人工知能技術 ウェブ技術 知識情報処理技術 セマンティックウェブ技術 自然言語処理 機械学習技術 オントロジー技術 オントロジーマッチング技術
前回に引き続きオントロジーマッチングより自然言語の類似性について。前回は内部構造を用いたアプローチについて述べた。今回は外部構造に基づいたアプローチについて述べる。
前回紹介した基本的な類似性は、2つのエンティティ間の類似性または非類似性を評価するために、それらの適切な特性(名前、内部構造、拡張子)のみを考慮しているため、ローカルな方法と考えられる。今回は、様々なエンティティを比較するために、内部構造ではなく、エンティティの外部構造を使用するグローバルな方法について述べる。
オントロジー内にサイクルや関係的な類似性を支配する制約における非線形性が存在する場合、単純な類似性の計算はできない。そこで、反復的な類似性計算技術を行う必要性が出てくる。これらのアプローチは、制約に対する最適解を近似する形となる。それらマッチング問題を解決するアプローチとして、まず古典的な最適化手法によるアプローチがある。また、グローバルな手法としては、オントロジーやアラインメントの構造に基づいて、関連するエンティティの確率を計算する確率的な手法がある。更に、オントロジーとアラインメントのそれぞれのグローバルな解釈に依存した意味論的手法がある。
これらのアプローチは、多くの場合、改良すべきシードアラインメントやアンカーを提供する基本的なマッ チャーに依存している。
リレーショナル・テクニック
オントロジーは、エッジが関係名でラベル付けされたグラフと考えることができる(数学的に言えば、これは(⊑, ∈, ⊥, , =)のような関係を持つオントロジーの多重関係のグラフとなる)。このような2つのグラフの要素間の対応関係を見つけることは、両グラフの共通の同型部分グラフを見つけることに対応する。
定義 6. 1 (共通の同型有向部分グラフ) 2つの有向グラフG = ⟨V , E⟩とG' = ⟨V', E'⟩が与えられたとき。 GとG'の共通の同型有向サブグラフは、グラフ⟨V'',E''⟩であり、 W ⊆ Vと、 W'⊆ V'で、 以下のような同型の対f:W → V''と、g: W'→ V''が存在するようなものとなる。 − ∀w ∈ V''、∃u ∈ V ; f(u)=w and ∃v ∈ V'; g(v)=w; − ∀⟨u,v⟩ ∈ E|W×W、 ⟨f(u),f(v)⟩ ∈ E''; − ∀⟨u′,v′⟩ ∈ E'|W'×W'、⟨g(u'),g(v')⟩ ∈ E''.
2つのオントロジーの2つのエンティティの類似性比較は、これらのエンティティとオントロジーの他のエンティティとの関係に基づいて行うことができる。例えば、2つのエンティティが似ているほど、関連するエンティティも似ているはずで、この観点から考慮する関係の種類に応じて、いくつかの方法で利用することができる。さらに、いくつかの関係が推移的な性質を持っていれば、それらの手法を推移的に拡張することもできる。大まかに言うと、各関係のペアに対して、関係を比較する5つの異なる方法を考えることができる(Euzenat et al. 2004)。
- rは、関係rを介した直接的な関係にあるエンティティを比較する。
- r–は、関係rの他動的還元のエンティティを比較する;
- r+は、関係rの他動的閉鎖のエンティティを比較する;
- r-1は、関係rを介してくるエンティティを比較する。
- r↑は、最終的にr+(クロージャの最大要素)に含まれるエンティティを比較する。
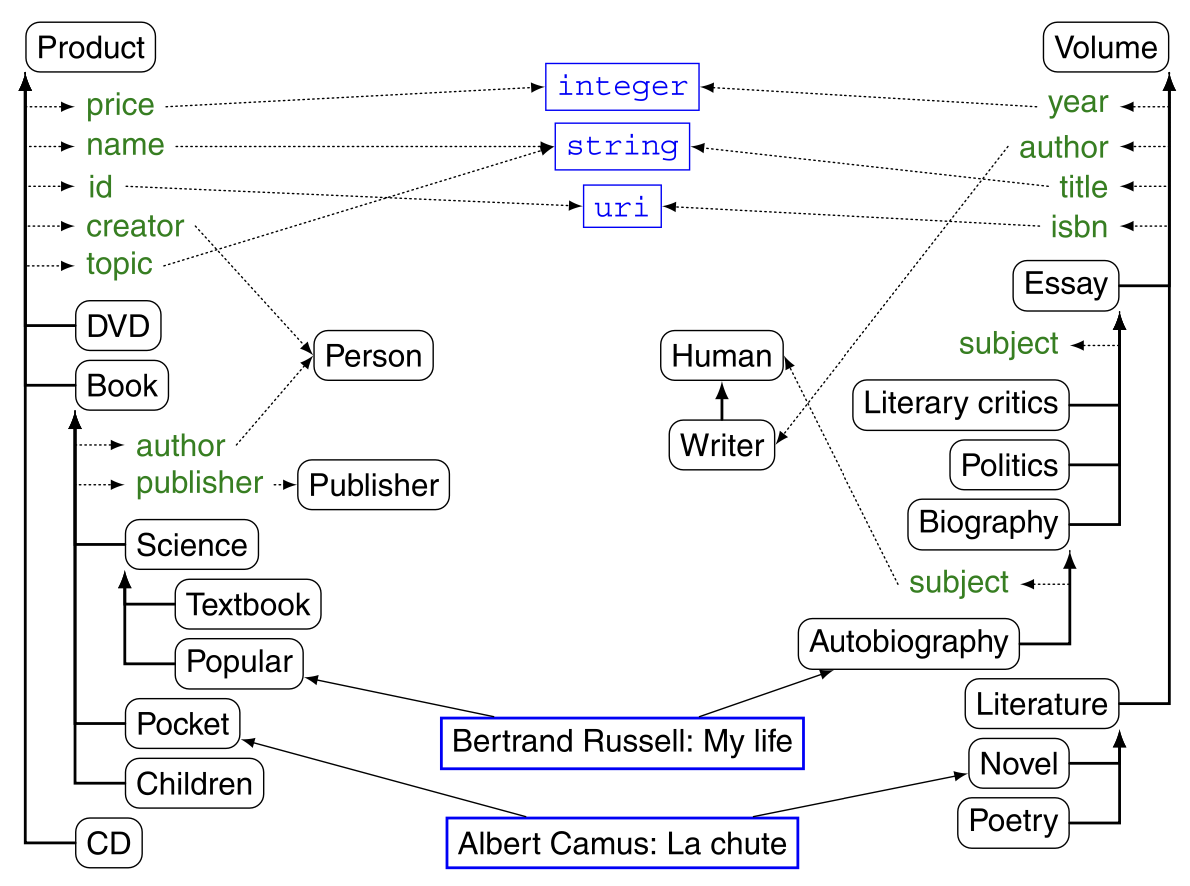
これらの関係を前回のProductとVolumeのオントロジーの関係(下図)を利用する例に適用すると、Book の subClass に基づく関係は次のようになる。

