programming, etc. Semantics, Semantic Web programming, etc. are discussed.
In this article, I will describe ISWC2013, which was held in Sydney, Australia. The contents of the conference include Semantic Statistics, Stream Reasoning, Event Detection/Representation/Use in the Semantic Web, Linked Mosquito Furniture Experiment Support, Linked Data Ecosystem for Industry, Ontology Patterns, Sensor Networks, Ontology Matching Scalable Semantic Web, Crowdsourcing the Semantic Web, Linked Data for Information Extraction, Semantic Machine Learning for Agricultural and Environmental Informatics, Semantic Web Privacy and Policy, Semantic Web Enterprise, Semantic Music and Media, and more.
In this article, I will describe ISWC2014 held in Trentino, Italy. The contents include LOD, Context, Interpretation and Meaning as Natural Language Processing, Semantic Retrieval of Semantic Data, Applications in Education, LOD for Information Extraction, Linked Chemistry, On Data Reliability, Natural Language Interfaces, NLP and DBPedia, Ontology Matching, Time Transitions, Privacy privacy, ontology and semantic web patterns, scalable web-based knowledge systems, smart cities, semantic and other rare, semantic collaboration, social feb, semantic geographic information, reasoning about uncertainty, etc.
I will describe ISWC2015 held in Pennsylvania, USA. There were more presentations on datasets and performance, ontology and graphs, Linked Data, ODBA (Ontology Based Data Access), and Industry. Among the papers presented were one on a platform called LOD Laundromat, which unifies different LODs into a unified format, and another on ontology mapping (using a system called Karma) of information extracted from 68 million texts collected from the Web, and mapping the same entity of instructions to different entities. There was a report on a system that extracts information on human trafficking from various advertisements by mapping entities, ontology alignment that maps items defined separately in multiple ontologies, and a card-type search engine called knowledge Card.
ISWC was held at Kobe International Conference Center from October 17 to 21, 2016. The Resources Track invited oral presentations on resource sharing that contributes to the research community, including datasets, ontologies, services, benchmarks, ontology design patterns, workflows, methodologies, etc. The Applications Track invited presentations on applications, business cases, and prototypes that can be deployed in the real world. In the Applications Track, we are looking for applications, business cases, and prototypes that could be deployed in the real world. The session time was set for each theme, and oral presentations were given according to the theme regardless of the division. The themes ranged from Linked Data, Ontology, Inference, Query, Search, Natural Language Processing, Knowledge Graphs, Smart Planet, and many more.
Voila (Visualization and Interaction for Ontologies and Linked Data) has a ViziQuer as a UI for generating R2RML mappings,* Linked DataReactor, and various tree information Treevis.net, which classifies visualizations, is one such example.
There are also reports on learning multimodal relational knowledge using knowledge graphs that link semantic information such as textual information, image attribute information such as image information that is difficult to represent in text, and knowledge graphs that link these two types of information, and semantic data mining (SDM: background knowledge interconnected with annotated data). efficient method for generating rules that can be easily interpreted by end-users), or on improving visual relationship detection using semantic modeling of scene descriptions by StephanBrier, who used a background knowledge base to improve prediction of relationships between parts of an image. The event included the following.
FY 2018 is characterized in particular by Knowledge Graph-related and deep learning-related presentations.
First, regarding knowledge graphs, “Knowledge Graphs as enterprise assets,” Google’s knowledge graph has 1 billion objects and 70 billion assertions, while Facebook’s knowledge graph, unlike its social graph, has just increased this year and has 5 There are 10 million entities and 500 million assertions. More importantly, these are important assets for the application. For example, KG is central to the creation of product pages at eBay, KG is key to entity search and assistants at Google and Microsoft, and IBM uses it as part of their enterprise products.
And as for deep learning as a technique, it is part of the Semantic Web Researcher’s Toolbox. Notable papers at DNN include.
ISWC2019 was held in Auckland (New Zealand), and similar to the previous ISWC2018, there were many reports on knowledge (graph) data and their application to Q&A systems, etc.
