グローバルマッチングでのsimilarity(類似性)(3)反復的な計算によるグラフパターンの類似性
前回はグラフパターンを用いたアプローチの概要とTaxonomicなアプローチについて述べた。今回はグラフパターンのマッチングに対して反復的な類似性の計算を行うアプローチについて述べる。
反復的な類似性の計算
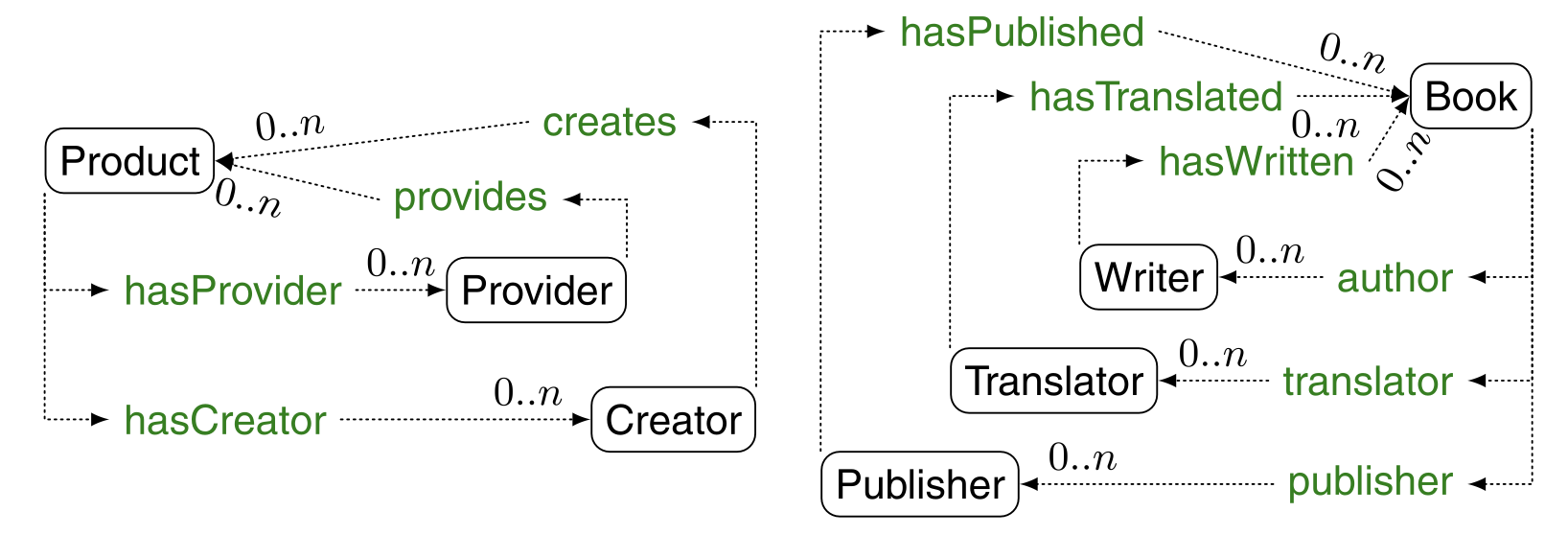
複合的な類似性の計算は、ノードの近隣を考慮して類似性を提供するだけなので、まだ局所的なものとなる。しかし、類似性はオントロジー全体を対象としており、最終的な類似性の値は、最終的にすべてのオントロジーエンティティに依存する可能性がある。さらに、オントロジーが有向非環状グラフに還元されていない場合、局所的な方法で定義された距離は、循環的に定義される可能性がある。これは最も一般的なケースである。例えば、2つのクラス間の距離が、そのクラス間の距離に依存するインスタンス間の距離に依存する場合や、オントロジー内に循環が存在する場合などに発生する。下図に示すように、ProductとBookの類似性は、hasProviderとhasCreatorおよびauthor、publisher、translatorの類似性に依存している。そして、これらの要素間の類似性は、最終的にProductとBookの類似性に依存する。この2つのグラフは、様々な意味でホモ・モルフィックとなる。

