RAG(Retrieval-Augmented Generation)の概要
RAG(Retrieval-Augmented Generation)は、自然言語処理(NLP)の分野で注目されている技術の1つであり、情報の検索(Retrieval)と生成(Generation)を組み合わせることで、より豊かなコンテキストを持つモデルを構築する手法となる。これは2021年に出された”Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks“に由来する技術となる。
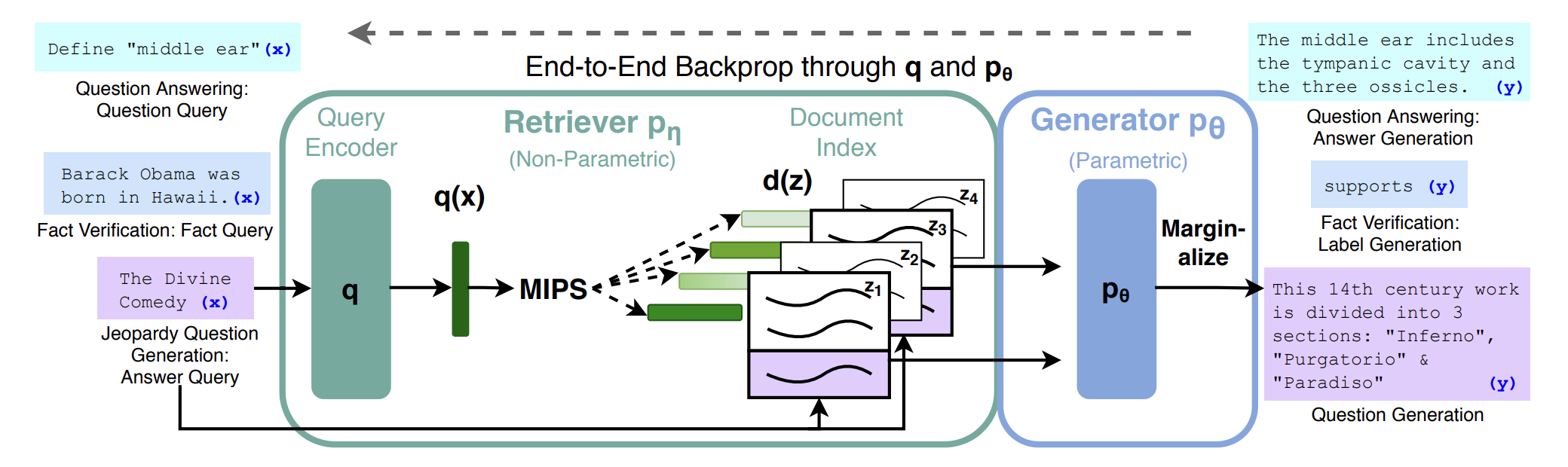
RAGの構成は以下のようになる(上述の論文より)。

基本構成としては、入力QueryをQuery Encoderでベクトル化し、それと類似のベクトルを持つDocumnetを見つけ、それらを使って応答を生成するもので、Query EncoderとDocumentのベクトル化と、回答の生成に生成系AI(ChatGPT)を用い、ベクトル化したDocumentの格納と類似文書の検索にはベクトルDBを用いるものとなる。
RAGの主な目的は、生成タスク(文章生成、質問応答など)において、検索された情報を活用してより質の高い結果を生成することであり、通常の言語モデルは、与えられたコンテキストのみを考慮して生成を行うが、RAGは外部の情報を取り込むことで、より幅広い知識や文脈を利用することができるという特徴がある。
RAGは、次の3つの主要な構成要素から成り立っている。
1. 情報検索(Retrieval): RAGは、与えられた質問やコンテキストに関連する情報を検索するための機構を持っている。検索する手法としては”検索技術について“に述べているような様々なアプローチが利用可能だが、近年最も利用されているアプローチとしては、検索対象データを”多言語エンベディングの概要とアルゴリズム及び実装について“でも述べているエンべディングと呼ばれる手法でベクトル化し、”ベクトルデータベースの概要について“で述べているベクトルデータベースに格納、”機械学習における類似度について“で述べているコサイン類似度などの指標を用いて情報を検索する。
2. ランキング(Ranking): 情報検索の結果から、最も適切な文脈や情報を選択するためのランキングが行われる。検索された情報の中から、生成タスクに最も適した情報を見つけることが重要となる。
3. 生成(Generation): 最終的に、情報検索とランキングを基に、モデルは生成タスク(文章の生成、質問応答の回答など)を行う。これは選択された情報を元に、より適切で自然な文を生成することが目的となる。
RAGの利点は、外部の情報源からの検索により、モデルはより広範囲な知識や文脈を取得できる”豊富なコンテキストの活用“や、ランキングにより、生成に利用する情報の品質を高めることができる”信頼性の向上“、様々な情報源から情報を取得し、柔軟な生成を可能にする”多様性と適応性“にある。
RAGは、質問応答、情報検索、対話システム、文章生成などのNLPタスクに広く応用されており、特に、大規模な知識ベースを利用した対話システムや、検索結果に基づく質問応答システムなどで効果を発揮している。
RAG(Retrieval-Augmented Generation)に関連するアルゴリズムについて
以下に、RAGに関連するアルゴリズムや手法について述べる。
1. 情報検索(Retrieval)のアルゴリズム: RAGの最初のステップは、与えられた入力に関連する情報を外部のデータソースから検索することとなる。情報検索に関連するアルゴリズムや手法には、以下のようなものがある。情報検索のベースとなる類似性の判定は、”機械学習における類似度について“も参照のこと。
TF-IDF(Term Frequency-Inverse Document Frequency): 単語の出現頻度と逆文書頻度を考慮して、文書間の類似度を計算し、検索クエリと文書の類似度を基に、最も関連性の高い文書を取得する。