One report of note was “Logical Semantics Approach for Data Modeling in XBRL Taxonomies” (the technical area of XBRL includes financial reporting, natural He mentioned that the future contribution of XBRL to semantic technology lies in the utilization of large-scale data (including AI) in these technical areas. based geospatial data integration and visualization with Semantic Web technologies A report on the implementation of geovisualization. The report states that the demand for Spatial Data Infrastructure (SDI) has been increasing in Europe and the U.S. in recent years, and that SDI can contribute as a methodology for handling ontologies in geospatial space). The report “How to make latent factors interpretable by feeding Factorization machines with knowledge graphs” (Hybrid Factorization Machine (kaHFM) demonstration. (Referring to the validation of a method for initializing latent factors for the Factorization Machine using a knowledge graph to train interpretable models), “Summarizing News Articles using Question-and-Answer Pairs via Learning” (Google research presentation on the use of semantic technology in Q&A systems. The system mines questions from data associated with news stories and learns questions directly from the story content. This is the first demonstration of a learning-based approach to generating structured summaries of news stories with question-answer pairs to capture important and interesting aspects of a news story. The validation data is from the SQuAD dataset 2). and “Using a Knowledge Graph of Scenes to Enable the Search of Autonomous DrivingData” (describes a demonstration at Bosch using semantic technology. The intended use of the data is to provide large-scale data for automated driving technology. Benefits include improved capability to represent, integrate, and query automated driving data. It is also anticipated that data scientists and engineers within various projects and departments will be able to reuse data from each other’s applications), “Using Event Graph to Improve Question Answering in E-commerce Customer Service” (describing AliMe, an intelligent assistant that provides a question-and-answer service, which can answer more than 90% of the millions of questions per day. This session proposes an Event Graph that provides a reasoning mechanism to obtain accurate answers to the question types “why”, “wherefore”, “what if”, and “how next”. Events are properties of choices of situations that can happen, and the baseline knowledge graph is generated using WIKIDATA, DBpedia, YAGO, etc.), “Querying Enterprise Knowledge Graph With Natural Language” (describes research on interactive interfaces to large enterprise knowledge graphs. He calls this mechanism Yugen (a deep learning-based interactive AI that answers user questions). Yugen is voice-based, so it has the advantage of reducing the cost of learning a specific query language), “Product Classification Using Microdata Annotations” (which described the task of automatically classifying products into universal categories using markup data published on the Web (in this case, RDF and Microdata). The challenge would be to handle the information needed for classification (e.g., treatment of individual websites, consistency across websites, site-specific product labels, etc.). This will be an example of using RDF as input data for deep learning), “Difficulty-controllable Multi-hop Question Generation From Knowledge Graphs” ( He described neural network-based multi-hop questions. A multi-hop question is a question that can only be answered by hopping a node in the graph structure two or more times. As a solution, he mentioned that he had implemented an encoder-decoder model conditional on the difficulty level and was able to generate complex questions via a large knowledge graph. However, it was difficult to achieve and seemed to require future research), “QaldGen: Towards Microbenchmarking of Question Answering Systems Over Knowledge Graphs” ( He mentioned that micro-benchmarking is necessary when trying to test domain-specific Q&A systems because of the time and effort required to generate questions. QaldGen was proposed as a framework for generating questions useful for micro-benchmarking), etc. Translated with www.DeepL.com/Translator (free version)
The ISWC2020 had a greatly enhanced presentation on the knowledge graph. The content was a Hybrid Knowledge Graph Ecosystem, an approach that uses ontologies to improve neural models and neural models to improve ontologies. The limitations that the Hybrid KG wants to overcome will be the challenges caused by the bias of the data that machine learning has and the challenges caused by the exceptions of local data, even if only in the knowledge representation. These would not only automate linking using ML, but would also leverage inference using KR to answer questions about the “why” of a phenomenon. Specific approaches include those that compute the transitive closure of a graph and then compute the node embedding of compound similarity, or even use GPT-3 for biomedical text, or daisy-chain BERT, LSTM, and CRF for NER and linkage.
Or as Semantic Web programming, primarily describing how knowledge graphs support and enhance developers and bring intelligence to various coding activities.
I will discuss ISWC2021, which was held as a virtual conference due to the coronavirus. As in previous years, many presentations related to knowledge graphs were made at this year’s conference.
As in previous years, a wide variety of papers were submitted in this year’s Research Track, with contributions falling into four categories. First, papers on classical reasoning and query answering for ontologies of various shapes, such as RDF(S)/OWL, SHACL, SPARQL, and their variants and extensions, as well as non-standard tasks such as repair, description, and database mapping. Also, as in previous years, papers on ontology/knowledge graph embedding, especially graph neural networks of various forms and their applications such as zero/few-shot learning, image/object classification, and various NLP tasks. There is also a category of papers focused on specific knowledge graph tasks, such as link and type prediction, entity alignment, etc. Finally, there were reports on surveys of the current state of the art, including the availability of LOD and structural patterns in ontologies.
