Similarity in global matching (2) Similarity of Mereological Graph Patterns
Continuing from the previous article on natural language similarity from ontology matching..In the previous article, I gave an overview of approaches using graph patterns and the Taxonomic approach. In this article, we will discuss another approach to graph patterns, the Meleo Logic approach.
Mereological Structure
After the Taxonomic structure, the next best known structure is the mereologic (part-whole) structure, which corresponds to the part-of relation: the two classes Book and Volume are equivalent, and the two classes InBook and BookChapter are equivalent, respectively. If there is a mereologic relationship between the classes InBook and BookChapter, it implies that the two classes may be related as well. This reasoning also applies in the opposite direction, from part to whole. This is the case when there are separate parts, i.e., when the parts of a journal Issue are distinguished into editporial, article, recesions, and letture.
The difficulty in dealing with such a structure is that it is not easy to find a property that has just such a structure. For example, theProceedings class can have some whole-part relationship with theInProceedings class, which is represented by properties communications. These InProceedings objects will in turn have a mere structure represented by section properties.
However, if we can detect a relationship that supports the mere structure, we can use this to calculate the similarity between the classes. If they share similar parts, they can be said to be more similar. This will be more useful when comparing class extensions. This is more useful when comparing class extensions, because objects that share the same set of parts can be inferred to be the same.
Relations
Besides these two types of relations, we can consider the general problem of matching entities based on all relations. Classes are also related through the definition of their properties (like author and creator). These properties are edges of the graph, and if they are found to be similar, they can be used to find that classes are similar. However, unlike taxonomic or mereological structures, relational graphs may contain circuits. How to deal with these will be discussed in the next section. In this section, we consider similarity.
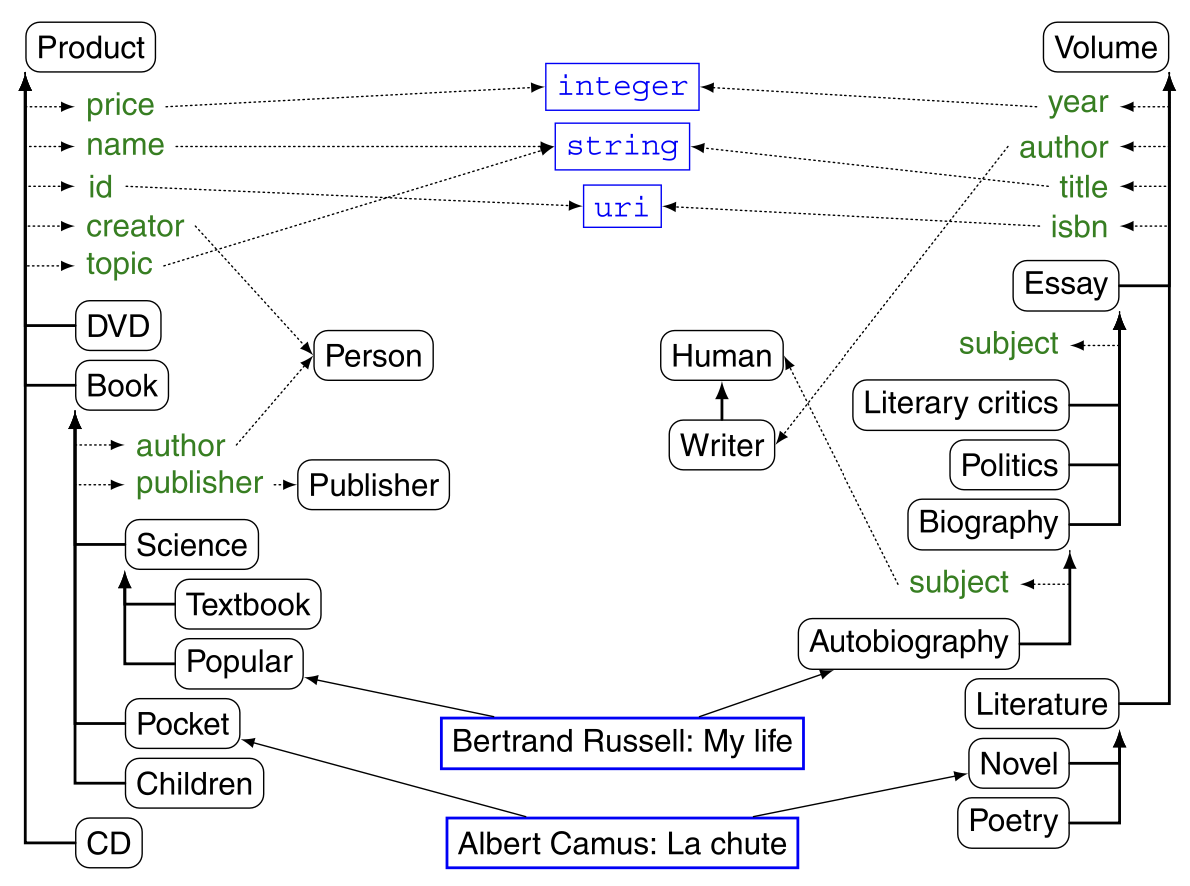
The similarity between nodes can also be based on their relationships. For example, in one of the ontology representations of the schema shown below, if in one ontology the Book class is related to the Human class by an author relationship, and in another ontology the Volumes class is related to the Writer class by an author relationship, then the Book and Volumes classes are similar, and knowing that the author relationship is similar to the author relationship, we can infer that the Human and Writer classes may also be similar. The similarity between the relations in (Mädche and Staab 2002) is calculated based on this principle.

