人工知能技術 ウェブ技術 知識情報処理技術 セマンティックウェブ技術 自然言語処理 機械学習技術 オントロジー技術 オントロジーマッチング技術
前回に引き続きオントロジーマッチングより自然言語の類似性について。前回は、データの型やドメインの情報等の内部構造を領したアプローチについて述べた。今回はそれらを更に拡張したアプローチについて述べる。
個々の表現(またはインスタンス)が利用可能な場合は、マッチングシステムにとって非常に都合の良いケースとなる。2つのオントロジーが同じインディビジュアルのセットを共有している場合、マッチングは非常に容易になる。例えば、2つのクラスが全く同じ個人のセットを共有している場合、これらのクラスは同等であると強く推定することができる。
クラスが同じ個人の集合を共有していない場合でも、簡単には変更されない有形の指標に基づいて照合処理を行うことができる。例えば、本のタイトルは変化する理由がない。つまり、本のタイトルが違えば、それは同じ本ではないということになる。そうすると、マッチングは再び個々の比較に基づいて行われることになる。
このようにして、拡張手法を、(1)共通のインスタンスセットを持つオントロジーに適用するもの、(2)従来の手法を用いる前に個別の識別技術を提案するもの、(3)識別を必要としない、つまり異種のインスタンスセットに適用するものの3つに分類することができる。
一般的な拡張機能の比較
インスタンスを共有しているクラスを比較する最も簡単な方法は、インスタンス集合AとBの相互関係をテストし、A∩B =A=Bの場合はこれらのクラスが非常に似ており、A∩B =BまたはA∩B =Aの場合はより一般的であると考えることとなる。再関係とエンティティセットは、主に集合関係に基づいて統合することができる。
- 等しい(A∩B =A=B)、
- 含まれている(A∩B =A)、
- 含まれている(A∩B =B)、
- 分離している(A∩B =∅)、
- 重複している
(Larson et al. )これらの課題は欠陥への対応力となる。少量の誤ったデータがあると、システムはドメインの関係について誤った結論を出す可能性がある。さらに、非類似度は、これらのケースのいずれにも当てはまらない場合には1でなければならない。例えば、クラスが共通のインスタンスをいくつか持っているが、すべてではない場合などである。
これを改良する方法として、2つの拡張子の間のハミング距離を使用することができる。これは、対称的な差の大きさを和の大きさで正規化したものに相当する。
定義 36 (Humming距離) 二つの集合の間のHumming距離は、∀x, y⊆Eとなる非類似関数δ : 2E × 2E → Rである。
\[\delta(x,y)=\frac{|x\cup y-x\cap y|}{|x\cup y|}\]
この対称差のバージョンは正規化されている。このような距離を使用して集合を比較することは、等式を使用するよりもロバスト性がある。
また、インスタンスの集合の確率的な解釈に基づいて、類似性を計算することもできる。これはJaccard類似度(Jaccard 1901)の場合となる。
定義 37 (Jaccard類似度) 2つの集合AとBが与えられたとき、 P (X)を集合Xに含まれるランダムなインスタンスの確率とすると、 Jaccard類似度は次のように定義される。
\[ \sigma(A,B)=\frac{P(A \cap B)}{P(A\cup B)} \]
この指標は正規化されており、A∩B=φの時に0、A=Bの時に1となる。この指標は、異なるオントロジーの2つのクラスが同じインスタンスの集合を共有する場合に使用できる。
形式的な概念分析
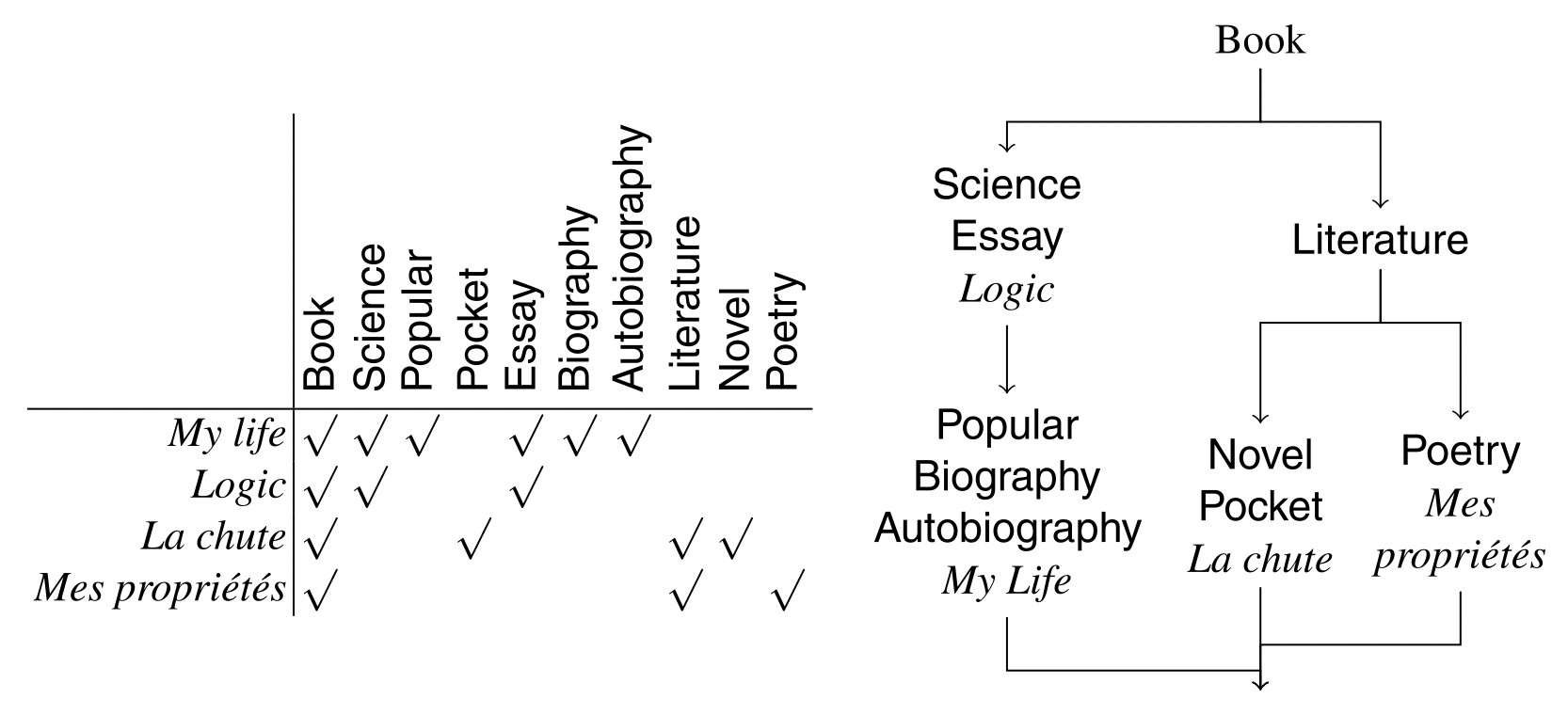
形式概念分析(FCA)(Ganter and Wille 1999)のツールの1つに、概念格子の計算がある。形式的概念分析の背景にある考え方は、対象物(ここでは個体)の集合とそのプロパティの間の二重性となる。したがって、プロパティを持つ対象の集合は、これらの対象をカバーする概念の格子に整理することができる。各概念は、そのプロパティ(意図)によって識別され、そのプロパティを満たす個人(範囲)をカバーする。
