イントロダクション
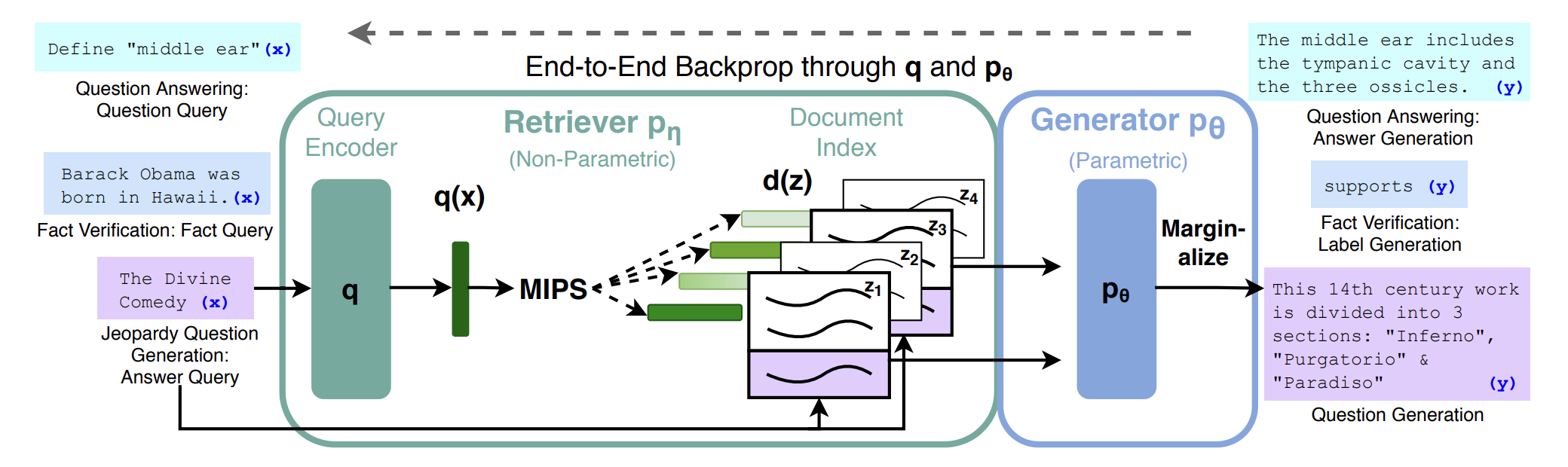
“RAG(Retrieval-Augmented Generation)の概要とその実装例について“でも述べているRAGの基本構成は、入力QueryをQuery Encoderでベクトル化し、それと類似のベクトルを持つDocumnetを見つけ、それらを使って応答を生成するもので、Query EncoderとDocumentのベクトル化と、回答の生成に生成系AI(ChatGPT)を用い、ベクトル化したDocumentの格納と類似文書の検索にはベクトルDBを用いるものとなる。

