主成分分析(Principle Component Analysis:PCA)について
近代深層学習技術の始まりであるオートエンコーダーについての項で、ヒントンらの論文では先行例としてPCAを述べていた。今回はそのPCAについてもう少し具体的に述べる。
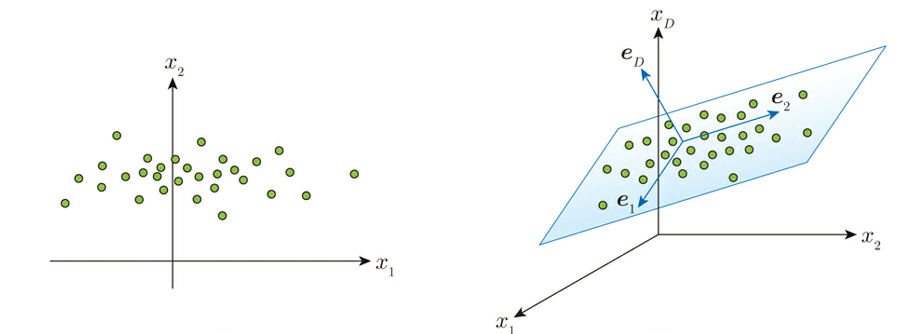
PCAは多次元のデータを次元圧縮する手法で、これは例えば2次元や3次元空間のデータを想定し、以下に示すようにある特定の1次元軸(直線)や2次元軸(平面)上でバラついている(分散が大きい)時、その直線あるいは平面上でデータが偏っているとして、元々あった2次元あるいは3次元の軸ではなく、特定の1次元軸(直線)や2次元軸(平面)上のデータとして表す事を言う。

機械学習プロフェッショナルシリーズ「これならわかる深層学習入門」より*1)
実際のアルゴリズムは、新たな部分空間(上述の特定の1次元とか2次元軸)を表す基底ベクトルeを想定し、データの分布の中央値(平均値)c0と共に使って最小か問題min E(c0, e)をラグランジュ未定係数法を用いて計算するものとなる。ラグランジュ乗数法の詳細に関しては”双対問題とラグランジュ乗数法“を参照のこと。
ここで実際にRを使って主成分分析を行ってみる。参考としたのは馬場真哉さんの「主成分分析の考え方」より
まずRがデフォルトで持っているiris(アヤメ)データを使って「ggplot2」と「GGally」の2つのパッケージを使ってグラフを書く。
install.pacjages("ggplot2")
install.packages("GGally")
library(ggplot2)
library(GGally)
ggpairs(iris, aes_string(color="Species", alpha=0.5))「ggpairs」という描画関数を用いて引数に「sea_string(color=”Specis”, alpha=0.5」を指定して種類ごとに色を付ける。alpha=0.5は透明度の指定となる。結果は以下となる。

それぞれの変数ごとに結果が表示されている。散布図はそれぞれの変数をxyとした時の分布、散布図と対象の位置にあるデータは相関係数、縦と横が同じ変数の場合はその変数の平滑化されたヒストグラム、最後の列は種類別の箱髭図となっている。
ここで主成分分析(「procomp」関数を利用)を実行する。
#種類データを除く(procompでは種類のデータに適用できない為)
pca_data <- iris[,-5]
#主成分分析の実行
model_pca_iris <- procomp(cpa_data, scale=T)
> # 結果
> summary(model_pca_iris)
Importance of components:
PC1 PC2 PC3 PC4
Standard deviation 1.7084 0.9560 0.38309 0.14393
Proportion of Variance 0.7296 0.2285 0.03669 0.00518
Cumulative Proportion 0.7296 0.9581 0.99482 1.00000
# 主成分分析の結果をグラフに描く
install.packages("devtools")
devtools::install_github("vqv/ggbiplot")
library(ggbiplot)
ggbiplot(
model_pca_iris,
obs.scale = 1,
var.scale = 1,
groups = iris$Species,
ellipse = TRUE,
circle = TRUE,
alpha=0.5 )
結果は以下となる。

iris pca結果
Petal.LengthとPetal.Widthはほぼ同じ軸を持つことが確認される。またSepal.Lengthも方向的にはかなり近いことが確認される。それに対してSepal.Widthは明らかに異なった方向の軸を持つことが目視できる。以上よりPetal.LengthとPetal.WidthそしてSepal.Lengthは第一主成分軸、Sepal.Widthは第二主成分軸であると判断できる。実際に上述のirisデータの分布を見てもSepal.Widthのみ他のパラメータと比較してヒストグラムの分布が異なっている。
PCAの発展系としては、対応分析(カテゴリデータなどにも適用可能)、カーネル主成分分析(非線形なデータにも適用可能)、主成分回帰(主成分分析をした結果を使って、回帰分析を行い、予測を行う)等がある。
参考文献 *1) これならわかる深層学習入門
また、”ロバスト主成分分析の概要と実装例“でも述べているロバスト主成分分析は、データの中から基底を見つけ出すための手法であり、外れ値やノイズが含まれているようなデータに対しても頑健(ロバスト)に動作することを特徴とするものとなる。

AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.