オントロジーマッチングでは、プロパティは単純に、インディビジュアルが属することが知られているクラスであればよく、この手法は、エンティティの起源、すなわち、同じオントロジーから来ているかどうかに依存しない。このデータセットから、形式概念分析は概念格子(またはガロア格子)を計算する。これは、インスタンス×プロパティのガロア接続の閉鎖を計算することで行われる。この操作は、エクステントのパワーセットの完全な格子から始まり、接続の下で閉じているノードのみを保持する。すなわち、プロパティのセットから始まり、個体の対応するセットを決定し、それ自体がプロパティの対応するセットを提供する。このセットが初期のものであれば、それは閉じているので保持され、そうでなければノードは破棄される。その結果、概念格子が得られる。

上図の表には、インスタンスの小さなセットと、それらが属するクラス(両方のオントロジーから)が表示されている。上図の右側には、対応する概念の格子が表示されています。この格子から、以下のような対応関係を抽出することができる。

この結果は正確ではない。しかし、まず冗長な対応関係を排除し、対応関係でカバーされる範囲の大きさに応じて信頼度を与えることで、これらの結果に重み付けをすることが可能となる。
インスタンス識別のためのテクニック
共通のインスタンスセットが存在しない場合、一方のセットのどのインスタンスが他方のセットのどのインスタンスに対応するかを特定しようとすることが可能となる。この方法は、インスタンスが同じであることがわかっている場合に有効になる。例えば、同じ会社の2つの人事データベースを統合する場合には有効だが、異なる会社のデータベースや、関係性のないイベントのデータベースには適用できない。
このようなアプローチは、リンクデータの登場により、最近注目されている。実際、データの相互リンクはリンクデータの重要なタスクであり(Köpcke and Rahm 2010; Ferrara et al. 2011b)、多くのアルゴリズムが再開発されている。オントロジーマッチングは、対応関係を用いてインスタンスレベルの潜在的なリンクを検索することにより、恩恵を受けることができる(Nikolov et al. 2009; Scharffe and Euzenat 2011)。一方、データの相互リンクによって生成されたリンクは、マッチングするオントロジーのインスタンスを特定するための機会を提供する。このようにして、データのウェブからのリンクを使用するマッチャーが開発されている。これは、より良いアラインメントがより良いリンクデータを提供し、それがより良いアラインメントを提供するフィードバックループとなる。以下、そのような技術を説明する。
リンクキーの抽出
インスタンスを識別するための最初の自然な手法は、データセットのキーを利用することにある。キーには、データセットの内部に存在するもの、つまり一意のサロゲートが生成されたもの(この場合、識別にはあまり役に立たない)、外部に存在するもの(この場合、これらの識別キーが両方のデータセットにキーとして存在していなくても存在している可能性がある)。このような場合、それらがキーとして使用されていれば、(isbnのように)個人を一意に識別することができる。
一般的に、本当に求められているのは、リンクキーと呼ばれるものである。つまり、クラスのペアに対して、同じ個人を記述するインスタンスのペアを識別する、両方のオントロジーのプロパティのセットである。リンクキーは、両データセットのエンティティを明確に識別するものでなければならない。つまり、同じ値を持つインスタンスを識別するために、両データセットのプロパティ間の対応関係を提供する必要がある。また、対応関係によって選択されたインスタンスに対してのみ曖昧さがないようにしなければならず、これらのセットに対してのみキーが存在しなければならない。

書店のキーは{isbn},{title,first name},{title,last name}、そして図書館のデータソースでは{orig, translator}となる。
