Overview of LLM Fine Tuning by LoRA
LoRA (Low-Rank Adaptation) is a technology related to the fine-tuning of large-scale pre-trained models (LLMs) as described in “Fine-Tuning of Large Language Models and RLHF (Reinforcement Learning from Human Feedback)“. The technology is related to the fine-tuning of large-scale pre-trained models (LLMs), as described in “LoRA: Low-Rank Adaptation of (LoRA: Low-Rank Adaptation of Large Language Models) published by Edward Hu et al. at Microsoft in 2021.
As for LLM fine-tuning, a new feature of ChatGPT, “GPTs,” which allows users to freely customize (and fine-tune) ChatGPT, was released at the end of 2023. It is becoming easier for everyone to fine-tune learned models.
Instead of directly modifying the parameters of the original model, LoRA introduces a low-rank matrix to fix the weights of the pre-trained model and injects a low-rank decomposition matrix into each layer of the transducer architecture, thereby greatly reducing the number of trainable parameters for downstream tasks.
This means, for example, that for the GPT-3 175B model, LoRA reduces the trainable parameters by a factor of 10,000 and reduces the GPU memory requirement by a factor of 3.

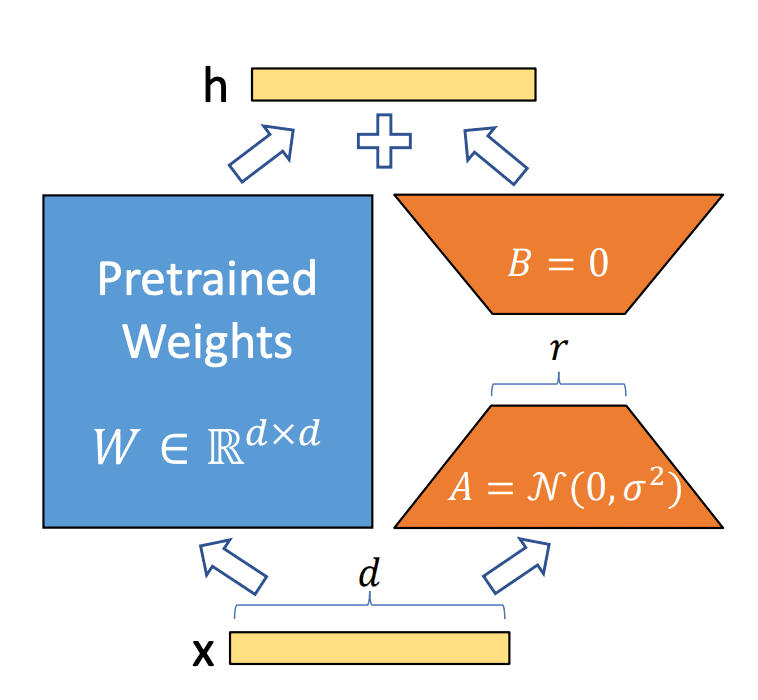
An example of LoRA (Low-Rank Adaptation) calculation is shown in the figure above. Usually, in a transducer model, there is a weight matrix W ( m×n), which is applied to the input x in the form of Wx. In LoRA, instead of changing this weight matrix W directly, the low-rank matrices A (m×k) and B (k×n) are used to perform the transformation in the form W ( m×n)+AB ( m×n). Here, since A and B are small matrices and have far fewer parameters than the original weight matrix W, this method reduces the overall number of parameters and improves the efficiency of the calculation. A specific calculation example is shown below.

The number of parameters for the weight matrix W is reduced by a factor of 3 to a total of 24, while the number of parameters to be adjusted for matrices A and B is reduced by a factor of 8.
Overview of LoRA Applications and Google Colab
<Overview of LoRA Application>
HuggingFace, described in the “Overview of Automatic Sentence Generation with HuggingFace” section, provides a library: PEFT (Parameter-Efficient Fine-Tuning), which implements LoRA, PromptTuning, AdaLoRA, etc. PEFT (Parameter-Efficient Fine-Tuning).
Regarding PEFT, there are three main approaches
- Token-additive: Learning features specific to a particular task by adding virtual tokens to the input layer. The parameters of the pre-trained model itself are not updated but frozen. Three approaches have already been implemented in Huggingface: Prefix Tuning, P Tuning, and Prompt Tuning.
