Machine Learning Artificial Intelligence Natural Language Processing Semantic Web Ontology Technology Digital Transformation Probabilistic Generative Model Web Technology Deep Learning Online Learning Reinforcement Learning User Interface Reasoning Technology Knowledge Information Processing Chatbot and Q&A Technology Navigation of this blog
Introduction
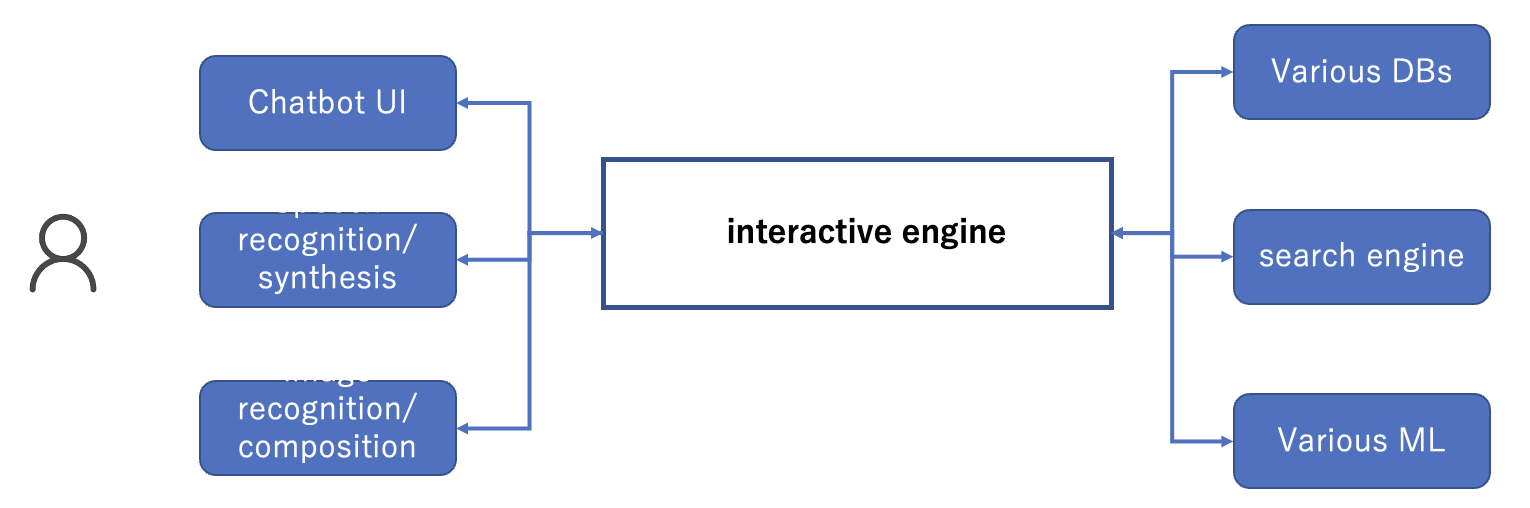
The AI dialogue engine is a scalable technology PF that flexibly connects various UI (front-end) and DB, search, ML, etc. (back-end) in a single PF. The UX issues to be addressed are as follows.
- When handling complex data (e.g., search), it is necessary to build a UI to handle each attribute, which complicates the UI structure and greatly reduces UX.
- When handling data created by various MLs, it is necessary to design/build a UI for each individual application.

In addition, from a business perspective, it has the following characteristics
Can be applied to almost any domain, including customer service and (personalized) business support.
The development cost of the front-end (UI) can be significantly reduced, and a variety of configurations from simple to complex can be created, making it possible to build a variety of business models from small to large.
The technical benchmarks of these dialogue engines are as follows.

Single threaded type chatbot
Single-threaded technology is the predominant type of technology used in business today, and will be the one used by most of the companies listed below, as summarized by sciseed, for example.

The term “with artificial intelligence” used here basically refers to natural sentence input using natural language processing, which has been actively researched by academic societies in recent years. Semantic Q-A response technology is not used.
In addition, rather than intelligent dialogue functions, attention is being paid to its role as a web platform that connects various UIs and applications. KUZEN, a venture in chatbot systems, is promoting its function as a clamp that connects various web systems, as shown below.