リンクキーは、⟨{title, lastname}, {author, orig}, {title = orig, lastname = author}⟩となる。つまり、リンクキーは書店データセットの非最小キーを使用している。なぜなら、図書館データセットには最小キー{isbn}に対応するものがないからである(したがって、isbnを含む対応関係はない)。さらに驚くべきことに、リンクキーは図書館データセットのキーを使用していない。なぜなら、(i)書店データセットには翻訳者のプロパティに対応するものがなく、(ii)使用されているプロパティのセットは、リンクを曖昧さなく生成するのに十分だからである(これは、⟨year = 1822,author = Quincey,orig = Confessions,translator = Baudelaire⟩というタプルが図書館データセットに存在していれば違うものとなっていた)。
⟨{title, lastname, lang}, {ttitle, author}, {lastname = author, title = translate(title, lang)}⟩のように、より精巧なリンクキーを設定することも可能であり、これはorigの列が利用できない場合に有用である。このようなリンクキーは、単位変換が必要な場合に便利なものとなる。
この例からもわかるように、リンクキーの3番目の要素は、文字通りプロパティ間のアライメントになる。原理的には、キーの抽出は、2つのインスタンスが同じ値を持たないプロパティの最小サブセットを分離する代数的な技術によって行われる。リンクキーも同様に、プロパティ間の対応関係(等価性)を考慮し、インスタンスをインスタンスのペアで置き換えることで処理することができる。しかし、リンクされたデータセットはオープンであり、しばしば非完全な品質であることを考慮すると、データセット内で持っているスーパーポートを最大化するキーを見つける技術を開発することが有用となる(Atencia et al.2012b)。オントロジーの拡張を扱う際のもう一つの問題は、プロパティやリレーションが複数の値を持つ場合のキーの定義となる。
類似性に基づくインスタンスマッチング
キーが存在しない場合や、キーが異なる場合には、インスタンスデータを用いてプロパティの値を比較し、プロパティの対応関係を判断するアプローチもある。データベースでは、この技術は、レコードリンケージ(Fellegi and Sunter 1969; Elfeky et al.2002)またはオブジェクト識別(Lim et al.1993)として知られている。これらの技術は、オブジェクトの集合の中で、同じオブジェクトの複数の表現を識別することを目的としている。これらは通常、文字列ベースおよび内部構造ベースの技術に基づいている。
キーで識別できないインスタンスを扱うデータインターリンカーのほとんどは、同じスキーマで動作している(Ngomo and Auer 2011; Araújo et al. Silk (Section. 12.4.2)のようなフレームワークでは、これらの2つのステップを正確に記述することができる。このフレームワークは、類似性測定をプラグインしたり集約したりするための言語を提供する。考慮される類似性測定は、通常、この章で考慮されるものとなる。さらに、考慮すべきデータタイプに特化した尺度も開発されており、たとえば、地理的なエリアや住所を一致させるための尺度などがある。
データは通常、オントロジーによって記述されるため、クラスは関連する第一レベルのブロックとなる。したがって、KnoFuss(セクション12.4.1)のようないくつかのデータインターリンカーは、インスタンスが比較されるクラスを制約するオントロジーのアライメントを入力として取ることができる。
最後に、リンクされたデータのサイズは通常オントロジーのサイズよりも大きいことを考えると、2つの理由から類似性の学習がより重要になる。
– データのサイズが大きいと、最適なアプローチを選択するためにデータを調査することが困難になり、トレーニングサンプルを抽出した後に多くの作業が必要になる。
– データの規則性は、機械学習の効率化を促進する。
そのため、”遺伝的プログラミング(Genetic Programming, GP)の概要とアルゴリズム及び実装例について“で述べている遺伝的プログラミング(Section.7.6.2)などの学習法がデータの相互リンクに用いられてきたことは驚くことではない(Ngomo 2011; Isele and Bizer 2013)。値は正確には同じではないが、その分布を比較できる場合は、グローバルな手法を適用することが可能となる。このケースは次のセクションで取り上げる。
