Word2Vec
「Word2Vecにより自然言語処理」より。word2VecはTomas Mikolowらによって提案されたオープンソースの深層学習技術となる。原理的には単語のベクトル化(デフォルトのパラメータでは200個の次元)をするもので、200次元の空間上に単語を位置づけ、単語間の類似性(例えばコサイン類似度で評価)を見たり、クラスタリングを行なったりすることができるものとなる。
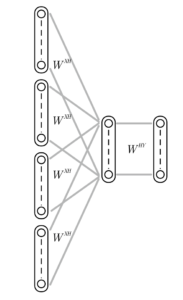
word2vecはまず入力部として、「文脈」と呼ばれる文の中で注目している単語wtの前後5単語wt-5, wt-4, .., wt-1, wt+1, …, wt+4,wt+5のBag-of-Words表現をインプットして、(注目した)単語wtを出力するような下図に示すCBOW(Continuous Bag Of Word)ニューラルネットを学習する。(前後5単語の部分はオプションで指定可能)

word2vecを用いた自然言語学習より
ここで計算効率をよくするため、(1)入力層から隠れ層への結合は単語の位置を問わず同じとする。(2)隠れ層の活性化関数はシグモイドではなくただの恒等関数f(x)=xという2つの特徴をword2vecは持っている。
次に出力層側として、逆方向にある単語を入力した時の文中の位置(文脈)を再現する下図に示すようなSkip-Gramニューラルネットを構築する。

word2vecによる自然言語学習より
word2vecでは、これらをつなぎ合わせて以下のような形で学習を行う。

word2vecによる自然言語学習より
この時、学習するための入力/出力としては「単語を空白で区切り」「文は改行で区切る」形で整形したtexデータを用いる。このニューラルネットの形は以前紹介した「オートエンコーダー」とほぼ同様のものとなる。異なる点は前述の活性化関数を非常にシンプルにしているところと、入力層から隠れ層へのリンクが均一に行われているところにある。
また別の観点から見ると、この計算は下図に示すような「関係データ学習」で述べた低ランク近似(20万x200の行列に圧縮)に相当するものであるとも言える。

word2vecによる自然言語学習
Word2Vecは上記のようなしくみで各単語に相当する分散ベクトル表現を得ることができ、これとコサイン類似度を組み合わせると単語間の類似性が、前述したPCAやk-means等のクラスタリングツールを使うことでクラスタリングを行うことができる。
一般的なニューラルネットワークでは入力(x1,x2,x3)に対してYin=x1w1+x2w2+x3w3、Yout=f(Yin)と表される。この時f(x)は活性化関数とよばれる。一般的なニューラルネットワークでは、閾値関数、シグモイド関数、Reftifier関数が使われる(下図左から閾値関数、シグモイド関数、Reftifier関数)

word2vecを用いた自然言語処理
さらに一般的には出力層の活性化関数には以下に示すような”ソフトマックス関数の概要と関連アルゴリズム及び実装例について“で述べられているソフトマックス関数が用いられる。
\(\displaystyle Y_i^{OUT}=\frac{\exp(Y_i^{IN})}{\sum_{k}\exp(Y_k^{IN})}\)
word2vecではニューラルネットへの入力は1-of-K形式なので一般の場合と比べて、重みの行列から1桁だけ取り出して計算するだけで済むので計算コストを節約できる。

word2vecを用いた自然言語処理
更にword2vecでは効率的な計算を行うため「階層的ソフトマックス」と”ネガティブサンプリングの概要とアルゴリズム及び実装例“で述べている「ネガティブサンプリング」を用いている。階層的ソフトマックスは単語を階層的なグループにすることで、個々の単語に対して計算を行うよりも階層の組み合わせで計算することで効率的な計算を行うもので、そのような階層を選ぶために「ハフマン符号化」(単語を出現回数でソートして、小さい方から二つづつ選んでまとめることを繰り返して最終的に一つになるまで続けて二股の分岐による木を作る。この分岐の片方を赤で塗りルートから単語まで辿る道を赤を0、黒を1として並べていくと重複のない富豪が以下のようにできる)を用いる。

word2vecによる自然言語学習より
このようにしてハフマン符号を用いて、先頭が0であるグループと1であるグループ、更に2列目がわであるグループと1であるグループというふうにグループ分けしていく。このようにして符号化すると頻度の高い単語が短く、頻度の低い単語が長く符号化される。上記の例だと最長の符号は5で5回処理することになる。符号の長さと頻度を掛けて平均の符号化長を計算すると2.51となり、単語は8個あるのに、平均2.51回で処理できることがわかる。
次にネガティブサンプリングについて述べる。ネガティブサンプリングは、正解層で正解ニューロン以外のニューロンを更新せず、代わりにランダムに5個くらいの偽の入力を選び(選ぶ確率はユニグラム確率(単語の出現頻度)の3/4)、その偽の入力で正解が出る確率を下げる計算を行う。このネガティブサンプリングは「語彙の集合が変化する」状況で「コーパス継ぎ足して繰り返し学習する」時に有効に使える手法となる。
word2vecにはいくつか課題がある。まず「多義語」への対応だ。これはたとえばamazonという言葉はアマゾン川のアマゾンでもありECのアマゾンであったりappleという言葉はりんごでもありコンピューターメーカーの名前化でもあるというように複数の意味があっても、word2vecを含めた深層学習系のアプローチでは最適解を求める為一意の分散表現しか推定できないというものになる。
この課題に対する対応としては前回の「トピックモデル」や「関係データ学習」でも述べた生成モデルのアプローチがある。これは確率モデルに応じて単語が生成されるというもので、例えば混合ガウス分布のように物を使ってモデルを作ることで複数の単語を生成する多義語に対した対応が可能になる。
次の課題としては、類似性に関するものがある。これは例えばW2Vの類似性はベクトル間の類似度を測るコサンイン類似度で評価することが一般的で、分散表現としてAとBが類似していてBとCが類似していれは、AとCも類似している結果になることが多い。これに対して現実の意味的な世界では、例えばりんごとトマトは赤いという観点で似ていて、りんごと青リンゴはりんごという観点で似ていても、トマトと青リンゴが似ていないという問題が生じる。

これらは単純にベクトルの近さだけではなく、何らかの軸(ラベル等)で繋げていかなければ意味的な類似を判定できないことをしめしている。このような関係性の構造を用いたアプローチでは単純な機械学習だけではなく「数理論理学」等を用いた論理学を組み合わせる必要がなる。
最後の課題として、入力の単語の区切り方に大きく影響されるというものがある。これはW2Vでは単語を区切って処理するので、例えば「地震計」と「地震」を別の区切りにしてW2Vへの入力の整数にすると地震計が123、地震が235となり元々近い意味を持っていた単語が別のものになってしまう。またひらがな一文字から成る助詞や、句読点や各種カッコなどの記号、あるいは数字等高頻度で出現するが、文の意味的には必要性が低い単語に関しても、何も考慮せずに分散表現の中に入れると学習結果に偏りが生じる。これらを防ぐためには入力データの正則化やクレンジングを注意深く行う必要がある。

AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.
