AWS Cloud Service Design Patterns (2)
From the Amazon Web Service Cloud Design Pattern Design Guide.
As cloud computing becomes more prevalent, a major shift is taking place in the procurement and operation of computing resources. The cloud has ushered in a new world of IT by making it possible to procure a wide variety of IT resources instantly and inexpensively, as and when they are needed.
In particular, Amazon Web Service (AWS), which has been providing cloud services since 2006, has evolved dramatically, offering a wide range of infrastructure services, including virtual servers, storage, load balancers, databases, distributed queues, and NoSQL services, at low initial costs. AWS offers a wide variety of infrastructure services such as virtual servers, storage, load balancing, databases, distributed queues, and NoSQL services on an inexpensive pay-as-you-use model with no initial costs. Users can instantly procure and use these highly scalable services as and when they need them, and when they no longer need them, they can immediately dispose of them and no longer pay for them from that moment on.
All of these cloud services are publicly available with APIs, so not only can they be controlled from tools on the web, but users can also programmatically control their infrastructure. Infrastructure is no longer physically rigid and inflexible; it is now software-like, highly flexible and changeable.
By mastering such infrastructure, one can build durable, scalable, and flexible systems and applications more quickly and inexpensively than previously thought possible. In this era of “new service components for the Internet age (=cloud),” those involved in designing system architecture will need a new mindset, new ideas, and new standards. In other words, the new IT world needs architects with new know-how for the cloud era.
In Japan, a cluster of AWS data centers opened in March 2011, and thousands of companies and developers are already using AWS to create their systems. Customers range from individual developers who use infrastructure as a hobby, to startups that quickly launch new businesses, small and medium-sized enterprises that are trying to fight the wave of cost reduction with cloud computing, large enterprises that cannot ignore the benefits of cloud computing, and government agencies, municipalities, and educational institutions.
Use cases for cloud computing range from cloud hosting of typical websites and web applications, to replacing existing internal IT infrastructure, batch processing, big data processing, chemical computation, and backup and disaster recovery. The cloud is being used as a general-purpose infrastructure.
There are already examples of businesses and applications that have taken advantage of the characteristics of the cloud to achieve success as new businesses, new businesses, and new services that were previously unthinkable, as well as examples of existing systems that have been migrated to reduce TCO.
However, we still hear of cases of failed attempts to use the cloud, and unfortunately, there are still not many architectures that take full advantage of the cloud. In particular, there are still few cases in which the unique advantages of cloud computing are fully utilized, such as design for scalability, design for failure, and design with cost advantages in mind.
This section describes the Cloud Design Pattern (CDP), a new architectural pattern for cloud computing.
The CDP is a set of typical problems and solutions that occur when designing architectures for cloud-based systems, organized and categorized so that they can be reused by abstracting the essence of the problems and solutions. The design and operation know-how discovered or developed by architects is converted from tacit knowledge to formal knowledge in the form of design patterns that can be reused.
By using CDP, it is possible to
- By leveraging existing know-how, better architectural designs for cloud-based systems will be possible.
- Architects will be able to talk to each other using a common language.
- The cloud will be more easily understood.
The following CDP patterns were described in the previous article: “Basic Pattern,” “Availability Improvement Pattern,” “Dynamic Content Processing Pattern,” and “Static Content Processing Pattern. In this issue, “Data Upload Pattern,” “Relational Database Pattern,” and “Asynchronous/Batch Processing Pattern” will be discussed, and “Operation and Maintenance Pattern” and “Network Pattern” will be discussed in the next article.
Data Upload Patterns
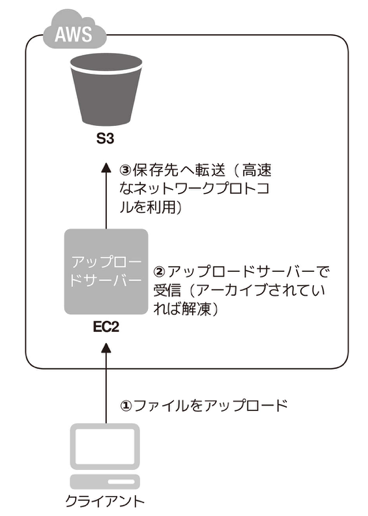
- Write Proxy: Internet storage generally has high capacity and data tolerance for reads. However, since it writes to multiple locations to maintain redundancy and communicates with clients via the HTTP protocol, its write speed is relatively poor, making performance a problem when writing large amounts of data to Internet storage. To address this issue, instead of transferring data directly from the client to the Internet storage, data is received by the virtual server and transferred from the virtual server to the Internet storage. The communication from the virtual server to the Internet storage can be faster (UDP-based) than HTTP, and if there are a large number of small files, they can be archived at the client side, transferred to the virtual server, decompressed, and transferred to the Internet storage. This is also possible.

