グローバルマッチングでのsimilarity(類似性)(2)メレオロジックなグラフパータンの類似性
前回に引き続きオントロジーマッチングより自然言語の類似性について。前回はグラフパターンを用いたアプローチの概要とTaxonomicなアプローチについて述べた。今回はグラフパターンのもう一つのアプローチであるメレオロジックなアプローチについて述べる。
(Mereologic)メレオロジック構造
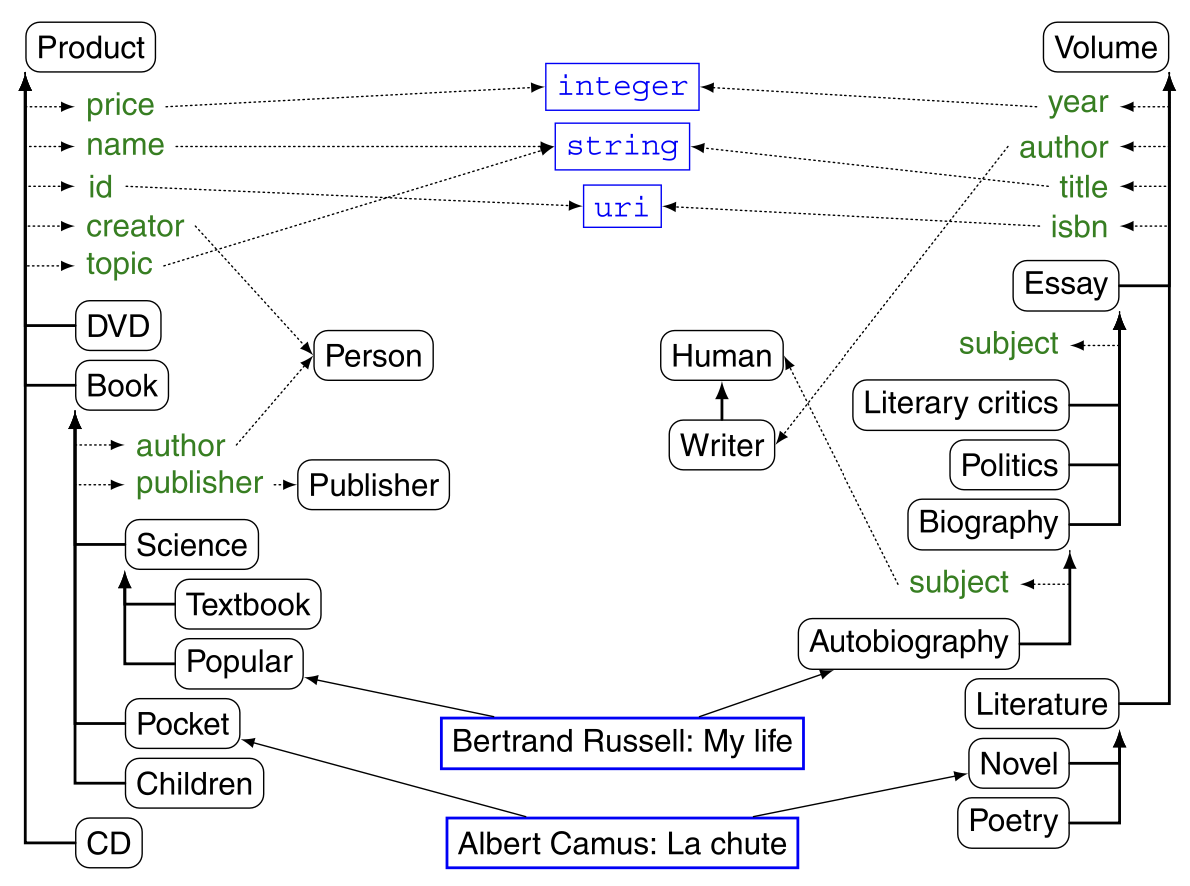
Taxonomic(分類学的な)構造の次によく知られている構造は、mereologic(部分と全体)構造、つまり、part-of関係に対応する構造となる。BookとVolumeという2つのクラスが等価であることがわかり、それぞれInBookとBookChapterというクラスとの間にmereologicな関係がある場合、この2つのクラスは同様に関係している可能性があることを示唆している。この推論は部分から全体という逆の方向にも当てはまる。これは、個別の部分がある場合、つまりジャーナルIssueの部分がeditporial、article、recesions、lettureに区別される場合としてある。
このような構造を扱う上での難しさは、単なる構造を持つプロパティを見つけるのが容易ではないことなる。例えば、ProceedingsクラスはInProceedingsクラスといくつかのwhole-part関係を持つことができるが、それはproperties communicationsによって表現されるものとなる。これらのInProceedingsオブジェクトは、今度はセクションプロパティで表現される単なる構造を持つことになる。
しかし、単なる構造をサポートする関係を検出することができれば、これをクラス間の類似性を計算するために使用することができる。類似した部分を共有する場合、それらはより類似しているといえる。これは、クラスの拡張を比較する際に、より有用となる。なぜなら、同じパーツのセットを共有するオブジェクトは同じであると推測できるからだ。
Relation(関係)
これらの2種類の関係の他に、すべての関係に基づいてエンティティをマッチングするという一般的な問題を考えることができる。クラスは、そのプロパティ(authorとcreatorのようなもの)の定義を通じても関係する。これらのプロパティは、グラフのエッジであり、それらが類似していることがわかれば、クラスが類似していることを見つけるために使用することができる。しかし、分類学的構造やメレオロジー的構造とは異なり、関係グラフには回路が含まれている場合がある。これらをどのように扱うかは、次節で検討する。ここでは類似性について考える。
ノード間の類似性は、その関係に基づくこともできる。例えば、下図のスキーマのオントロジー表現の1つにおいて、あるオントロジーではBookクラスがHumanクラスとauthor関係で関連しており、別のオントロジーではVolumeクラスがWriterクラスとauthor関係で関連している場合、BookクラスとVolumesクラスが類似しており、author関係とauthor関係が類似していることを知ると、HumanクラスとWriterクラスも類似している可能性があると推測することができる。(Mädche and Staab 2002)の関係間の類似性は、この原則に基づいて計算されている。

