Introduction
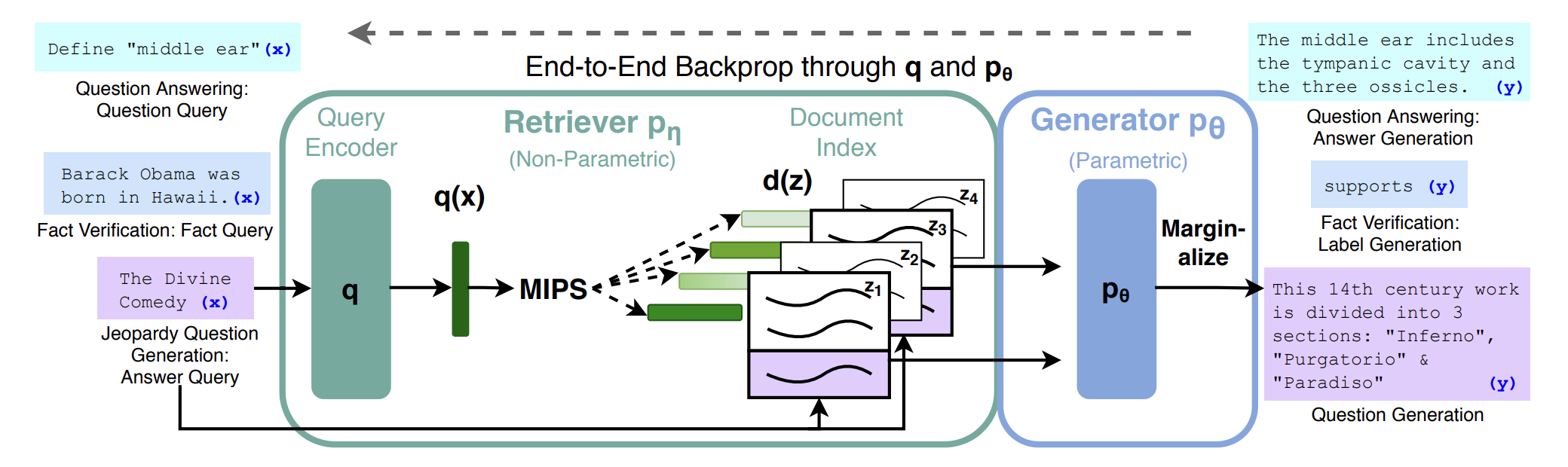
The basic structure of RAG described in “Overview of RAG (Retrieval-Augmented Generation) and examples of its implementation” is to vectorize input Query with Query Encoder, find Documnet with similar vectors, and generate responses using them. The vector DB is used to store the vectorized documents and to search for similar documents.