- Storage Index: Internet storage has high durability and availability because data is distributed. However, since the data is accessed via the Internet, the response performance is generally lower than that of on-premise storage. In addition, advanced search functions are not provided, so applications need to be creative when retrieving a list of data for a specific user or for a certain date range. In contrast, when storing data in Internet storage, meta information is simultaneously stored in KVS, which has high search performance, and the KVS is used for searching, and Internet storage is accessed based on the results obtained.

- Direct Object Upload: On photo and video sharing sites, large data is uploaded by many users. Uploading is a server-side process (especially network load), and even sites of a certain scale require a dedicated virtual server for uploading. Let Internet Storage handle the upload process. In other words, the client uploads directly to the Internet storage without going through the virtual server.

Relational Database Patterns
- DB Replication: The basic way to protect critical data for a system is to store it in a database. In recent years, database replication has become increasingly popular. Replication has traditionally been limited to a single data center from a cost perspective, but in the event of a large-scale disaster, it is now necessary to assume that the entire data center may be damaged. In order to address this issue, replication across regional locations will be implemented.

- Read Replica: When database access frequency is high and DB server resources are tight, server specifications are often increased (i.e., scaled up). When scale-up becomes difficult, scale-out is performed by horizontally distributing DB servers, but this is generally difficult. Since the ratio of reads is usually higher than writes in a database, it is required to first distribute read processing to improve the overall system performance. To address this issue, reads are distributed across multiple “read replicas (read-only replicas)” to improve overall performance.

- Inmemory DB Cache: A large portion of the database load is often related to reads. Therefore, to improve the performance of reading from the database, frequently read data is cached in memory.

- Sharing Write: Speeding up RDBMS writes is a very important and challenging issue. To improve write performance across multiple database servers, “sharding” (basically, preparing databases with the same structure and dividing them into separate databases with appropriate table entanglements as keys to distribute the write process) is used.

Asynchronous processing/batch processing patterns
- Queuing Chain: When multiple systems coordinate their processing to perform sequential processing (e.g., in the case of image processing, sequential processing such as uploading, storing, encoding, and creating thumbnails of images). If the systems are tightly coupled with each other, bottlenecks are likely to occur in terms of performance. In addition, the recovery process in the event of a failure becomes complicated. To address the issue that it is desirable to make the systems as loosely coupled as possible in terms of performance, asynchronous system coordination is achieved by connecting the systems with queues and passing jobs by sending and receiving messages. In this method, the number of virtual servers that receive and process messages can be increased to allow parallel processing, making it easier to eliminate bottlenecks. Even if a virtual server fails, unprocessed messages remain in the queue, making it easier to resume processing as soon as the virtual server is restored.

- Priority Queue: A case in which many batch jobs need to be processed and the jobs have priority. For example, a service that allows users to upload and publish presentation files from a Web browser, where the service level (time to publish) differs between free users and member users, is a case in point. When a user uploads a presentation file, the system performs batch processing to convert the file for publication, and then publishes the converted file. The issue is how to prioritize the batch processing by membership type. To address this issue, a queue is prepared for the number of priorities for managing batch jobs, job requests are managed in the queue, and job requests in the queue are processed by the batch server.

- Job Observer: One method for load balancing batch processing is to manage job requests in a queue and have multiple batch servers process the job requests in the queue in parallel. However, since the number of batch servers to be prepared is limited to match the number of peaks, batch server resources are scarce during off-peak hours, resulting in poor cost efficiency.

- Fanout: In cases where multiple processes need to be executed based on certain data, e.g., after an image is uploaded, three tasks (thumbnail, image recognition, and metadata scanning) need to be executed, each process is called from the application that detects the image upload and is executed sequentially. processing, the total time required for each process would be very long. To address this issue, instead of directly invoking a process from the process that invokes the process, a notification component and a queuing component can be inserted in between to enable asynchronous and parallel processing. The process invoking the process can execute the process after notifying the notifier. In addition, since it is not necessary to know about the process of the recipient, if the number of processes to be notified increases, it can be handled by increasing the number of registrations of recipients to the notification component. In addition, if processes are allocated to each queue, they can be executed in parallel.


コメント