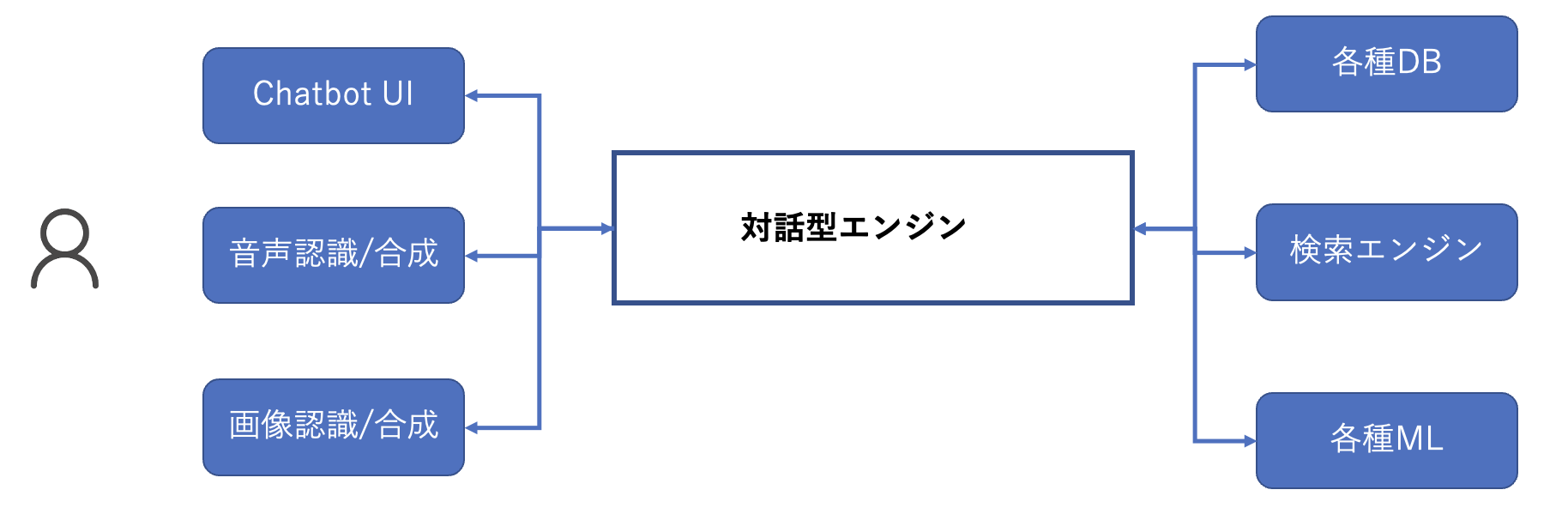
イントロダクション
AI対話エンジンは、様々なUI(フロントエンド)とDB,検索,ML等(バックエンド)のを単一のPFでフレキシブルに接続する拡張性のある技術PFとなる。また、それらが対応するUXとしての課題は以下のようになる。
- 複雑なデータを扱おう(検索等)とすると、それぞれの属性をハンドリングするUIを構築する必要があり、UIの構成が複雑になりUXが大幅に低減する。
- 様々なMLで作成したデータをハンドリングする際に個別のアプリケーションごとにUIを設計/構築する必要がある。

また、ビジネスとしての観点から見ると以下のような特徴を持つ。
- カスタマーサービス、(パーソナライズされた)業務支援等ほぼ全てのドメインへ適用可能
- フロントエンド部分(UI)の開発費用を大幅に低減、シンプルな構成から複雑な構成まで様々な形態の構成を組めることから、中小→大手までの多様なビジネスモデルを構築可能
これらの対話エンジンの技術的なベンチマークとしては以下のものがある。

シングルスレッドタイプチャットボット
シングルスレッドタイプの技術は現在ビジネスで用いられているタイプの主流であり、例えばsciseedによってまとめられた以下に示す企業のほとんどで使われているものとなる。

ここで分けられている「人工知能あり」は基本的には自然言語処理を用いた自然文入力のことを指し、近年学会等で積極的に研究されている。意味的なQ-A応答技術は用いられていない。
また、対話機能のインテリジェント化よりは、様々なUIとアプリケーションをつなぐウェブプラットフォームとしての役割が注目されており、チャットボットシステムのベンチャーであるKUZENでは以下に示すように、さまざまなウェブシステムをつなぐ鎹としての機能を訴求している。

具体的な例としては以下に示すように、chatbotをインターフェースとして、RPA、基幹システムと連携させることで、社員のさまざまな社内手続きを簡素化する等の提案が行われている。(KEZENの例)