Among these functions, for generative AI, it is common to use ChatGPT’s API or LanChain as described in “Overview of ChatGPT and LangChain and their use,” and for databases, “Overview of Vector Databases” should be used.
In this article, we describe a concrete implementation using these databases.
Data vectorization (embedding) using CahtGPT and LangChain
Embedding is a technique for converting complex data, mainly words, sentences (text), images, and audio, into numerical vector representations that can be easily processed by AI, machine learning, and language models. These techniques have been utilized with the emergence of deep learning, and have been used in the past with “autoencoders” and more recently with the Transformer described in “Overview of the Transformer Model, Algorithms, and Examples of Implementations. Transformer model.
<embedding and similarity calculation using ChatGPT>
ChatGPT can easily embed data via API by specifying embedding model as described in “Overview of ChatGPT and LangChain and its use“. are currently available for embedding in openAI. (text-embedding-3-small, text-embedding-3-large, and text-embedding-ada-002), each of which has a different model size, with text-embedding-3-small<text-embedding-ada 002<text-embedding-3-large, in that order.
Sample code is shown below.
import os
os.environ["OPENAI_API_KEY"] = "Your OpenAPI Key"
from openai import OpenAI
client = OpenAI()
def get_embedding(text, model="text-embedding-3-small"):
text = text.replace("n", " ")
return client.embeddings.create(input = [text], model=model).data[0].embedding
text = "porcine pals"
print(len(get_embedding(text)))
print(get_embedding(text))
When the above code is executed, the number of dimensions is “1536” and a vector of 1536 dimensions is displayed.
The similarity of the vectors created in this way is judged by comparing them with the various algorithms described in “Similarity in Machine Learning“.
A sample code for cosine similarity is shown below.
import numpy as np
def cosine_similarity(vec1, vec2):
dot_product = np.dot(vec1, vec2)
norm_vec1 = np.linalg.norm(vec1)
norm_vec2 = np.linalg.norm(vec2)
similarity = dot_product / (norm_vec1 * norm_vec2)
return similarity
# Define two vectors as examples
vector1 = np.array(get_embedding("Document1"))
vector2 = np.array(get_embedding("Document2"))
# Calculation of Cosine Similarity
similarity = cosine_similarity(vector1, vector2)
print(f"コサイン類似度: {similarity}")Using this, the similarity between “Steak is good” and “Coffee is bitter” is calculated as “0.21275942216209356”. After that, RAG can be realized by outputting search results by combining various indexes and rankings as described in “Overview of Ranking Algorithms and Examples of Implementation“.
<RAG using LangChain>
Using LangChain, described in “Overview of ChatGPT and LangChain and its use“, these can be implemented in a simpler way.
First of all, an example of reading a text document (pdf) as a preprocessing step is shown below. (It is necessary to “pip install pymupdf” library in advance.)
from langchain.document_loaders import PyMuPDFLoader
loader = PyMuPDFLoader("./sample.pdf") #← Read ample.pdf
documents = loader.load()
print(f"number of document: {len(documents)}") #← Check the number of documents
print(f"Contents of the first document: {documents[0].page_content}") #← Review the contents of the first document.
print(f"Metadata for the first document: {documents[0].metadata}") #← Check the metadata of the first documentNext, when documents are retrieved from PDF, there are cases where they are too long to process, so split them up using spaCy library, etc. (pip install spacy)
from langchain.document_loaders import PyMuPDFLoader
from langchain.text_splitter import SpacyTextSplitter #← Import SpacyTextSplitter
loader = PyMuPDFLoader("./sample.pdf")
documents = loader.load()
text_splitter = SpacyTextSplitter( #← Initialize SpacyTextSplitter
chunk_size=300, #← Set the size to be divided
pipeline="ja_core_news_sm" #← Set language model to be used for division
)
splitted_documents = text_splitter.split_documents(documents) #← Split a document
print(f"Number of documents before splitting: {len(documents)}")
print(f"Number of documents after splitting: {len(splitted_documents)}")These divided documents are then embedded and stored in a database. The database used here is one specialized for vector data handling, as described in “Overview of Vector Databases“. Here, the open source Chroma is used. Install tiktoken, a library for embedding, and chromadb, a database library. (pip install tiktoken chromadb)
from langchain.document_loaders import PyMuPDFLoader
from langchain.embeddings import OpenAIEmbeddings #← Import OpenAIEmbeddings
from langchain.text_splitter import SpacyTextSplitter
from langchain.vectorstores import Chroma #← Import Chroma
loader = PyMuPDFLoader("./sample.pdf")
documents = loader.load()
text_splitter = SpacyTextSplitter(
chunk_size=300,
pipeline="ja_core_news_sm"
)
splitted_documents = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings( #← Initialize OpenAIEmbeddings
model="text-embedding-ada-002" #← Specify model name
)
database = Chroma( #← Initialize Chroma
persist_directory="./.data", #← Specify where to store the persistent data
embedding_function=embeddings #← Specify model to vectorize
)
database.add_documents( #← Add document to database
splitted_documents, #← Documents to be added
)
print("Database creation is complete.") #← Notify completionFinally, the query is vectorized and searched in the vector database.
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
embeddings = OpenAIEmbeddings(
model="text-embedding-ada-002"
)
database = Chroma(
persist_directory="./.data",
embedding_function=embeddings
)
documents = database.similarity_search("your query text") #← Retrieve highly similar documents from the database
print(f"Number of documents: {len(documents)}") #← display Number of documents
for document in documents:
print(f"Document Content: {document.page_content}") #← display Document ContentFurthermore, by using “GPT-4 Turbo with Vision on Azure OpenAI Service“, image data can also be vectorized for multimodal search.
Reference Information and Reference Books



AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.

コメント