subclass(Book) = subclass– (Book) = {Science, Pocket, Children}.
= subclass+ (Book) = {Science, Pocket, Textbook, Popular, Children}
= subclass-1(Book) = {Product}
= subclass↑(Book) = {Textbook, Popular, Pocket, Children}
下表は、他のエンティティとの関係に基づいて2つのオントロジーエンティティを比較するさまざまな方法を示している。もちろん、アプローチは上記の基準のいくつかを組み合わせてもよい(Mädche and Staab 2002; Euzenat and Valtchev 2004; Bach et al. 2004)。

上表からわかるように、いくつかの特徴はタイプがStringであり、以前に述べた技術と比較することができる。しかし、ClassやPropertyといったタイプのものは、本当にグラフ構造を引き起こす。さらに、Set(-)でラベル付けされた値は、その特徴でラベル付けされた多くのエッジがグラフに現れることを意味するため、取り扱いが難しくなる。表の最後の部分は、実際、前回述べた拡張手法に関連している。
関係構造技術でこれまで考慮されてきた関係には、分類学的関係、メレオロジック関係、すべての関係の3種類がある。これらを以下に述べる。
Taxonomic(分類学的な構造)
taxonomic(分類学的)構造、すなわちsubClassOf関係で作られたグラフは、オントロジーのバックボーンとなる。このため、研究者によって詳細に研究されており、クラスをマッチングするための比較ソースとして非常によく使用されている。
taxonomic(分類学的)構造に基づいてクラスを比較するために、いくつかの方法が提案されている。最も一般的なものは、2つのクラス間の分類学上のエッジの数をカウントすることに基づくものとなる。階層上の構造的なトポロジーの非類似性(Valtchev and Euzenat 1997)は、グラフ距離、すなわち、ここでは階層の推移的還元として取られるグラフの最短パス距離に従う。
定義6.3 (階層上のトポロジカルな構造的非類似度) トポロジカルな構造的非類似度δ : o × o → Rは、 階層H = ⟨o, ≤⟩上の非類似度であり、次のようになる。
\[ \forall e,e’\in o,\ \delta(e,e’)=\min_{c\in o}[\delta(e,c)+\delta(e’,c)]\]
ここで、δ(e, c)は、ある要素eと別の要素cの間の中間エッジの数となる。
これは、単位木の距離、すなわち、各エッジに重み1をつけたものに相当する(Barthélemy and Guénoche 1992)。この関数は、taxonomy上の2つのクラス間のパスの最大長で正規化することができる。
\[ \overline{\delta}(e,e’)=\frac{\delta(e,e’)}{\max_{c,c’\in o}\delta(c,c’)}\]
構造的トポロジカル非類似性の例は、下図の分類法に基づいて提供されるものとなる。ここでは、各用語がクラスに対応し(すべての意味を一緒に考える)、階層のトップが存在する(Person、litterate、legal document、Godの上)と考える。
 ここでも、最も近いクラスがwriterとauthorであるというWordNetデータが裏付けられている。
ここでも、最も近いクラスがwriterとauthorであるというWordNetデータが裏付けられている。
クラス階層の長いパスは、しばしば代替の短いパスに要約されることがあるので、このような尺度によって与えられる結果は、必ずしも意味的に適切ではない。
似たような尺度として、Leacock-Chodorow (Leacock et al. 1998) のものがあり、これは最短パスの長さの関数となる。これは辞書式分類法のために導入されたもので、この種のより精巧な尺度は、Wu-Palmer類似度(Wu and Palmer 1994)として知られている。この類似度指標は、階層のルートに近い2つのクラスは、エッジの点では互いに近いが、概念的には非常に異なる場合があり、一方で、より多くのエッジで区切られている一方の下の2つのクラスは、概念的に近いはずであるという事実を考慮している。最初のWu-Palmer類似度は、通常のグラフ理論的なエッジカウントを使用する代わりに、パスの長さとしてノードをカウントすることによって設計されている。
我々はエッジの観点からの定式化を好むが(Resnik 1999)。オントロジーマッチングで使用する場合、この違いはほとんど関係ない。
定義6.5 (Wu-Palmer類似性) Wu-Palmer類似性σ : o × o → Rは、 階層H = ⟨o, ≤⟩上の類似性であり、次のようになる。
\[ \sigma(c,c’)=\frac{2x\delta(c∧c’,\rho)}{\delta(c,c∧c’)+\delta(c’,c∧c’)+2x\delta(c∧c’,\rho)}\]
ここでρは階層のルート、δ(c,c′)はクラスcと他のクラスc′との間のエッジの数、c∧c′={c′∈o; c≦c′ ≦c′}である。
Wu-Palmersimilarityの例であるWu-Palmersimilarityalsopは、WordNetの構造と一致する絵を提供している。

