Artificial Intelligence Technology Web Technology Knowledge Information Processing Technology Semantic Web Technology Ontology Technology Natural Language Processing Machine learning Ontology Matching Technology
In the previous article, we gave a brief overview of ontology matching strategies. In this article, we will discuss one of those approaches, context-based matching.
Context-Based Matching
When matching two ontologies, there is often no common ground on which to base the comparison. The goal of ontology matching is to find this foundation. This may be accomplished by comparing the content of the ontologies, or by dealing with the context of the ontologies, i.e., the relationship of the ontologies to the environment in which they are used.
This common ground is often found by associating the ontology with external resources. These resources may differ in three specific dimensions
Breadth: whether there are general-purpose resources or domain-specific resources. For example, using a specialized resource, such as the Foundational Model of Anatomy in the medical field, ensures that the concepts in the contextual resource match exactly the corresponding concepts in the ontology. However, using a more general resource increases the likelihood that consistency already exists and is readily available.
Formal: pure ontologies defined in a formal language (external resources are called background knowledge (Giunchiglia et al. 2006c)), less formal resources such as WordNet, and completely informal resources such as Wikipedia. such as DOLCE and FMA. Using formal resources, we can reason within or between these formal models to infer the relationship between two terms; using terminological resources such as WordNet, we can expand the set of meanings covered by a term and increase the number of terms that can represent these concepts. can be done. As a result, there are more opportunities to match terms.
Status: Whether these resources are considered references, such as ontologies or thesauri, or whether they are sets of shared instances or annotated documents.
Contextualization of ontologies is generally achieved by matching these ontologies with a common upper ontology.
An example of using the upper ontology as background knowledge. An example of representing fishery resources (e.g., databases and crayfish) in the DOLCE upper ontology (Gangemi 2004). The objective is to integrate these resources into a common fisheries core ontology. We manually transformed the resources into a lightweight ontology represented according to DOLCE, and used reasoning functions to detect relationships and disjunctions between entities in this ontology.
An example of the use of a domain-specific formal ontology as background knowledge: suppose that the anatomical part of the CRISP directory 1 has to be matched against the anatomical part of the MeSH2 metathesaurus. In this case, the FMA ontology can be used as background knowledge to give context to the matching task. The result of anchoring is a set of matches between the FMA concept and the CRISP or MeSH concept with three types of relations: =, ≤, and ≥.
For example, the concept of brain of CRISP shown in BrainCRISP can be easily anchored to the concept of brain of FMA shown in BrainFMA. Similarly, the concept of head in MeSH, indicated by HeadMeSH, can be anchored to the concept of background knowledge, indicated by HeadFMA. In the reference ontology FMA, there is a relationship between BrainFMA and HeadFMA. Therefore, we can derive that BrainCRISP is a part of HeadMeSH.
Since the domain-specific ontology provided the context for the matching task, the concept of Head was correctly interpreted to mean the upper part of the human body, rather than, for example, the chief person. However, as we can see by replacing FMA with WordNet, this is not so easy: in WordNet, the concept of Head has 33 meanings (as a noun). Finally, as shown in the example, once the context of the matching task is established, various heuristics, such as string-based techniques, can improve the anchoring step.
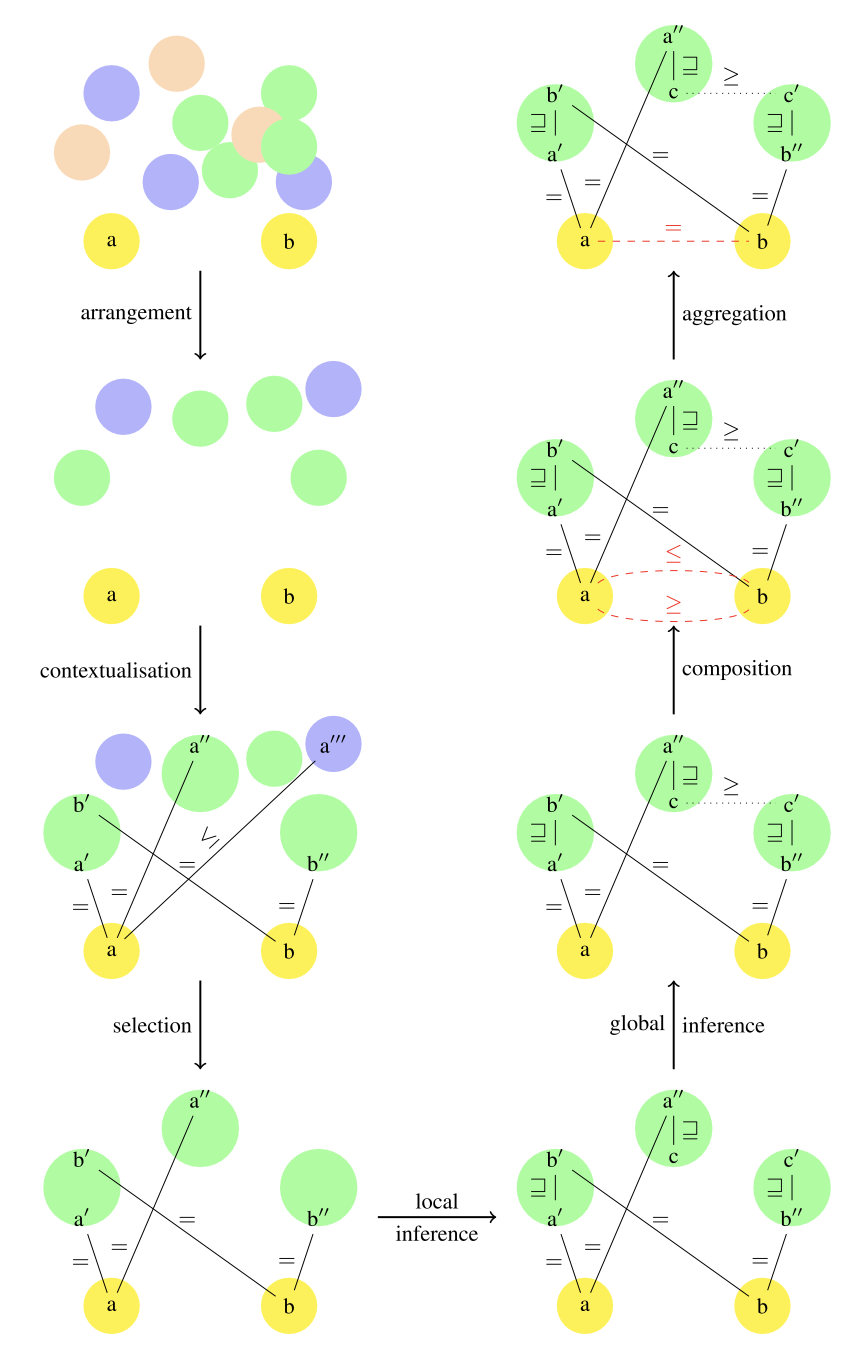