This issue contains tutorial papers from the summer school “Reasoning Web” (http://reasoningweb.org), held July 25-29, 2005. The purpose of the school will be to introduce the methods and issues of the Semantic Web, a major current attempt at Web research in which the World Wide Web Consortium W3C plays an important role.
The main idea of the Semantic Web is to enrich Web data with metadata that conveys the “meaning” of the data and allows Web-based systems to reason about the data (and metadata). Metadata used in Semantic Web applications is usually linked to concepts in the application domain that are shared by different applications. Such a conceptualization is called an ontology and specifies classes of objects and the relationships between them. Ontologies are defined by ontology languages that are based on logic and support formal reasoning. Just as the current Web is inherently heterogeneous in its data format and data semantics, the Semantic Web is inherently heterogeneous in its form of reasoning. In other words, a single form of reasoning has proven to be insufficient for the Semantic Web. For example, while ontological reasoning in general relies on monotonic negation, databases, web databases, and web-based information systems require non-monotonic reasoning. Constraint reasoning is needed to deal with time (because time intervals are dealt with). Topology-based reasoning, e.g., mobile computing applications, requires programming. On the other hand, (forward and backward) chaining is reasoning that deals with views, such as databases (because views, i.e., virtual data, can be derived from real data by operations such as merging and projection).
In this article, we describe the summer school “Reasoning Web 2006” (http://reasoningweb.org), organized by the Universidade Nova de Lisboa (New University of Lisbon), which was held in Lisbon from September 4 to 6, 2006. Reasoning is one of the central issues in the research and development of the Semantic Web. Indeed, the Semantic Web aims to enhance today’s Web with “metadata” carrying semantics and reasoning methods. The Semantic Web is a very active area of research and development involving both academia and industry.
The program of the Summer School “Reasoning Web 2006” will address the following issues. (1) Semantic Web query languages, (2) Semantic Web rules and ontologies, and (3) Bioinformatics and medical ontologies – industrial aspects.
Reasoning Web will be a summer school series focusing on theoretical foundations, state-of-the-art approaches, and practical solutions for reasoning in the Web of Semantics. This issue will be the tutorial notes from the Reasoning Web summer school 2007, held in Dresden, Germany, in September 2007.
The first part of the 2007 edition, “Fundamentals of Reasoning and Reasoning Languages,” surveys the concepts and methods of rule-based query languages. It also provides a comprehensive introduction to description logics and their use. The second part, “Rules and Policies,” deals with reactive rules and rule-based policy representation; the importance and promising solutions for rule exchange on the Web are discussed, along with an overview of current W3C efforts. A thorough discussion is provided. Part 3, “Applications of Semantic Web Reasoning,” presents practical uses of Semantic Web reasoning. The academic perspective is presented by contributions on reasoning in semantic wikis. The industrial perspective is presented by contributions on the importance of semantic technologies in enterprise search solutions, building an enterprise knowledge base with semantic wiki representation, and discovering and selecting semantic web services in B2B scenarios.
The Reasoning Web Summer School is a well-established event attended by academic and industrial professionals and doctoral students interested in fundamental and applied aspects of the Semantic Web. This issue contains the lecture transcripts of the 4th Summer School, held in Venice, Italy, in September 2008. The first three chapters cover (1) languages, formats, and standards employed to encode semantic information, (2) “soft” extensions useful in contexts such as multimedia and social network applications, and (3) controlled natural language techniques to bring ontology authoring closer to the end user and introductory content, while the remaining chapters cover key application areas are covered.
The Semantic Web is one of the major current endeavors in applied computer science. The goal of the Semantic Web is to enhance the existing Web with metadata and processing methods to provide advanced (so-called intelligent) capabilities to Web-based systems, especially context awareness and decision support.
The advanced capabilities required in Semantic Web application scenarios primarily require reasoning. Reasoning capabilities are provided by the Semantic Web languages currently under development. However, many of these languages have been developed from a function-centric (e.g., ontology reasoning, access validation) or application-centric (e.g., Web service search, composition) perspective. For Semantic Web systems and applications, a reasoning technology-centric perspective that complements the above activities is desirable.
This issue of Reasoning Web is a series of summer schools on theoretical foundations, modern approaches, and practical solutions for reasoning in the Web of Semantics. This book is the tutorial note of the 6th school held from August 30 to September 3, 2010.
This year’s focus is on the application of semantic technology to software engineering and suitable reasoning techniques. The application of semantic technology in software engineering is not so easy, and several challenges must be solved in order to apply reasoning to software modeling.