参照サイクルを含む2つの典型的なオントロジー:どのようにマッチングさせれば良いのか?
循環依存性がある場合、局所的に類似性を計算することはできない。このような問題に対処するための古典的な方法は、最後に計算した値を各ステップで改良しながら、距離または類似性を繰り返し計算することとなる。これは、下図に示されている。

類似性や距離関数の固定点を繰り返し計算
このようなケースのために、このグローバルな類似性を計算するための戦略を定義する必要がある。ここでは、そのような方法を2つ紹介する。1つ目は、グラフ内の類似性を伝播するプロセスとして定義されるもの、2つ目は、類似性の定義を一連の方程式に変換して、数値解析技術によって解くものとなる。
Similarity Flooding(類似性フラッディング)
Similarity Flooding (Melnik et al. 2002)は、固定小数点計算を用いてグラフ内の対応するノードを決定する、一般的なグラフマッチングアルゴリズムである。このアルゴリズムは、Rondo 環境で実装されている。
このアルゴリズムの原理は、2つのノード間の類似性は、(考慮すべき関係は何であれ)隣接するノード間の類似性に依存しなければならないとなる。これを実現するためのアルゴリズムは以下のようになる。
- オントロジーを有向ラベル付き(マルチ)グラフGに変換する: このグラフでは、ノードはオントロジーの概念のペアであり、2つのノード間には、2つのペアのノード間に両方のオントロジーの関係がある場合にエッジが存在する。例えば、下図のオントロジーでは、⟨Provider, Writer⟩は⟨Product, Book⟩と、⟨hasProvider, hasWritten⟩とラベル付けされたエッジを介して関連している。実際、オリジナルのSimilarity floodingアルゴリズムでは、エッジが同じラベルを持つノードのみを接続する。このグラフは対称性によって閉じており、つまり、逆方向のエッジも存在することになる。

- エッジに重みを付ける: 重みは通常1/nであり、ソースノードの外延度(外に出ているエッジの数)と同じである。アルゴリズムの説明では、ラベルの異なる複数のエッジが同じ概念のペアをリンクしている場合や、すでに逆方向のエッジがある場合にどうするかは書かれていない。重みを三角ノルムで集約することが考えられる。
- 各ノードに初期類似度σ0を割り当てる:(ラベルに関する基本的な方法を用いるか、1.0の一律割り当てを行う。
- 選択された式で各ノードのσi+1を計算する。
- 最大値で割って得られたすべてのσi+1を正規化する。
- どの類似性も特定の閾値ε以上に変化しない場合、すなわち、∀e∈o,e′∈o′,|σi+1(e,e′)
o′, |σ i+1(e, e′) – σ i (e, e′)| <ε、または所定のステップ数の後、停止し、そうでなければステップ4に進む。
選ばれた集約関数は、重み付き線形集約で、エッジの重みは、同じエンティティのペアに到達する同じラベルを持つ他のエッジの数の逆数となる。辺の重みは、同じエンティティのペアに到達する同じラベルを持つ他の辺の数の逆数になる。
\[ \sigma^{i+1}(x,x’)=\sigma^0(x,x’)+\displaystyle \sum_{<<y,y’>,p,<x,x’>\in G}\sigma^i(y,y’)\times\omega(<<y,y’>,p,<x,x’>>)\]
この式のバリエーションとして,σ0の項を抑えてσ0をσiに置き換えたり,再帰項としてσ0(x,x′)+σi(x,x′)を用いたりする方法が検討されている.前者は計算を高速化し、後者は初期値を重要視している。
このアルゴリズムの収束は明らかではない。(Melnik et al. 2005)は、アルゴリズムが収束する条件を提供している。このアルゴリズムは、類似性の尺度を提供し、そこからアライメントを抽出する必要がある。
Similarity floodingの例、下図のオントロジーから始める。Similarity floodingアルゴリズムは同じプロパティ名で動作し、類似したプロパティは存在しないので、すべてのプロパティが同じ名前であると考えることにする。これらのオントロジーから、以下のラベル付き有向グラフ(重み付き)を生成する。

