Introduction
Fine tuning of large-scale language models is an additional learning process on models that have been previously trained on a large data set, and is intended to enable general-purpose models to be applied to specific tasks and domains, thereby improving accuracy and performance. It has the following characteristics
1. training on task-specific data: While large-scale language models are trained for general language understanding, when applied directly to specific tasks, they need to be retrained (fine-tuned) on task-specific data. For example, in tasks such as sentiment analysis, question answering, and text generation, fine tuning these models allows them to be adapted to the characteristics of the task.
2. task-specific performance improvement: Fine tuning can improve the performance of large-scale language models in specific tasks. For example, fine tuning a large-scale language model in a specific domain or industry, such as medical document classification, financial information summarization, or legal document summarization, can improve accuracy and efficiency in that task.
3. effective use of small data sets: In many cases, there is limited data relevant to a particular task or domain. In such cases, fine-tuning a large-scale language model can still be used to build an effective model with less data. Large-scale models perform well with small amounts of task-specific data because of their knowledge of general language understanding.
4. domain adaptation: Companies and research institutions have unique data and domain-specific needs, and by fine tuning large-scale language models, they can easily create models that are adapted to that specific domain. For example, language models can be created specific to various industries and fields, such as medicine, law, finance, etc.
5. use of labeled data: Fine tuning of large-scale language models enables the effective use of labeled data. While labeled data is generally difficult to obtain, large-scale language models can automatically generate labeled data from unlabeled data, which can then be used to fine-tune the model.
6. increased resource efficiency: While pre-training of large-scale language models requires a large amount of computational resources, fine tuning requires relatively few resources, and thus fine tuning of pre-trained models can produce high-performance models while conserving resources.
Fine tuning of CNN using Keras
In deep learning, fine tuning of learned models is often used, as described in “Deep Learning with Python and Keras for Computer Vision (3) Improving CNNs using Learned Models“. Below we describe an example implementation of fine tuning in a CNN using Keras.
import tensorflow as tf
from tensorflow.keras.applications import VGG16
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.layers import Dense, Dropout, Flatten
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
# Number of classes to fine tune
num_classes = 10
# Image Size
img_rows, img_cols = 224, 224
# Learning rate
learning_rate = 0.0001
# Loading pre-trained VGG16 models
base_model = VGG16(weights='imagenet', include_top=False, input_shape=(img_rows, img_cols, 3))
# Get the last layer of the VGG16 model
x = base_model.output
x = Flatten()(x)
# Add new full-coupling layer
x = Dense(512, activation='relu')(x)
x = Dropout(0.5)(x)
# New all-join layer added (number of outputs corresponds to number of classes)
predictions = Dense(num_classes, activation='softmax')(x)
# Create a new model (add a new layer to an existing VGG16 model)
model = Model(inputs=base_model.input, outputs=predictions)
# Existing VGG16 layers should not be relearned
for layer in base_model.layers:
layer.trainable = False
# Model Compilation
model.compile(optimizer=Adam(lr=learning_rate), loss='categorical_crossentropy', metrics=['accuracy'])
# Data Extension Settings
train_datagen = ImageDataGenerator(
rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True
)
test_datagen = ImageDataGenerator(rescale=1./255)
# Directory of training and test data
train_dir = 'path_to_training_data_directory'
test_dir = 'path_to_test_data_directory'
# Generation of training data
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(img_rows, img_cols),
batch_size=32,
class_mode='categorical'
)
# Test Data Generation
test_generator = test_datagen.flow_from_directory(
test_dir,
target_size=(img_rows, img_cols),
batch_size=32,
class_mode='categorical'
)
# Model Learning
history = model.fit(
train_generator,
steps_per_epoch=len(train_generator),
epochs=10,
validation_data=test_generator,
validation_steps=len(test_generator)
)This example describes how to fine-tune a VGG16 model using Keras in a CNN and apply it to a new data set.
Fine tuning of Transformer model using HuggingFace
When fine-tuning a Transformer model, the Hugging Face Transformers library is usually used, as described in “Overview of Automatic Sentence Generation with Hugging Face“. Here is an example of fine tuning a pre-trained Transformer model (e.g., BERT, RoBERTa, etc.) using the Hugging Face Transformers library.
import torch
from transformers import BertTokenizer, BertForSequenceClassification
from torch.utils.data import DataLoader
from transformers import AdamW
from transformers import get_linear_schedule_with_warmup
from tqdm import tqdmThe next step is to set up for fine tuning.