In this issue, we describe the 7th Reasoning Web Summer School 2011, held in Galway, Ireland, August 23-27, 2011 The Reasoning Web Summer School is an established event in the field of applications of reasoning techniques on the Web and attracts young researchers to this new field, targeting scientific discussions of existing researchers.
The 2011 Summer School featured 12 lectures, focusing on the application of reasoning to the “Web of Data”. The first four chapters covered the principles of Resource Description Framework (RDF) and Linked Data (Chapter 1), the description logic underlying the Web Ontology Language (OWL) (Chapter 2), the use of the query language SPARQL with OWL (Chapter 3), efficient and database infrastructure related to scalable RDF processing (Chapter 4), followed by an approach to scalable OWL reasoning on Linked Data in Chapter 5, rules and logic programming techniques related to Web reasoning in the following Chapter 6, and in Chapter 7, a combination of rule-based reasoning and OWL in particular. combination of rule-based reasoning and OWL is described in Chapter 7.
The Reasoning Web Summer School series has become a major educational event in the active field of reasoning on the Web, attracting both young and experienced researchers. The Reasoning Web Summer School series has become a major educational event in the active field of reasoning on the Web, attracting young and seasoned researchers alike.
The 2012 Summer School program was organized around the general motif of “Advanced Query Response on the Web. It also focused on application areas related to the Semantic Web where query response plays an important role and where, by its nature, query response poses new challenges and problems.
In this issue, we describe the 9th Reasoning Web Summer School 2013, held in Mannheim, Germany, from July 30 to August 2, 2013.
The 2013 Summer School covered various aspects of web reasoning, from extensible and lightweight formats such as RDF to more expressive logic languages based on description logic, as well as basic reasoning used in answer set programming and ontology-based data access techniques, and emerging topics such as geospatial information handling and inference-driven information extraction and integration are also covered.
In this issue, we describe the 10th Reasoning Web Sum- mer School (RW 2014), held in Athens, Greece, from September 8-13, 2014.
The theme of the conference will be “Reasoning on the Web in the Age of Big Data.” The invention of new technologies such as sensors, social networking platforms, and smartphones has enabled organizations to tap into vast amounts of previously unavailable data and combine it with their own internal proprietary data. At the same time, significant progress has been made in fundamental technologies (e.g., elastic cloud computing infrastructure) that enable data management and knowledge discovery technologies that handle terabytes and petabytes of data. Reflecting this industrial reality, the report introduces recent advances in aspects of big data such as the Semantic Web and Linked Data, as well as the fundamentals of inference techniques for tackling big data applications.
This article describes the tutorial papers prepared for the 11th Reasoning Web Summer School (RW 2015) held in Berlin, Germany, from July 31 to August 4, 2015.The 2015 edition of the School was hosted by the Free University of Berlin, Germany, Computer Science The theme for 2015 is “Web Logic Rules” (findings on the Semantic Web, Linked Data, ontologies, rules, and logic).
In this issue, we describe the 12th Reasoning Web Summer School (RW2016) held in Aberdeen, UK, from September 5 to 9, 2016. The content covered knowledge graphs, linked data, semantics, fuzzy RDF, and logical foundations for building and querying OWL knowledge bases.
In this issue, we describe the 13th Reasoning Web, held in London, UK, in July 2017. The theme of this year’s conference was “Semantic Interoperability on the Web” and encompassed themes such as data integration, open data management, reasoning on linked data, mapping databases and ontologies, query answering on ontologies, hybrid reasoning with rules and ontologies, and dynamic ontology-based systems. This issue also focuses on these topics, as well as basic techniques of reasoning used in answer set programming and ontologies.
In this issue, we describe the 14th Reasoning Web, held in Esch-sur-Alzette, Luxembourg, in September 2018. Specifically, we will discuss normative reasoning, a quick survey on efficient search combining text corpora and knowledge bases, large-scale probabilistic knowledge bases, the application of Conditional Random Fields (CRAFs) to knowledge base generation tasks, the use of DBpedia and large cross-domain knowledge graphs such as Wikidata, automatic construction of large knowledge graphs (KGs) and learning rules from knowledge graphs, processing large RDF graphs, developing stream processing applications in a web environment, and reasoning about very large knowledge bases.
In this issue, we describe the 15th Reasoning Web, held in Bolzano, Italy, in September 2019. The topic will be Explainable AI, with a detailed description and analysis of the main reasoning and explanation methods for ontologies using description logic: tableau procedures and axiom pinpointing algorithms, semantic query responses to knowledge bases, data provenancing, entity-centric knowledge base applications, formal concept analysis, an approach to explaining data by lattice theory, learning interpretable models from data, logical problems such as proposition satisfiability, discrete problems such as constraint satisfaction, and learning full-scale mathematical optimization tasks, distributed computing systems, and explainable AI planning will be described.