BM25(Best Matching 25): 文書内の単語の出現に基づいて、文書間の類似度を計算し、検索クエリと文書の類似度を考慮して、検索結果をランク付けする。
Neural Retrieval Models: ニューラルネットワークを用いた情報検索モデルもあり、TransformerベースのアーキテクチャやBERT(Bidirectional Encoder Representations from Transformers)を用いた検索モデルが一般的となる。
2. ランキング(Ranking)のアルゴリズム: 情報検索で取得した候補文書や情報を、生成タスクに適した順序でランク付けすることが重要であり、この際に使用されるアルゴリズムや手法には、以下のようなものがある。ランキングアルゴリズムで有名なものに”ページランクアルゴリズムの概要と実装“で述べているページランクがある。ランキングアルゴリズムの概要は、”ランキングアルゴリズムの概要と実装例について“も参照のこと。
Learning to Rank: ランキングモデルを学習することで、検索結果を適切にランク付けする。 ニューラルネットワークやランダムフォレストなどの手法が使用されます。
BM25F: BM25の拡張バージョンで、複数のフィールド(タイトル、本文など)の情報を考慮する。 情報の重み付けを行い、総合的なスコアを計算する。
BERT-based Ranking Models: BERTなどの言語モデルを用いたランキングモデルがあり、テキストの意味や文脈を考慮したランキングを実現する。
3. 生成(Generation)のアルゴリズム: 情報検索とランキングを基に、最終的な生成タスク(文章の生成、質問応答の回答など)を行う。ここで使用されるアルゴリズムや手法には、以下のようなものがある。詳細は”機械学習による自動生成“も参照のこと。
Transformer-based Models: GPT-3、GPT-4、BERT、T5など、Transformerアーキテクチャをベースにした言語モデルが使用される。文章を生成するためのパラメータを学習し、文脈を考慮した自然な生成を行う。
Template-based Generation: 事前に定義されたテンプレートを使用して、情報を組み合わせて文を生成する手法となる。テンプレートを埋めることで、適切な回答や文章を生成する。
Controlled Text Generation: 特定の条件やスタイルに従ってテキストを生成する手法となる。モデルに制約やガイドを与え、生成結果を制御している。
4. End-to-End Approach: RAGでは、情報検索、ランキング、生成という一連のステップを組み合わせてエンドツーエンドでタスクを実行している。このため、これらのアルゴリズムや手法が統合されてモデルが構築されている。これらを統合ツールの代表的なものとして”ChatGPTとLangChainの概要及びその利用について“や”LangChainにおけるAgentとToolについて“に述べているLamgChainがある。
RAG(Retrieval-Augmented Generation)の適用事例について
以下に、RAGの適用事例について述べる。
1. 質問応答(QA)システム: RAGは、質問応答システムにおいて効果的に活用されており、与えられた質問に対して、外部の情報源から関連情報を検索し、その情報を元に回答を生成する。具体的には以下のような応用例がある。
医療QA:患者の症状に基づいて適切な診断を行うための質問応答システム。
教育QA:学習者が理解しやすい説明を提供するための質問応答システム。
2. 対話システム: 対話システムにおいても、RAGは自然で豊かな対話を実現するために利用されている。RAGを用いることで、外部の知識ベースやコーパスから情報を取得し、対話の流れを補強する。具体的には以下のような応用例がある。
カスタマーサポート:顧客の質問や問題に対して、より正確で詳細な回答を提供する対話システム。