As a concrete example, as shown below, proposals have been made to simplify various internal procedures for employees by linking chatbot with RPA and core systems as an interface. (Example of KEZEN)

A simple and concrete implementation of a single-threaded, rule-based chatbot is described in “Implementing a Chatbot System Using Node.js and React“. Here, the rule code and the behavior code are separated, and the rule part can be written in a JSON file. One of the key points of the existing chatbot makers is that they provide a tool that can easily (graphically) generate this JSON file.
Advanced using natural language processing/deep learning of responses
In this chatbot, the input is just a selection from the default choices (yes/no or a few pre-prepared choices). In contrast, chatbots that take the approach of inputting natural text are called “chatbots with artificial intelligence”. What is done there, however, is not semantic interpretation of the input, but merely categorizing the input text and assigning it to the originally set options in the chatbot.
The following is an example of such a configuration that “classifies input sentences and assigns them to the chatbot’s internal choices that were originally set.

This system will use the SV module, which is capable of high-speed processing, to classify the teacher data as it is updated. The specific implementation of this system is described in detail in “Implementation of a Javascript-based flexible chatbot system”.
In this section, we will discuss two recent technologies for question answering systems: (1) an approach using deep learning, and (2) an approach using knowledge graphs.
First, let’s discuss the approach using deep learning. The deep learning approach is basically an RNN-based approach to generate output based on past inputs. The Seq2Seq technology described in “Overview of the Seq2Seq (Sequence-to-Sequence) model and examples of algorithms and implementations” (shown below) is the starting point.

This is a model that generates a response from an utterance by learning pairs of utterance/response sequences, a technique that has been implemented on tensorflow and is also used in machine translation. The problem is that the model is generated from pairs of past speech/response sequences, so it can be used in tasks with limited responses, but it is not practical in situations where there are a variety of speech/response variations and little teacher data.
HRED (Hierarchical Recurrent Encoder-Decoder) is an extension of this method. (Figure below)

This is an extension of the RNN model to infer the next n utterances from the past n-1 utterances, and while it may improve accuracy compared to Seq2Seq, it does not solve the problem of data diversity and small amount of supervised data.
On the other hand, VAE (Auto-Encoding Variational Bayes) technology (shown below) prevents us from falling into a uniform answer by introducing an establishment model.

Because it uses a Bayesian model (probabilistic generative model), the generated answers have variations, but the evaluation of the generated answers by people has not been very high. (The flexibility of the probabilistic model is also insufficient, since the answers that users want vary from situation to situation.)
Finally, VHRED (Latent Variable Hierarchical Recurrent Encoder-Decoder), which combines these Bayesian models (VAE) with deep learning (HRED), has been proposed. (Figure below)

It generates n utterances probabilistically, given n-1 utterances in the past. Even with these, the generated answers have not been evaluated very highly by people. (Even the flexibility of the probabilistic model is insufficient, since the answer the user wants varies depending on the situation.)
Multi-threaded type chatbot
These approaches based on deep models and probabilistic generative models are considered to be unable to cope with the diversity of variations in conversations (speech responses) because they are strictly influenced by the input teacher data as an extension of past examples.
Therefore, since around 2017 and 2018, there have been approaches to deal with the diversity of variations in conversations (speech responses) by combining machine learning models and knowledge graphs. One of these approaches is “Complex Sequential Question Answering: Towards Learning to Converse Over Linked Question Answering Pairs with knowledge Graph“, a joint research between IBM Research AI and MILA. with knowledge Graph”.
The approach taken here is
- Learn conversations through a series of coherent QA pairs (200,000 dialogues, 1.6 million turns dataset)
- Combine logical/comparative inferences, etc. made through complex reasoning over a realistic-sized KG (Knowledge Graph) of millions of entities with the results of one
The configuration is shown in the figure below. The structure is as shown in the figure below.

This approach itself is not very accurate, with Recall (15-30%) and Precision (3-10%), but it is recognized as a new direction that has the potential to solve the existing problems. This approach of combining KG and ML has been widely discussed as the “SMART (SeMantic AnsweR Type prediction) Challenge” in natural language processing conferences and ISWC2020,21, a conference that deals with KG.
In the latter half of the “About Chatbot Technology” section of this blog, I introduce some of these papers.
In response to this, the author of this blog is considering combining the search part of KG with an expert system, or combining the combination part of machine learning and KG with online prediction techniques. I would like to discuss them separately.

コメント