初期の非類似度は、重みを1/4と3/4とした重み付き和に用意されているものとなる。
 σ1を計算するSimilarity floodingアルゴリズムの最初のイテレーションは以下の通りになる(左がσiの値、右が正規化された結果)。
σ1を計算するSimilarity floodingアルゴリズムの最初のイテレーションは以下の通りになる(左がσiの値、右が正規化された結果)。

反復生産を続け、e=0.1とした場合、17回目の反復で次のような結果になる。
 これらの類似性の値から、期待される対応関係を抽出することができる。
これらの類似性の値から、期待される対応関係を抽出することができる。
dence Product = Book、Publisher = Provider、Writer = Creatorという対応関係が期待できる。
相似方程式の固定点
OLA (Euzenat and Valtchev 2004) は、類似性定義間の循環性や依存性を扱う方法を提供している。
この場合、類似性の値は、各変数がノードのペア間の類似性に対応する方程式のセットとして表現される。変数と同数の方程式が存在する。各方程式の構造は,基礎となるノードカテゴリに対するそれぞれの類似性関数の定義に従っている。
2つのクラスcとc′が与えられた場合,結果としてクラスの類似性関数は以下のようになる。
\begin{eqnarray} \sigma`C(c,c’)&=&\pi_L^C\sigma_L(\lambda(c),\lambda(c’)\\&=&\pi_O^CMSim_O(L(c),L'(c’))\\&=&\pi_S^CMSim_C(S(c),S'(c’))\\&=&\pi_P^CMSim_P(A(c),A'(c’)) \end{eqnarray}
λ(・) L(・), S(・), A(・)は、それぞれクラスのラベル、インスタンス、スーパークラス、サブクラス、プロパティを返す関数となる(前節のname, properties, direct subclasses, direct superclasses, direct instancesに相当する)。MSim-measureは、オントロジーエンティティのセット間の類似性であり、以下に説明する。\(\pi_F^C\)は、特徴Fの相対的な重要性を示す重みとなる。
この関数は、重みの合計が1に等しいため正規化されている。すなわち、\(\pi_L^C+\pi_S^C+\pi_O^C+\pi_P^C=1\)であるのに対し、ノードまたは特徴値のコレクションに及ぶ各要素は、最大のコレクションのサイズで平均化される。
もし、各類似性表現が他の類似性変数の線形集約であれば、すべての変数がdegree1であるため、このシステムは直接解くことができる。しかし、OWLや他の多くの言語の場合、システムは線形ではなく、最適なマッチのための多くの候補ペアが存在する可能性がある。類似性は,対象となるノードから出力されるラベルが類似している複数のエッジのマッチングに依存する場合がある。このアプローチでは,類似性はMSim関数によって計算される.MSim関数は,まず,考慮されるエンティティのセット間のアラインメントを見つけ,次に,このマッチングに関する集約された類似性を計算する。
この点において、OLAアルゴリズムは、マッチングに依存した重みを持つ最大重みグラフマッチング問題という、非常に特殊な問題を解決する。
それにもかかわらず、結果として得られるシステムの解決は、(Bisson 1992)に示されているように、ベクトル関数の最大固定点の計算をシミュレートする反復プロセスとして実施することができる。このポイントは,MSim-measures の近似値を定義し,システムを解き,近似値を新たに計算された解で置き換え,反復することで構成される。これらのMSim-measuresの最初の値は,方程式の従属部分を考慮せずに,1つのペアについて求められた最大の類似性である。その後の値は,システムの解で満たされた完全な類似性の式の値である。局所的なマッチングは、類似性の値に応じて、あるステップから別のステップへと変化する。
しかし、類似性は増加するしかなく(方程式の不変部分が残り、すべての依存性が正である)、また、類似性の値が1などで制限されている場合は、類似性が制限されるため、システムは収束する。最後の反復で特定のε値以上の利得が得られなかった場合、反復は停止する。アルゴリズムが収束しても、局所的な最適値で停止することがある。(つまり、MSim-measuresで別のマッチを見つけても、類似性の値は増えない)これは、アルゴリズムの停止時に、これらのマッチングをランダムに変更することで改善される可能性がある。
ここで、特筆すべき事実がいくつかある。第一に、類似性の値の間に有効な循環依存性がない場合、類似性関数の異なる表現は必要ない。上に示した計算メカニズムは、たとえ変数の順序が適切であっても、正しい類似性の値を確立する。(順序は暗黙のうちに段階的メカニズムに従う)さらに、いくつかの類似性の値(あるいは類似性や(非)類似性の主張)が事前に得られている場合、対応する式をその主張や値で置き換えることができる。
OLAアルゴリズムの例。 解くべき問題はSimilarity Floodingの例で定義したものと同じなので、クラス間のラベルの類似度も同じとなる。プロパティ間のラベルの類似度を1とする。(すべてが似ている)をプロパティの各ペアに設定する。したがって、初期の類似度は次のようになる。