仮想アシスタント:ユーザーの要求やクエリに対して、豊富な情報を持つ対話エージェント。
3. 文章生成と要約: RAGは、与えられたコンテキストや質問に基づいて、より具体的で的確な文章の生成や要約を行うためにも利用されている。具体的な応用例としては以下のようなものがある。
ニュース記事の要約:大量のニュース記事から、要約や要点を生成するシステム。
レポートの生成:入力されたデータや情報から、詳細なレポートや説明文を生成するシステム。
4. 情報検索とドキュメントリライト: RAGは、情報検索と情報のリライト(再構成)を組み合わせて、情報の再利用や提供を行うシステムにも利用されている。具体的な応用例としては以下のようなものがある。
文章のリライト:入力された文章をリライトし、異なる視点やスタイルで情報を提供するシステム。
文書の類似性検索:与えられたクエリに対して、類似した内容の文書を検索するシステム。
5. ナレッジベースの構築と更新: RAGは、外部の情報源から情報を取得し、ナレッジベースを構築・更新する際にも活用されている。RAGを用いることで、情報の取得から生成までの一連のプロセスを自動化し、ナレッジベースの品質向上を図ることができる。具体的な応用例としては以下のものがある。
企業のナレッジベース:企業内の情報や手順を収集し、従業員や顧客向けに提供するナレッジベースの構築。
教育機関の教材作成:教科書や論文から情報を取得し、新しい教材やコンテンツを生成するシステム。
RAGは、外部の情報を活用してより豊かなコンテキストを持つ言語モデルを実現し、さまざまな自然言語処理タスクにおいて効果的な解決策を提供している。
RAG(Retrieval-Augmented Generation)の実装例について
RAG(Retrieval-Augmented Generation)の実装例は、自然言語処理(NLP)の分野でさまざまな形で展開されており、以下に具体的なRAGの実装例について述べる。
1. DPR(Dense Passage Retrieval)とHugging Face Transformersを用いたRAG: Hugging Faceは、Transformerベースの言語モデルを提供するフレームワークであり、DPR(Dense Passage Retrieval)は情報検索のためのモデルとなる。これらを組み合わせてRAGを実装することが可能となる。以下にそれらの手順について述べる。
1. DPRを使用して、外部のコーパスから関連するパッセージを検索する。
2. 検索されたパッセージをHugging Faceの言語モデル(例えばGPT-3やBARTなど)に入力し、生成タスクを行う。
3. ランキングされたパッセージと生成された文を組み合わせて、最終的な回答や文章を生成する。
詳細は”DPRとHugging Face Transformerを用いたRAGの概要と実装“も参照のこと。
2. Facebook RAG: Facebook AI Researchが提供するRAGの実装で、これは、情報検索と生成を組み合わせたモデルであり、検索されたパッセージを元に文の生成を行うものとなる。
3. T5X-RETRIVAL: T5X-RETRIEVALは、google-researchによって提案されたRAGの実装となる。これは、T5(Text-To-Text Transfer Transformer)と情報検索を組み合わせたモデルになる。
4. 自作のRAGモデルの実装例 : 独自のRAGモデルを実装する場合、”ChatGPTとLangChainの概要及びその利用について“に述べているように、ChatGPTのAPIを用いるかLanChainを用いる方法が一般的となる。一般的な手順は次のようになる。
1. 外部の情報源から必要な情報を収集し、エンべディングしてベクトルデータベースに格納する。
2. ユーザーの質問をエンべディングし、ベクトルデータベースから類似の情報を抽出し、ランキングした中から回答用のデータをピックアップする。