- Adapter type: add a special sub-module outside the pre-trained model and update its parameters; update the parameters of the Adapter and freeze the parameters of the original pre-trained model; update the parameters of the Adapter and freeze the parameters of the original pre-trained model; update the parameters of the Adapter and freeze the parameters of the original pre-trained model. Applicable for language understanding and text translation/summarization tasks; not included as a PEFT library in Huggingface.
- LoRA type: The pre-trained model itself is frozen and only the low-rank matrix is updated. After updating the low-rank matrix, the weights of the original pre-trained model are added and the parameters are updated. LoRA and Ada LoRA are implemented in Huggingface’s PEFT library. LoRA enables efficient fine tuning not only for language tasks but also for image tasks, making it an approach with a very broad range of applications.
The following is a description of the procedure for LoRA fine tuning using PEFT.
- Prepare a model that will serve as the base model
- Replace some of the layers of the base model with LoRA layers
- Fix the layers other than the LoRA layer
- Train only the LoRA part
<Google Colab>
LLM calculations require computer resources, and the simplest approach to attempting code is to use Google Colab, a cloud-based Jupyter notebook environment provided by Google. Google Colab is a cloud-based Jupyter notebook environment provided by Google, and is a development environment that can perform calculations using the resources of Google’s servers. To use this environment, you need to have a google account. The procedure for setting up the development environment is shown below.
- Access Google Colab with a Google account.
- When you access the Google Colab homepage, you will see a button to create a new notebook. Click on it or select File -> New Notebook from the menu to create a new notebook.
- Click on Runtime in the menu at the top of the created notebook and make the following settings
- Change Runtime Type: Click on Change Runtime Type and select the Python version, GPU settings to use, etc. Normally, select Python 3.
- Hardware Accelerator: Select Hardware Accelerator to use a free GPU or TPU. Typically, select GPU.
- Google Colab installs Python packages with ! prefix to execute shell commands. For example, the following will install the library. (ctrl-CR or click on ▶️ next to the code)
!pip install pandas
- Google Colab allows integration with Google Drive. Google Drive can be mounted by executing the following code.
from google.colab import drive
drive.mount('/content/drive')
- Implement and execute the code.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# Loading Data
url = 'https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv'
df = pd.read_csv(url)
# Data Preprocessing
df.dropna(inplace=True)
X = df[['Pclass', 'Age', 'SibSp', 'Parch', 'Fare']]
y = df['Survived']
# Data Division
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Model Definition and Learning
model = LogisticRegression()
model.fit(X_train, y_train)
# Prediction and evaluation on test data
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
Fine Tuning with PEFT using Google Colab
See code in “Try Fine Tuning Large Language Models with PEFT in Google Colab.”
Install the package.
# Installing packages
!pip install -q bitsandbytes datasets accelerate loralib
!pip install -q git+https://github.com/huggingface/transformers.git@main git+https://github.com/huggingface/peft.git
Loading model. Load “OPT-6.7B”. The weight is about 13 GB for half-precision (float16), and about 7 GB of memory is required when reading in 8-bit.
# Loading the model
import os
os.environ["CUDA_VISIBLE_DEVICES"]="0"
import torch
import torch.nn as nn
import bitsandbytes as bnb
from transformers import AutoTokenizer, AutoConfig, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"facebook/opt-6.7b",
load_in_8bit=True,
device_map='auto',
)
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-6.7b")Post-processing is applied to the 8-bit model. Post-processing must be applied to the 8-bit model for learning to be valid. Freeze all layers, cast the layer norm to float32 to stabilize it, and for the same reason also cast the output of the last layer of float32.
for param in model.parameters():
param.requires_grad = False # Freeze model
if param.ndim == 1:
# Cast layer norm to fp32 for stability
param.data = param.data.to(torch.float32)
model.gradient_checkpointing_enable()
model.enable_input_require_grads()
class CastOutputToFloat(nn.Sequential):
def forward(self, x): return super().forward(x).to(torch.float32)
model.lm_head = CastOutputToFloat(model.lm_head)Load PeftModel, specifying in config that LoRA is to be used.