クラスについてはラベルとプロパティの重みを等しくし(\(\pi_L^C=\pi_P^C=1/2\))、プロパティについてはラベル、レンジ、ドメインの重みを等しくして(\(\pi_L^P=\pi_R^P=\pi_D^P=1/3\))、方程式を作成する。初期の類似性(ラベルのみに基づく)では、以下の値が得らる。

最初の反復では、エンティティ間の関係が考慮され、次のような結果が得られる。
 3回の反復後、値はe=0.1以上変化せず、10回の反復後、値はe=0.01以上変化せず、次のような結果が得られる。
3回の反復後、値はe=0.1以上変化せず、10回の反復後、値はe=0.01以上変化せず、次のような結果が得られる。

どちらのεの値でも、ベストマッチは常に同じとなる。それは
Similarity Floodingの例のクラスについては、次のようになり、さらに、プロパティについては、Creates = hasWritten, provides = hasPublished, hasProvided = publisher, hasCreated = author となる。
この2つの手法にはいくつかの共通点がある。どちらの手法も、オントロジーのグラフィカルな形式から抽出された方程式のセットを繰り返し処理します。どちらの手法も、最終的には、データタイプ名、値、URI、プロパティタイプ名など、記述されていない言語要素間の近さを計算することに依存する。これらの近接性は、類似性依存性によってグラフ構造全体に伝搬される。
さらに、類似度フラッディングはエッジラベルの同一性に大きく依存しますが、OLAアルゴリズムはプロパティ間の類似性を考慮している。さらに、OLAアルゴリズムは、すべてのマッチする可能性のあるエッジを平均化するのではなく、代替のマッチするエッジ間の局所的なマッピングを考慮します。つまり、OLAアルゴリズムは、マッチするサブクラスを特定し、その類似性を伝播しようとするが、Similarity floodingは、サブクラスのすべてのペアの平均類似性を伝播するが、これはマッチするサブクラスのすべてのペアの平均類似性よりも低くなる。最後に、Similarity floodingの収束は一般的には証明されていない。
グローバルな類似性計算のまとめ
オントロジーの複雑さは、反復的な方法でオントロジー間の類似性の値を伝播することを必要とする。複合的な類似性の定義が何であるか、また、どのような接続に沿ってリンクが伝搬されるかによって、異なる伝搬方法があるかもしれない。最後のテクニックからもわかるように、グローバルな類似性の計算は最適化問題として見ることができる。したがって、それらを実現するための古典的な最適化アルゴリズムを考えるのは自然なことである。
次回は期待値最大化と粒子群最適化の2つの最適化手法について述べる。

AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.