3.ピックアップしたデータを元に、最終的な回答や文章の生成を行う。
詳細は”ChatGPTやLanChainを用いたRAGの概要と実装例について“を参照のこと。
RAG(Retrieval-Augmented Generation)の課題と対応策について
RAG(Retrieval-Augmented Generation)は、情報検索と生成を組み合わせることで豊かなコンテキストを持つモデルを構築する手法だが、その実装や適用にはいくつかの課題が存在している。以下に、RAGの課題とそれに対する対応策について述べる。
1. 情報検索の精度と効率:
課題: RAGの性能は、情報検索段階で取得した文書やパッセージの品質に大きく依存し、大規模なデータセットから関連性の高い情報を効率的かつ正確に取得する必要がある。
対応策:
改良された情報検索手法:TF-IDF、BM25、Neural Retrieval Modelsなどの最新の情報検索手法を使用して、関連性の高い文書やパッセージを取得する。
適切な情報源の選択:タスクやデータに応じて、最適な情報源(ウェブコーパス、専門的な文書、知識ベースなど)を選択する。
キャッシュやプリロード:頻繁に利用される情報はキャッシュしたり、事前に取得しておくことで検索の効率を向上させる。
2. ランキングの適切な調整:
課題: 情報検索段階で取得した複数の文書やパッセージの中から、最適な情報をランキングすることが重要で、ランキング手法の適切な調整やモデルの学習が必要となる。
対応策:
学習可能なランキングモデル:ランキングモデルを機械学習で学習し、最適な情報を選択する能力を向上させる。
人手によるフィードバック:人間の判断を取り入れて、ランキング手法を改善する。
ダイバーシティの確保:多様性を考慮したランキング手法を採用し、異なる視点や情報源を反映させる。
3. モデルの大規模性と処理時間:
課題: RAGは大規模な言語モデルと情報検索モデルを組み合わせた複雑なシステムであり、処理に時間とリソースがかかる。
対応策:
モデルの最適化:モデルの軽量化や高速化を行い、処理速度を向上させる。
並列処理の活用:GPUや分散処理を活用して、並列化による処理速度の向上を図る。
キャッシュやプリロード:一部の情報は事前に取得しておき、再利用することで処理時間を削減する。
4. 説明性と透明性の確保:
課題: RAGが生成した回答や文の根拠や理由を説明することが困難な場合がある。モデルの内部動作がブラックボックスであり、透明性が不足していることが主な原因となる。
対応策:
解釈可能なAI技術の導入:モデルの動作や重要な情報を可視化する技術を導入し、説明性を向上させる。
根拠の抽出:生成された回答に対して、根拠となる文や情報を抽出する手法を導入する。
透明性の向上のための研究:”説明できる機械学習の様々な手法と実装例について“等で述べているAIの透明性と説明性に関する技術を導入する。
5. データのバイアスとドメイン適応:
課題: RAGの訓練データにはバイアスが含まれる可能性があり、特定のドメインに固有の問題を引き起こし、新しいドメインやタスクへの適応が難しい場合がある。
対応策:
データのバイアス検出と修正:バイアスを検出し、データセットを修正することで、公平性や偏りのない回答を生成する。
ドメイン適応手法の使用:”転移学習の概要とアルゴリズムおよび実装例について“でも述べている転移学習やドメイン適応手法を使用して、新しいドメインやタスクに適応させる。
データの多様性の確保:さまざまなドメインやジャンルからのデータを用いてモデルを訓練し、汎用性を高める。
参考情報と参考図書
機械学習による自動生成に関しては”機械学習による自動生成“に詳細を述べている。そちらも参照のこと。
参考図書としては“機械学習エンジニアのためのTransformer ―最先端の自然言語処理ライブラリによるモデル開発“

“

“


AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.