This can be applied to a set of classes and a set of relations. The set of relations in the first ontology, r1 … . rn is similar to the second ontology’s set of relations r1′. .rn′, then the two classes in the domain of the relations of those two sets may also be similar. Identifying the possibility of such correspondences can be obtained by retaining the ones supported by the largest number of PROPERTIES.
In other words, this can be achieved by not only considering the relations asserted by a class, but also by considering combinations of these relations with relations starting from the domain of that relation. For example, instead of considering the author relation, it would be like considering the author-firstname, author-lastname, or author-nationality relations.
One of the problems with this approach is that it uses the similarity of the relations to infer the similarity of their domain and range classes. This leads to a circularity in the calculation of similarity. There are several ways to overcome this circularity. The first way is to base the similarity of relations on their labels; the second way can also be achieved by using the methods discussed in the previous taxonomy, if the relations are organized in a taxonomy.
Finally, the two extreme solutions of using relations to reach nodes but not for the actual matching are considered in the following approach.
Children: The similarity between nodes in a graph is calculated based on the similarity of the child nodes. In other words, two entities that are not leaves are structurally similar if their immediate child sets are highly similar. A more complex version of this matcher can be found in (Do and Rahm 2002).
Leaf: That is, two non-leaf entities are structurally similar if their sets of leaves are very similar, even if their direct children are not (Madhavan et al. 2001; Do and Rahm 2002). This is very suitable for comparing document schemas.
Pattern-based matching
Pattern-based matching is about identifying correlated patterns in two ontologies and finding correspondences between them. It starts with a set of predefined correspondence patterns (see figure below). A correspondence pattern is an abstraction of a correspondence relationship, and it does not relate individual entities, but rather types of entities. Such patterns usually identify modeling patterns for alternative concepts.

The above shows three patterns of correspondence. (a) the property ?w is equivalent to the property has?W, (b) the subclass ?Y may correspond to an element whose property ?p has the value ?Y, and (c) if ?X is a disjoint form of ?Y and ?W is a subclass of Z, then it is forbidden for ?X to be equivalent to ?Z and ?Y to be equivalent to W. If ? X is disjoint from ?

An example of pattern instantiation is shown in the figure above. An instance of a correspondence pattern is a correspondence (an example in EDOAL.
(Scharffe and Fensel 2008) introduces the instantiation of correspondence patterns in ontologies and their use for ontology matching. For example, in the above figure, we can identify patterns in the ontology by substituting {?X → Paper, ?Y → Accepted, ?Z → Article, ?p → status}, and consider the result as a possible correspondence. proposed a library of 44 correspondence patterns based on the study of For a correlation pattern to be meaningful, it needs to use a representation language, either on the ontology side or on the alignment language side; the EDOAL language (Section.10.1.6) was defined with this goal partially in mind.
The alignment pattern will be called a block matching pattern (Šváb-Zamazal 2010), which uses the same principle to group several correspondences together. More tolerance is also introduced into the pattern by using a similarity measure, usually based on string similarity, to determine the pattern instance. Patterns may also contain value constraints, such as v = u ± 3 %. Also, (Ritze et al. 2009) experimented with a specific algorithm for recognizing four such specific patterns.
Antipatterns (Roussey et al. 2009) also identifies correspondences that should not be included in the alignment. The rules used by the system to detect consistency or inconsistency in alignments may be anti-patterns in (semantic) alignments.
Refined patterns are expressed in a first-order predicate language and consist of anti-patterns and patterns (Hamdi et al. ) This method detects the presence of anti-patterns and the possibility of instantiating patterns in the same alignment. This will be used to suggest to the user to replace the anti-pattern with the latter. Other research has defined patterns not simply in an ontology language (identifying classes and properties), but in a common underlying ontology (identifying events and participants) (Padilha et al. ) Pattern-based matching is classified as a structural method because it matches structures. However, this particular structure can also be detected by inference.
Summary of Relational Techniques
Matching ontologies from relational (or external) structures is a very powerful approach because it can take into account all relationships between entities. However, this technique is often used in combination with internal structure or terminology methods because it must be based on other specific properties.
Before using such techniques, it is worthwhile to consider what the key relationships are. The most commonly used structure is a specialized taxonomy. This is because specialized taxonomies are the backbone of ontologies and usually attract a lot of attention from decliners. In some fields, mere taxonomic relations are just as important as taxonomic relations. However, these relations are difficult to identify because, contrary to subClass relations, they can have other names.
The relational structure raises the question of which parts affect which parts. This is the reason why an iterative algorithm is needed in addition to the similarity equation used to compare entities. This will be discussed in the next section.

コメント