def print_trainable_parameters(model):
"""
Output the number of trainable parameters in the model
"""
trainable_params = 0
all_param = 0
for _, param in model.named_parameters():
all_param += param.numel()
if param.requires_grad:
trainable_params += param.numel()
print(
f"trainable params: {trainable_params} || all params: {all_param} || trainable%: {100 * trainable_params / all_param}"
)
from peft import LoraConfig, get_peft_model
config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, config)
print_trainable_parameters(model)Running the training. The training data is “Abirate/english_quotes” (quotes by great people). 40 minutes.
import transformers
from datasets import load_dataset
data = load_dataset("Abirate/english_quotes")
data = data.map(lambda samples: tokenizer(samples['quote']), batched=True)
trainer = transformers.Trainer(
model=model,
train_dataset=data['train'],
args=transformers.TrainingArguments(
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
warmup_steps=100,
max_steps=200,
learning_rate=2e-4,
fp16=True,
logging_steps=1,
output_dir='outputs'
),
data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False)
)
model.config.use_cache = False # Silence warning. Re-enable for inference.
trainer.train()Performing inferences.” Infer the words following “Two things are infinite:
batch = tokenizer("Two things are infinite: ", return_tensors='pt')
with torch.cuda.amp.autocast():
output_tokens = model.generate(**batch, max_new_tokens=50)
print('nn', tokenizer.decode(output_tokens[0], skip_special_tokens=True))For reference, the Quick Start on PEFT’s GitHub page is as follows
pip install peft
Wrap the base model and PEFT settings with get_peft_model to prepare the model to be trained with a PEFT method such as LoRA.
from transformers import AutoModelForSeq2SeqLM
from peft import get_peft_config, get_peft_model, LoraConfig, TaskType
model_name_or_path = "bigscience/mt0-large"
tokenizer_name_or_path = "bigscience/mt0-large"
peft_config = LoraConfig(
task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1
)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
"trainable params: 2359296 || all params: 1231940608 || trainable%: 0.19151053100118282"Load the PEFT model for inference:
from peft import AutoPeftModelForCausalLM
from transformers import AutoTokenizer
import torch
model = AutoPeftModelForCausalLM.from_pretrained("ybelkada/opt-350m-lora").to("cuda")
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
model.eval()
inputs = tokenizer("Preheat the oven to 350 degrees and place the cookie dough", return_tensors="pt")
outputs = model.generate(input_ids=inputs["input_ids"].to("cuda"), max_new_tokens=50)
print(tokenizer.batch_decode(outputs, skip_special_tokens=True)[0])
"Preheat the oven to 350 degrees and place the cookie dough in the center of the oven. In a large bowl, combine the flour, baking powder, baking soda, salt, and cinnamon. In a separate bowl, combine the egg yolks, sugar, and vanilla."Application of fine tuning of LLM by LoRA
As for the use of LoRA, fine tuning of image systems is currently booming. In particular, there are many articles online about combining with Stable Diffusion described in “Stable Diffusion and LoRA Applications“.” What is LoRA (LoRA)|Trying out image generation AI (Stable Diffusion) fine tuning, which is a hot topic this year“, “[Stable Diffusion Web UI] How to use LoRA, an additional learning model“, “What is LoRA? Stable Diffusion”
Customized Chatbots: Companies can use LoRA to create their own chatbots from large LLMs by learning their own resources. Chatbots that can conduct Q&A unique to the company are used.
AI Photo Album: LoRA can be used to generate specific images such as “Asian Woman” by fine tuning the underlying model, Stable Diffusion. AI-generated image “photo books” have been dominating Amazon.co.jp’s “Kindle Unlimited” e-book reading service, becoming a social phenomenon as they have become a hot topic on social networking sites and reported on by news sites one after another. The evolution of AI-generated images has created a new wave in the photogravure industry, producing realistic-looking images of models that do not actually exist.
AI model: The company’s own brand of fashion items can be learned and worn by AI models. AI model, Inc. launched its “AI model model photo shooting service” on June 14, 2022. AI model can create exclusive models for brands tailored to EC customers, while avoiding the risks associated with human resources, such as securing shooting locations and costs, and scandals involving the talent and models used.
Reference Information and Reference Books
Reference books “


コメント