それらの機能の中で、生成系AIに関しては”ChatGPTとLangChainの概要及びその利用について“に述べているように、ChatGPTのAPIを用いるかLanChainを用い、データベースに関しては”ベクトルデータベースの概要について“を用いることが一般的となる。
今回はそれらを用いた具体的な実装について述べる。
CahtGPT及びLangChainを用いたデータのベクトル化(エンべディング)
主に単語や文章(テキスト)、画像、音声などの複雑なデータを、AI/機械学習/言語モデルが処理しやすい数値ベクトル表現に変換する技術をエンベディング(Embedding)と呼ぶ。これらは、深層学習の登場と共に活用されており、古くは”オートエンコーダー“から、近年は”Transformerモデルの概要とアルゴリズム及び実装例について“で述べているTransformer等を用いて容易に行うことができる。
<ChatGPTを用いたembeddingと類似度計算>
“ChatGPTとLangChainの概要及びその利用について“で述べているChatGPTではエンべディングモデルを指定することで、API経由で容易にデータをエンべディングすることができる。openAIのembeddingでは現在3種類のembeddingが利用できる。(text-embedding-3-small、text-embedding-3-large、text-embedding-ada-002)それぞれモデルの大きさが異なり、text-embedding-3-small<text-embedding-ada-002<text-embedding-3-largeの順で料金が安くなる。
以下にサンプルコードを示す。
import os
os.environ["OPENAI_API_KEY"] = "Your OpenAPI Key"
from openai import OpenAI
client = OpenAI()
def get_embedding(text, model="text-embedding-3-small"):
text = text.replace("\n", " ")
return client.embeddings.create(input = [text], model=model).data[0].embedding
text = "porcine pals"
print(len(get_embedding(text)))
print(get_embedding(text))
上記のコードを実行すると、次元数「1536」と、1536次元のベクトルが表示される。
このようにして作成したベクトルの類似度を”機械学習における類似度について“で述べている様々なアルゴリズムで比較することで判定を行う。
以下にコサイン類似度のサンプルコードを示す。
import numpy as np
def cosine_similarity(vec1, vec2):
dot_product = np.dot(vec1, vec2)
norm_vec1 = np.linalg.norm(vec1)
norm_vec2 = np.linalg.norm(vec2)
similarity = dot_product / (norm_vec1 * norm_vec2)
return similarity
# 例として2つのベクトルを定義
vector1 = np.array(get_embedding("文章1"))
vector2 = np.array(get_embedding("文章2"))
# コサイン類似度の計算
similarity = cosine_similarity(vector1, vector2)
print(f"コサイン類似度: {similarity}")これを使うと”Steak is good”と”Coffee is bitter”の類似度は”0.21275942216209356“のように計算される。後は”ランキングアルゴリズムの概要と実装例について“で述べられている様々な指標とランキングを組み合わせて検索結果を出力するとRAGが実現できる。
<LangChainを用いたRAG>
“ChatGPTとLangChainの概要及びその利用について“で述べているLangChainを用いることで、これらをもう少しシンプルに実装することができる。
まず前処理としてテキスト文書(pdf)を読み取る実装例は以下のようになる。(pymupdfというライブラリを事前に”pip install pymupdf”する必要がある)
from langchain.document_loaders import PyMuPDFLoader
loader = PyMuPDFLoader("./sample.pdf") #← sample.pdfを読み込む
documents = loader.load()
print(f"ドキュメントの数: {len(documents)}") #← ドキュメントの数を確認する
print(f"1つめのドキュメントの内容: {documents[0].page_content}") #← 1つめのドキュメントの内容を確認する
print(f"1つめのドキュメントのメタデータ: {documents[0].metadata}") #← 1つめのドキュメントのメタデータを確認する次に文書をPDFから取得した場合、長すぎて処理できないケースがあるため、spaCyライブラリ等を用いて分割する(pip install spacy)
from langchain.document_loaders import PyMuPDFLoader
from langchain.text_splitter import SpacyTextSplitter #← SpacyTextSplitterをインポート
loader = PyMuPDFLoader("./sample.pdf")
documents = loader.load()
text_splitter = SpacyTextSplitter( #← SpacyTextSplitterを初期化する
chunk_size=300, #← 分割するサイズを設定
pipeline="ja_core_news_sm" #← 分割に使用する言語モデルを設定
)
splitted_documents = text_splitter.split_documents(documents) #← ドキュメントを分割する
print(f"分割前のドキュメント数: {len(documents)}")
print(f"分割後のドキュメント数: {len(splitted_documents)}")それら分割した文書をエンべディングして、データベースに格納する。ここで利用するデータベースは”ベクトルデータベースの概要について“で述べているベクトルデータのハンドリングに特化されたものを使う。ここではオープンソースのChromaを利用する。エンべディングのためのライブラリtiktokenとデータベースのライブラリchromadbをインストールしておく。(pip install tiktoken chromadb)
from langchain.document_loaders import PyMuPDFLoader
from langchain.embeddings import OpenAIEmbeddings #← OpenAIEmbeddingsをインポート
from langchain.text_splitter import SpacyTextSplitter
from langchain.vectorstores import Chroma #← Chromaをインポート
loader = PyMuPDFLoader("./sample.pdf")
documents = loader.load()
text_splitter = SpacyTextSplitter(
chunk_size=300,
pipeline="ja_core_news_sm"
)
splitted_documents = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings( #← OpenAIEmbeddingsを初期化する
model="text-embedding-ada-002" #← モデル名を指定
)
database = Chroma( #← Chromaを初期化する
persist_directory="./.data", #← 永続化データの保存先を指定
embedding_function=embeddings #← ベクトル化するためのモデルを指定
)
database.add_documents( #← ドキュメントをデータベースに追加
splitted_documents, #← 追加するドキュメント
)
print("データベースの作成が完了しました。") #← 完了を通知する最後にクエリをベクトル化し、ベクトルデータベースで検索する。
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
embeddings = OpenAIEmbeddings(
model="text-embedding-ada-002"
)
database = Chroma(
persist_directory="./.data",
embedding_function=embeddings
)
documents = database.similarity_search("クエリ文を入力") #← データベースから類似度の高いドキュメントを取得
print(f"ドキュメントの数: {len(documents)}") #← ドキュメントの数を表示
for document in documents:
print(f"ドキュメントの内容: {document.page_content}") #← ドキュメントの内容を表示さらに、”GPT-4 Turbo with Vision on Azure OpenAI Service“等を用いることで、画像データもベクトル化してマルチモーダル検索することも可能となる。
参考情報と参考図書

“


AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.