これは、クラスのセットと関係のセットに適用できる。第1のオントロジーの関係のセットr1 … rnが、第2のオントロジーの関係のセットr1′…rn′と類似している場合、それらの2つのセットの関係のドメインに含まれる2つのクラスも類似している可能性がある。このような対応関係の可能性を識別するには、最大数のpropertyに支えられたものを保持することで得られる。
つまり、あるクラスで主張される関係だけを考えるのではなく、その関係のドメインから始まる関係との組み合わせを考えることによって実現できる。例えば、author関係を考える代わりに、author-firstname、author-lastname、またはauthor-nationality関係を考えるようなものとなる。
このアプローチの問題点の一つは、関係の類似性を利用して、そのドメインクラスやレンジクラスの類似性を推測することにある。これにより、類似性の計算に循環性が生じることとなる。この循環性を克服する方法はいくつかある。第一の方法として、関係の類似性をそのラベルに基づいて行うことができる。2つ目の方法として、関係が分類法で整理されている場合は、前回のtaxonomyで検討された方法を使用することでも実現できる。
最後に、ノードに到達するために関係を使用するが、実際のマッチングには使用しないという2つの極端な解決策を以下のアプローチで検討する。
子(children) : グラフのノード間の類似性は、子ノードの類似性に基づいて計算される。つまり、リーフではない2つのエンティティは、その直下の子セットが高度に類似していれば、構造的に類似していることになる。このマッチャーのより複雑なバージョンは(Do and Rahm 2002)に記載されている。
葉(leaf): すなわち、2つの非葉のエンティティは、それらの直接の子供がそうでなくても、それらの葉のセットが非常に似ていれば、構造的に似ているということになる(Madhavan et al. 2001; Do and Rahm 2002)。これはドキュメントスキーマの比較に非常に適している。
パターンベースのマッチング
パターンベースのマッチングとは、2つのオントロジーにある相関するパターンを特定して対応関係を見つけることにある。これは、定義済みの対応パターンのセットから始まる(下図参照)。対応パターンは対応関係を抽象化したものであり、個々のエンティティを関連付けるのではなく、エンティティのタイプを関連付けるものとなる。このようなパターンは、通常、代替概念のモデリングパターンを特定する。

上記は3つの対応関係のパターンを示している。(a) プロパティ ?w はプロパティ has?W と等価である、(b) プロパティ ?p の値が ?Y である要素にサブクラス ?Y が対応することがある、(c) ?X が ?Y の不分離形であり、かつ ?W が Z のサブクラスである場合、 ?X が ?Z と等価であり、かつ ?Y が W と等価であることは禁じられている、というアンチパターンがある。

パターンのインスタンス化の例を上図に示す。コレスポンデンス・パターンのインスタンスは、コレスポンデンス(EDOALでの例)である。