シングルスレッドタイプでの、ルールを元にしたシンプルな具体的なチャットボットの実装に関しては、「Node.jsとReactを使ったチャットボットシステムの実装」にて述べている。ここでは、ルールのコードと動作のコードを分離し、ルール部分はJSONファイルで記述できる形となっている。このJSONファイルを(グラフィカルに)簡易に生成できるツールを提供しているのも、既存のチャットボットメーカーのポイントとなっている。
応答の自然言語処理/深層学習を用いた高度化
このチャットボットでは、入力はあくまでもデフォルトに設定した選択肢(YES/NOあるいは事前に準備したいくつかの選択肢)から選ぶものとなる。これに対して、入力を自然文で行うアプローチが取られているものが、「人工知能あり」と呼ばれているチャットボットとなる。ただしそこで行われていることは、入力に対して意味的な解釈では無く、入力文を分類して元々設定されていたチャットボット内部の選択肢に振り分けているだけであり、より自然な質疑応答を行う技術は、学会レベルのものだけで実用化されているものはない。
以下にそれら「入力文を分類して元々設定されていたチャットボット内部の選択肢に振り分ける」構成の一例を示す。

このシステムは高速処理が可能なSVモジュールを利用して、教師データを更新しながら分類していくものとなる。これらの具体的な実装に関しては「Javascriptベースのフレキシブルなチャットボットシステムの実装」にて詳細に述べる。
ここで質問応答システムの近年の技術として(1)深層学習によるアプローチ、(2)ナレッジグラフを用いたアプローチについて述べる。
まず深層学習を用いたアプローチについて。深層学習のアプローチは基本的には”RNNの概要とアルゴリズム及び実装例について“で述べているRNNベースの過去の入力に応じた出力を生成するアプローチとなる。まずスタートとなるのが”Seq2Seq(Sequence-to-Sequence)モデルの概要とアルゴリズム及び実装例について“で述べているSeq2Seq技術(下図)となる。

これは、発話/応答のシーケンスのペアを学習させることで、発話から応答を生成するモデルとなる。tensorflow上でも実装があり、機械翻訳でも利用されている技術となる。課題としては過去になされた発話/応答のシーケンスのペアからの生成となるので、限定された応答のタスクでは活用できるが、発話/応答のバリエーションが多様で教師データが少ないシチュエーションでは実用的ではない。
これを拡張させものとしてHRED(Hierarchical Recurrent Encoder-Decoder)がある。(下図)

これは過去のn-1個の発話から次のn個の発話を推測するようにRNNモデルを拡張したものとなる。Seq2Seqと比較して精度が上がる場合もあるが、データ多様性/少教師データの課題に対しては解決はできていない。
これに対してVAE(Auto-Encoding Variational Bayes)技術(下図)は、確立モデルを導入することで画一的な答えに陥ることを防いでいる。

ベイズモデル(確率的生成モデル)を用いるため、生成される答えにバリエーションが生まれるが、それら生成された答えがの人による評価はそれほど高いものは得られていない。(ユーザーの欲しい答えはシチュエーションにより異なるため、確率モデルのフレキシビリティでも不十分)
最後に、これらベイズモデル(VAE)と深層学習(HRED)を組み合わせたVHRED(Latent Variable Hierarchical Recurrent Encoder-Decoder)が提案されている。(下図)

これは、過去のn-1個の発話を与えられて、n個の発話を確率的に生成するものとなる。それらでも生成された答えがの人による評価はそれほど高いものは得られていない。(ユーザーの欲しい答えはシチュエーションにより異なるため、確率モデルのフレキシビリティでも不十分)
マルチスレッドタイプのチャットボット
これら深層モデルや確率的生成モデルをベースとしたアプローチでは、過去の事例の延長線上で、入力した教師データに厳密に影響されるため、会話(発話応答)の持つバリエーションの多様性に対応できないものと考えられている。
そこで2017年,2018年年頃より、それら機械学習のモデルとナレッジグラフを組み合わせて会話(発話応答)の持つバリエーションの多様性に対応しようとするアプローチが行われてきた。それらのうちの一つがIBM Research AIとMILAとの共同研究による「Complex Sequential Question Answering:Towards Learning to Converse Over Linked Question Answering Pairs with knowledge Graph」となる。
ここでのアプローチは
- 一連のまとまったQAペアを通じて会話を学習する(20万対話、160万ターンのデータセット)
- 数百万のエンティティからなる現実的なサイズのKG(Knowledge Graph)に対する複雑な推論を通じて行った論理的推論/比較推論等を1の結果と組み合わせる
ものとなる。構成としては下図のようになる。

このアプローチ自体ははRecall(15〜30%)、Precision(3〜10%)と精度自体はそれほど出ていないが、これまでの課題を解決できる可能性のある新規の方向性として認められ、このKGとMLを組み合わせるアプローチは、その後自然言語処理の学会や、KGを扱う学会であるISWC2020,21において「SMART(SeMantic AnsweR Type prediction)チャレンジ」として広く検討が行われている。
本ブログでも「チャットボット技術について」の後半でそれらの論文についての紹介を行なっている。
本ブログの筆者は、これに対して、KGの探索部分にエキスパートシステムを組み合わせたものや、機械学習とKGの組み合わせの部分にオンライン予測の技術を組み合わせたものを検討している。それらに関しては別途述べたいと思う。

AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.

コメント
[…] AI対話エンジンについて […]