Disjoint Extensionの比較
両方のオントロジーに共通するデータセットを直接推論することができない場合、クラス拡張を比較するための近似的な技術を使用することが容易となる。これらの手法は、クラスメンバーの特徴に関する統計的な尺度に基づいていたり、クラスのインスタンス間で計算された類似性に基づいていたり、エンティティセット間のマッチングに基づいていたりしている。
統計的アプローチ
インスタンスデータは、最大値、最小値、平均値、分散、ヌル値の有無、小数の有無、スケール、精度、グループ化、セグメント数など、インスタンスに見られるプロパティ値に関する統計を計算するために使用することができる。これにより、データからクラスのプロパティのドメインを特徴づけることができる。実際には、統計的に代表的なサンプルを扱う場合、これらの尺度は、異なるオントロジーの2つの同等のクラスで同じでなければならない。
統計的マッチングの例、インスタンスを持つ2つのオントロジーを考える。一方のオントロジーの数値特性 size と weight、もう一方のオントロジーの数値特性 hauteur と poids を分析すると、これらの平均値は異なるが、変動係数は同じであることがわかる。これは、値が異なる単位で表されている場合によく見られる現象となる。size/hauteurの平均値の比率は2.54、weight/poidsの平均値の比率は28.35となる。
これらの値は、母集団全体に基づいて設定されている。これらの値は、オントロジーのクラスにおけるこれらのプロパティの統計的特性を比較するために使用することができる。例えば、Pocketクラスのsizeプロパティの平均値は、全人口のそれとは大きく異なり、28.35で割ると、Livredepocheクラスのそれに非常に近い値になる(同じように全人口とは異なる)。したがって、この2つのクラスは似ていると考えられる。
他のアプローチ(Li and Clifton 1994)では、データの値やドメインの代わりに、データのパターンや分布を使用している。その結果、耐障害性が向上し、データサンプリング技術の採用によりデータ値のごく一部しか必要とされないため、時間の消費が少なくて済む。一般的に、内部構造法をインスタンスに適用することで、スキーマ要素の実際の構造をより正確に把握することができ、発見された値の範囲や文字パターンなどに基づいて、対応するデータタイプをより正確に決定することができる。
しかし、これらの方法には1つの前提条件がある。それは、プロパティ間の相関関係が既知である場合にうまく機能するということになる(そうでなければ、ドメインに基づいて異なるプロパティをマッチさせることができる)。これは既に解決すべきマッチング問題となる。
類似性に基づく拡張機能の比較
類似性に基づく手法は、クラスが同じインスタンスのセットを共有している場合にも適用できる。特に、共通拡張に基づいた手法は、2つのクラスがインスタンスを共有していない場合、セットの要素間の距離を無視して、常に0を返す。場合によっては、インスタンスのセットを比較することが望ましいこともある。このためには、他の基本的な方法で得られるインスタンス間の(非)類似性測定が必要となる。
データ分析において、リンケージ集計法は、オブジェクトが類似しているだけの2つのセット間の距離を評価する。これにより、2つのクラスをそのインスタンスに基づいて比較することができる。
定義 40 (単一連結) 非類似関数δ : E × E → Rが与えられたとき、 2つの集合間の単一連結尺度は、 非類似関数Δ : 2E × 2E → Rsuch that∀x,y⊆E,Δ(x,y)=min(e,e′)∈x×yδ(e,e′)となる。
定義 41 (完全連結) 非類似関数δ : E × E → Rが与えられたとき、 2つの集合間の完全連結尺度は、 ∀x,y⊆E,Δ(x,y)=max(e,e′)∈x×yδ(e,e′)となる非類似関数Δ : 2E × 2E → Rである。
定義 42 (平均連結) 非類似関数δ : E × E → Rが与えられたとき、 2つの集合間の平均連結尺度は、非類似関数Δ : 2E ×