Scharffe and Fensel 2008)では,オントロジー内に対応パターンをインスタンス化し,オントロジーマッチングに利用することを紹介している.例えば,上図では,{?X → Paper, ?Y → Accepted, ?Z → Article, ?p → status}という代入により,オントロジー内のパターンを特定し,その結果を対応付け可能なものとみなすことができる.Scharffe 2008)は、オントロジーのミスマッチの研究に基づいて、44の対応パターンのライブラリを提案した。相関パターンが意味を持つためには、オントロジー側またはアライメント言語側のいずれかの表現言語を使用する必要がある。EDOAL言語(Section.10.1.6)は、この目的を一部考慮して定義された。
アライメント・パターンは、ブロック・マッチング・パターン(Šváb-Zamazal 2010)と呼ばれ、同じ原理でいくつかの対応点をまとめて表示するものとなる。また、パターンのインスタンスを決定するために、通常は文字列の類似性に基づいた類似性尺度を使用することで、パターンにはより多くの耐性が導入されている。パターンには、v = u ± 3 %のような値の制約が含まれることもある。また、(Ritze et al. 2009)では、このような特定の4つのパターンを認識するための具体的なアルゴリズムを実験している。
Antipatterns (Roussey et al. 2009) は、アライメントに含めるべきではない対応関係も特定する。アラインメントの一貫性や非一貫性を検出するためにシステムが使用するルールは、(セマンティック)アライメントのアンチパターンである可能性がある。
洗練されたパターンは、一階述語言語で表現され、アンチパターンとパターンで構成される(Hamdi et al. )この手法では、アンチパターンの存在とパターンのインスタンス化の可能性を同じアライメントで検出する。これを利用して、ユーザーにアンチパターンを後者に置き換えることを提案するものとなる。他の研究では、パターンを単にオントロジー言語(クラスやプロパティの識別)ではなく、共通の基礎的オントロジー(イベントや参加者の識別)で定義している(Padilha et al. )パターンベースの照合は、構造を照合するため、構造的手法に分類される。しかし、この特定の構造は、推論によっても検出できる。
リレーショナル・テクニックのまとめ
関係(または外部)構造からオントロジーをマッチングすることは、エンティティ間のすべての関係を考慮に入れることができるため、非常に強力なアプローチとなる。しかしながら、この技術は、他の具体的な特性に基づかなければならないため、内部構造法や用語法と組み合わせて使用されることが多い。
このような技術を使う前に、何が重要な関係であるかを検討することは価値がある。最もよく使われる構造は、専門分類法である。なぜなら、専門分類法はオントロジーのバックボーンであり、通常、デサイナーから多くの注目を集めているからである。いくつかの分野では、分類学的な関係と同様に、単なる分類学的な関係も重要である。しかし、これらの関係は、subClass関係とは逆に、他の名前を持つことができるため、識別するのが難しい。
関係構造は,どの部分がどの部分に影響を与えるかという問題を提起する.これが、エンティティの比較に使用される類似性方程式の他に、反復アルゴリズムが必要とされる理由となる。これについては次のセクションで説明する。

AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.