# Device configuration (use GPU if available)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# parameter
MAX_LEN = 128
BATCH_SIZE = 16
EPOCHS = 3
LEARNING_RATE = 2e-5
# Data Set Path
train_data_path = "path_to_train_dataset"
val_data_path = "path_to_validation_dataset"
# Load pre-trained BERT models and tokenizers
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# Move model to device
model.to(device)
# Data set loading and tokenization
class CustomDataset(torch.utils.data.Dataset):
def __init__(self, tokenizer, data_path):
self.tokenizer = tokenizer
self.data = []
with open(data_path, 'r') as f:
for line in f:
text, label = line.strip().split('t')
self.data.append((text, int(label)))
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
text, label = self.data[idx]
inputs = self.tokenizer.encode_plus(
text,
None,
add_special_tokens=True,
max_length=MAX_LEN,
pad_to_max_length=True,
return_token_type_ids=True,
truncation=True
)
return {
'input_ids': torch.tensor(inputs['input_ids'], dtype=torch.long),
'attention_mask': torch.tensor(inputs['attention_mask'], dtype=torch.long),
'token_type_ids': torch.tensor(inputs["token_type_ids"], dtype=torch.long),
'labels': torch.tensor(label, dtype=torch.long)
}
# Create a dataset
train_dataset = CustomDataset(tokenizer, train_data_path)
val_dataset = CustomDataset(tokenizer, val_data_path)
# Create DataLoader
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=BATCH_SIZE, shuffle=False)
# Optimizer and Scheduler Settings
optimizer = AdamW(model.parameters(), lr=LEARNING_RATE, eps=1e-8)
total_steps = len(train_loader) * EPOCHS
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=0, num_training_steps=total_steps)Finally, a fine-tuning loop is performed.
# Fine Tuning Loop
for epoch in range(EPOCHS):
model.train()
train_loss = 0.0
for batch in tqdm(train_loader, desc=f"Epoch {epoch + 1}/{EPOCHS}"):
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
token_type_ids = batch['token_type_ids'].to(device)
labels = batch['labels'].to(device)
model.zero_grad()
outputs = model(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
labels=labels)
loss = outputs.loss
train_loss += loss.item()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
scheduler.step()
# Validation Evaluation
model.eval()
val_loss = 0.0
val_corrects = 0
val_total = 0
with torch.no_grad():
for batch in tqdm(val_loader, desc=f"Validating Epoch {epoch + 1}/{EPOCHS}"):
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
token_type_ids = batch['token_type_ids'].to(device)
labels = batch['labels'].to(device)
outputs = model(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
labels=labels)
loss = outputs.loss
val_loss += loss.item()
_, preds = torch.max(outputs.logits, 1)
val_corrects += torch.sum(preds == labels).item()
val_total += labels.size(0)
train_loss /= len(train_loader)
val_loss /= len(val_loader)
val_acc = val_corrects / val_total