その他のリンク手段も定義されている。これらの方法にはそれぞれ利点があり、例えば、最短距離の最大化、最長距離の最小化、平均距離の最小化などがある。同じ系列の別の方法として、ある集合から他の集合の最近接点までの最大距離を測定するHausdorff dis-tanceがある(Hausdorff 1914)。
定義 43(Hausdorff distance) 与えられた非類似関数δ:E×E→Rにおいて、 2つの集合間のHausdorff距離は、∀x, y⊆Eとなる非類似関数Δ : 2E × 2E → Rである。
\[\Delta(x,y)=max\left(\max_{e\in x}\min_{e’\in y}\delta(e,e’),\max_{e’\in y}\min_{e\in x}\delta(e,e’) \right)\]
マッチングベースの比較
前者の距離の問題点だが、平均は、その値が集合のメンバーの1つのペアの間の距離の関数であることにある。一方、平均的な連結は、その値がすべての可能な比較の間の距離の関数である。
マッチングベースの比較(Valtchev 1999)では、比較対象となる要素は互いに対応するもの、つまり最も類似したものであると考える。
そのため、2つのセット間の距離は最小化されるべき値とみなされ、その計算は最適化問題、すなわち、両方のセットの中から互いに対応する要素を見つけることである。具体的には、二部グラフマッチング問題を解くことに相当する。
定義 5.44 (マッチベースの類似性) 類似関数σ : E × E → Rが与えられたとき、 Eの2つの部分集合間のマッチベースの類似性は、 類似関数MSim:2E ×2E →Rsuchthat∀x,y⊆Eである。
\[MSim(x,y)=\frac{max_{p\in Pairings(x,y)}\left(\sum_{<n,n’>\in p}\sigma(n,n’)\right)}{max(|x|,|y|)}\]
Pairings(x,y)は、xの要素からyの要素へのマッピングのセットとなる。
このマッチベースの類似性は、すでにアラインメントが計算されている必要がある。また、必要とされるアライメントの種類にも依存する。実際、アラインメントが注入可能であることが要求されているか否かによって、結果は異なる。マッチベースの比較は、配列を比較する際にも使用できる(Valtchev 1999)。
拡張情報の活用技術についてのまとめ
拡張情報は、オントロジーの概念的な部分とは独立した情報を提供するため、オントロジーマッチングにとって非常に重要なものとなる。実際、オントロジーは世界の見方であり、同じトピックについて多数の異なるオントロジーが存在する(そしてそれらをマッチングさせなければならない)理由はここにある。拡張情報はばらつきが少なく、クラスを正確にマッチさせるために使用できると考えられる。
非常に好ましいケースは、マッチングする2つのオントロジーが同じインスタンスを共有している場合や、インスタンスを簡単につなげることができる場合となる。これにより、2つのクラスのオーバーラップを簡単に比較することができる。しかし、ほとんどの状況では、インスタンス・スペースが異なります。このような場合には、前のケースに戻るために、これらのインスタンスをマッチさせるか、純粋に統計的な手法を用いて、クラスの拡張に対するグローバルな測定値でクラスを比較することが可能となる。
マッチング技術のまとめ
これまで、用語論(5.2節)、内部構造(5.3節)、拡張論(5.4節)に基づいて、対応関係を構築するために使用できる基本的な技術について説明してきた。このような技術の分類は、それぞれがオントロジーの部分的なビューを扱うため、自然なものとなる。
これらの技術を活用するためには、最終的には、これまでに最も使用された技術のパノラマを提案し、その方向性を示すことが肝要となる。それぞれの方向性において、より良い方法を見つけるためには、まだ多くの作業が必要となる。
一般的に、これらの技術は単独で使用されることはない。それらは、よりグローバルな手法の基礎となったり、それぞれの強みを強化するために組み合わせられたりする。これが次項以降のテーマとなる。

AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.