cotopic similarityは、Jaccard similarityをcotopiesに適用したものとなる。これは(Mädche and Zacharias 2002)で説明されており、以下のように定義されている。
定義 6.7 (上向きcotopicの類似性) 上向きcotopicの類似性 σ : o × o → Rは、 階層H = ⟨o, ≤⟩上の類似性であり、以下のようになる。
\[ \sigma(c,c’)=\frac{|UC(c,H)\cap UC(c’,H)|}{|UC(c,H)\cup UC(c’,H)|}\]
ここで,UC(c,H) = {c′ ∈ H; c ≤ c′}は,cのスーパークラスの集合(superclass+(c))となる。
以下の例 (上向きのcotopicの類似性) では、すべてのsensesがcotopicにカウントされるため (経路的に最も近いものではなく)、結果は他の尺度とは異なるものとなる。creatorは、authorとillustratorのスーパークラスとしての立場から、通常のwriterとcreatorのペアよりも良いスコアを得ることができるが、それは彼らがあまりにも多くの無関係なsensesを持っているからである。

これらの尺度は、オントロジーマッチングの文脈では、オントロジーが同じタクソノミーHを共有していないことが想定されるため、そのまま適用することはできないが、WordNetなどの共通知識のリソースと組み合わせて使用することができる。そのためには、一対のオントロジーに対してこの種の尺度を開発することが必要となる。例えば(Valtchev 1999; Euzenat and Valtchev 2004)では、比較される要素(例えば、階層)間の(ローカル)マッチングを使用している。
クラス間の類似性を評価するために分類法全体を考慮するこれらのグローバルな尺度の他に、オントロジーマッチングでは非グローバルな尺度も使用されている。以下に、それらの尺度のいくつかを紹介する。
スーパークラスまたはサブクラスのルール : マッチャーの中には、「スーパークラスやサブクラスが似ていれば、クラスは似ている」という直感を捉えたルールに基づいているものがある。例えば、スーパークラスが同じであれば、実際のクラスはお互いに似ている。サブクラスが同じであれば、比較されるクラスも似ている(Dieng and Hug 1998; Ehrig and Sure 2004)のようなものになる。この手法には、少なくとも2つの欠点がある。(1)複数のサブクラスやスーパークラスがある場合、気をつけないとそれらがすべて同じクラスにマッピングされてしまうので、他の識別機能が必要であること、(2)サブクラスやスーパークラスの間の類似性は、そのスーパークラスやサブクラスの類似性に依存することなどとなる。これらにより、この問題はさらに別のグローバルな類似性の問題に変わる。
バウンデッドパスマッチング:バウンデッドパスマッチャーは、階層関係で定義されたクラス間のリンクを持つ2つのパスを取り、これらのパスに沿って用語とその部位を比較し、類似する用語を特定する。この技術は後述のAnchor-Promptで導入されている。例えば、図2.9において、BookがVolumeに対応し、PopularがAutobiographyに対応する場合、パスに沿った要素(一方ではScience、他方ではBiographyとEssay)の対応を慎重に検討する必要がある。例えば、EssayはScienceよりも一般的であると判断するためとなる。この手法は、主に2つのパスのアンカーに導かれ、最適なマッチを選択するための代替手法を使用している。
また、編集距離は、文字列以外の構造、特に木(Tai 1979)にも適用できる。次回はグローバルマッチングのもう一つの手法であるメレオロジックなアプローチについて述べる。

AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.