print(f"Epoch {epoch + 1}/{EPOCHS}, Train Loss: {train_loss}, Val Loss: {val_loss}, Val Acc: {val_acc}")In this example, the BERT model is applied to a sentence binary classification task.
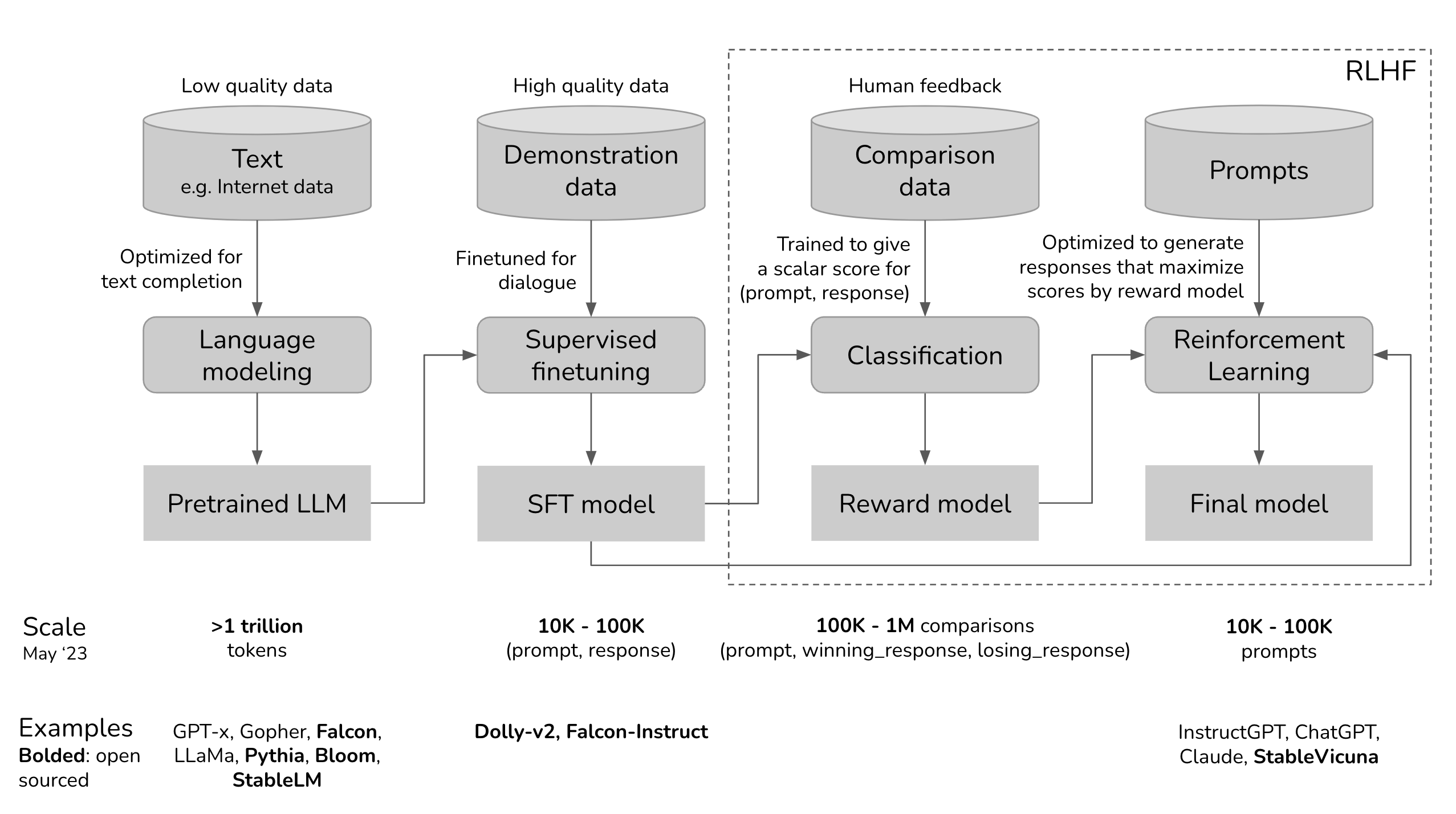
RLHF(Reinforcement Learning from Human Feedback)
RLHF (Reinforcement Learning from Human Feedback) is a method for training reinforcement learning agents as described in “Theory, Algorithms, and Python Implementations of Various Reinforcement Learning Techniques” using human feedback.
Specifically, a reward reflecting human preferences is assigned as a scalar value to the text actually generated by the instruction-tuned model described below, and the instruction-tuned model is fine-tuned to maximize this reward.
The specific configuration is shown in the figure below.”RLHF: Reinforcement Learning from Human Feedback”

The wavy line in the figure above is the part that is repeated in RLHF.
In this way, RLHF does not learn by using human-assigned rewards as they are, but rather learns a model that predicts rewards, and such a model is called reward modeling.
The first step in this process is to construct a dataset of manually labeled prompt-text pairs as superior to each other. Next, this dataset is used to train a reward model that predicts a scalar value of reward for any given prompt and text.
The key to this approach is the method of creating the dataset, the simplest of which is to have a human directly assign a scalar value to the text, but this is difficult to scale across workers when multiple people are working on a task and results in a lot of noise, so multiple texts for a single prompt are Therefore, we take the approach of creating a dataset by generating multiple texts for a single prompt and ranking them.
For example, for a given prompt, we generate K=4 to K=9 texts, rank them, use something like a sigmoid function as a loss function to increase the difference in scores between favorable and unfavorable ones, and perform reinforcement learning on them. Furthermore, when reinforcement learning is performed, regularization constraints are applied to prevent overlearning and bias toward certain models.
There are a variety of approaches to reinforcement learning, including REINFORCE (Monte Carlo Plocy gradient method), which is described in “Overview of REINFORCE (Monte Carlo Policy Gradient), Algorithm and Implementation Examples” as a policy gradient method. Monte-Carlo Plocy gradient) and PPO (proximal policy optimization) as described in “Overview of Proximal Policy Optimization (PPO), Algorithms, and Examples of Implementations“.
RLHF is especially useful in education, medicine, robotics, and digital assistants, where it can effectively incorporate human knowledge and feedback to improve agent performance and learning speed, and enable more flexible and effective behavior in complex real-world environments. effective behavior.