This issue of Reasoning Web is dedicated to the 16th Reasoning Web, which will be held virtually in June 2020 due to Corona’s influence. The main theme will be “Declarative Artificial Intelligence”. Specifically, I will give an overview of high-level research directions and open problems related to lightweight description logic (DL) ontology explainable AI (XAI), stream inference, solution set programming (ASP), limit datalogs (a recent declarative query language for data analysis), and knowledge graphs. An overview will be given.
In this issue, we describe the 17th Reasoning Web held in Leuven, Belgium in 20219. Specifically, I will discuss fundamentals on querying graph-structured data, reasoning with ontology languages based on description logics and non-monotonic rule languages, combining symbolic reasoning and deep learning, the Semantic Web and knowledge graphs and machine learning, building information modeling (BIM), the Geospatially Linked Open Data, Ontology Evaluation Techniques, Planning Agents, Cloud-based Electronic Health Record (EHR) Systems, COVID Pandemic Management, Belief Revision and its application to Description Logic and Ontology Repair, Temporal Equilibrium Logic (TEL) and its solution Set Programming (ASP), an introduction and review of Shapes Constraint Language (SHACL), a W3C recommended language for RDF data validation, and score-based Explanations will be presented.
This book contains the proceedings of the first three workshops on Uncertainty Reasoning for the Semantic Web (URSW) held at ISWC in 2005, 2006, and 2007. The papers presented here include revised and significantly expanded versions of papers presented at the workshops, as well as invited papers by leading experts in the field and related areas.
This book is the first comprehensive compilation of state-of-the-art research approaches to uncertainty reasoning in the context of the Semantic Web, capturing different models of uncertainty and approaches to deductive and inductive reasoning with uncertain formal knowledge.
This is the second volume on “Uncertainty Reasoning for the Semantic Web” and is the result of the Uncertainty Reasoning for the Semantic Web (URSW) workshops held at the International Semantic Web Conference (ISWC) in 2008, 2009, and 2010. It is a revised and significantly extended version of the paths presented at the workshops on Uncertainty Reasoning for the Semantic Web (URSW) at the International Semantic Web Conference (ISWC) in 2008, 2009, and 2010, and at the First International Workshop on Un- certainty in Description Logics (UniDL) in 2010. This is a revised and significantly expanded version of the paths presented at the 2010 First International Workshop on Un- certainty in Description Logics (UniDL).
The two volumes provide a comprehensive compilation of state-of-the-art research approaches to uncertainty reasoning in the context of the Semantic Web, capturing different models of uncertainty and approaches to inductive reasoning as well as inductive reasoning with uncertain formal knowledge.
Ontology Technology
The term ontology has been used as a branch of philosophy, and according to the wiki, “It is not concerned with the individual nature of various things (beings), but with the meaning and fundamental rules of being that bring beings into existence, and is considered to be metaphysics or a branch of it, along with cognitive theory.
Metaphysics deals with abstract concepts of things, and ontology in philosophy deals with abstract concepts and laws behind things.
On the other hand, according to the wiki, ontology in information engineering is “a formal representation of knowledge as an ordered sequence of concepts and relations among concepts in a domain, used to reason about entities in the domain and to describe the domain. It is used to reason about entities (realities) in the domain and to describe the domain. It is used to reason about entities (realities) in the domain and to describe the domain. It also states that “an ontology is also defined as “a formal and explicit specification of a shared conceptualization” and provides a vocabulary (types of objects and concepts, properties, relations) used to model a domain.
As can be seen from these definitions, philosophical ontology mainly deals with abstract concepts, while ontology in information engineering consists of real-world entities and abstract concepts that model them, and can be said to be a tool for handling real-world data.
Ontology in information engineering has a wide range of applications: it is introduced into artificial intelligence as a knowledge representation and used for various types of reasoning (expert systems, etc.), it links various types of data as the underlying data of SemanticWeb technology, and it is used as a tool for defining requirements in systems engineering and software engineering together with tools such as SysML It is also used in systems engineering and software engineering as a tool for defining requirements with tools such as SysML, and as a tool for organizing information and improving accessibility in areas such as bioinformatics, library and information science, and enterprise information management.
In the following pages of this blog, various topics related to this ontology technology are discussed

コメント