Example of RLHF (Reinforcement Learning from Human Feedback) implementation
As an example of RLHF (Reinforcement Learning from Human Feedback) implementation, we show how to train an agent based on human feedback. Here is an example of RLHF in a simple situation using Q-Learning (Q-Learning) as described in “Overview of Q-Learning, Algorithm and Example Implementation“.
import numpy as np
# Number of agent states and actions
num_states = 5
num_actions = 2
# Initialization of Q table
Q_table = np.zeros((num_states, num_actions))
# Function to update Q values based on feedback
def update_Q(state, action, feedback, alpha):
if feedback > 0:
Q_table[state, action] += alpha * feedback
# Agent learning and action selection
def agent_action(state):
# Agent action selection (e.g., epsilon-greedy method)
epsilon = 0.2
if np.random.rand() < epsilon:
action = np.random.randint(num_actions)
else:
action = np.argmax(Q_table[state])
return action
# Update with learning and receiving feedback on an episode-by-episode basis
def train_agent(num_episodes):
alpha = 0.1 # Learning rate
for episode in range(num_episodes):
# Initial agent state setting
state = np.random.randint(num_states)
# Agent's choice of action
action = agent_action(state)
# Simulate human feedback (e.g., 1 is correct, -1 is incorrect)
feedback = np.random.choice([1, -1])
# Q-value update
update_Q(state, action, feedback, alpha)
# Outputs learning progress
print(f"Episode {episode + 1}/{num_episodes}, State: {state}, Action: {action}, Feedback: {feedback}")
# Perform agent training
train_agent(num_episodes=10)
In this example, the number of states is 5 and the number of actions is 2 in a simple situation. The agent is trained using Q-learning and updates the Q value based on feedback from the human in each state.
In practice, this is not such a simple example, and the following innovations are needed when applying RLHF to real-world problems.
1. Obtaining feedback: In real-world applications, it is important to have a way to obtain feedback from humans, e.g., asking users for feedback via the user interface.
2. Agent state and behavior: appropriate states and behaviors need to be defined for the actual problem, and the way states and behaviors are represented is also important.
3. Agent learning algorithms: In addition to Q-learning, reinforcement learning algorithms and other machine learning algorithms may be used. The appropriate algorithm should be selected according to the nature of the task and the problem setting.
4. Tuning of hyperparameters: Hyperparameters such as learning rate and epsilon in the epsilon-greedy method need to be tuned appropriately.
5. Real-world applications: When applying RLHF to real-world problems, aspects such as security, privacy, and ethics should also be considered.
Other Fine Tuning Techniques
Another method of fine tuning is instruction tuning. For example, in 2021, Google proposed FLAN (Finetuned Language Net) in the paper “Finetuned Language Models Are Zero-Shot Learners,” Google’s 2021 FLAN (Finetuned Language Net) paper, for example, reported that fine tuning a large model with 137 billion parameters, equivalent to GPT3, on 62 aggregated datasets outperformed GPT3 in zero-shot learning on a large number of tasks.
Here, we use the following template to convert the various task datasets into an instruction tuning dataset format consisting of prompt and output text pairs.

However, directed tuning has some issues: (1) it is difficult to create a large, high-quality data set, and (2) feedback cannot be provided on the output of the model.
As described in “Overview of LLM Fine Tuning by LoRA and Examples of Implementations,” many methods of compressing and fine tuning models have been proposed in recent years. They can be broadly classified into the following three approaches
1. Token-additive: Adding virtual tokens to the input layer to learn features specific to a particular task. The parameters of the pre-trained model itself are frozen without being updated. Three approaches have already been implemented in Huggingface: Prefix Tuning, P Tuning, and Prompt Tuning.
2. Adapter type: add a special sub-module outside the pre-trained model and update its parameters; update the parameters of the Adapter and freeze the parameters of the original pre-trained model; update the parameters of the Adapter and freeze the parameters of the original pre-trained model; update the parameters of the Adapter and freeze the parameters of the original pre-trained model. Applicable for language understanding and text translation/summarization tasks; not included as a PEFT library in Huggingface.
3. LoRA type: The pre-trained model itself is frozen and only the low-rank matrix is updated. After updating the low-rank matrix, the weights of the original pre-trained model are added and the parameters are updated. LoRA and Ada LoRA are implemented in Huggingface’s PEFT library. LoRA enables efficient fine tuning not only for linguistic tasks but also for image tasks, making it an approach with a very broad range of applications.
Reference Information and Reference Books
Reference books “


コメント