Since context-based matching is very versatile, we synthesize its behavior in a generalized view that aims to cover and extend existing matchers such as Scarlet and OMviaUO. Although this framework describes the use of formal ontologies as background knowledge, it can be applied, for example, to deal with informal resources and linked data. For this purpose, we decompose context-based matching into the seven steps shown in the figure below.

Ontology placement: The ontologies to be explored are pre-selected and ranked as intermediate ontologies. The pre-selection can hold all ontologies in the web or ontologies belonging to a specific type (e.g., top ontology, domain-specific ontology (e.g., medical/biological ontology), competitor, popular ontology, recommended ontology, or customized ontology sets, etc.) can be maintained.
The ordering is based on the likelihood that an ontology is useful or not, usually measured as a distance. Such distances are based on the proximity of the ontology to the ontology to be matched (David and Euzenat 2008), the existence of alignment between ontologies (David et al. 2010), or the availability of quickly computable anchors.
Contextualization (or anchoring) finds anchors between matching ontologies and intermediate ontology candidates. These anchors can be any type of correlation, including various relationships and confidence measures. In principle, any ontology-matching method presented in this book can be used for anchoring. In practice, since anchoring is only a preliminary step, we usually use faster methods such as string matching. In the figure above, a is contextualized as a′, a′, a′′, and b is contextualized as b′, b′′.
The choice of ontology limits the number of candidate ontologies that are actually used. This selection usually depends on the computed anchors, by selecting ontologies with anchors present. In the figure above, the ontologies with no anchors and the blue ontology with only one anchor have been excluded.
Local inference will be the one to find the relationship between entities of a single ontology. Local inference is to obtain relations between entities of a single ontology, and can be reduced to logical induction. Weaker procedures can also be used when intermediate resources do not have a formal meaning, as in a thesaurus. In that case, it can be replaced by using asserted relations from ontologies or relations obtained by synthesizing existing ontologies. In the above figure, b′ encompasses a′ . Other relations such as a′ ⊒ c and c′ ⊒ b′ have also been inferred.
Global inference finds a relation between two concepts in the matching ontology by concatenating the relations obtained by local inference with the correlations between the intermediate ontologies. In the figure above, a′ ≥ b′ can be deduced from the former inference and the new correspondence c ≥ c′.
Composition determines the relations between source and target entities by composing the relations in the path (sequence of relations) connecting the source and target entities. Composition methods include functional (= – = is =), ordinal (< – ≤ is <), and relational (⊥ – ≥ is ⊥) types. In the figure above, there are two paths that support composition, a = a′ ⊑ b′ = b and a = a′ ⊒ c ≥ c′ ⊒ b′ = b, yielding the following assertions.
Aggregation will combine the relations obtained between the same pair of entities. It can simply return all correspondences or only one correspondence with an aggregated relation. The aggregation itself can be based on various methods such as relational aggregation operators, e.g., connection, popularity (selecting the relation obtained from the most paths), and confidence (selecting the relation with the highest confidence). In the figure above, the two former relations are aggregated by connection as a=b.
These steps would be an extension of those provided by Scarlet. Contextualization is called anchoring, selection is considered, local and global reasoning, and synthesis are gathered into a set of “derivation rules”, and aggregation is called combining. in GeRoMeSuite, the sequence (called Selection), anchoring, local reasoning (including synthesis) In GeRoMeSuite, each step of the aggregation process is identified and consistency checks are added to it. In this presentation, we provide a more detailed de composition of context-based matching that can be used to instantiate each step differently.
Context-based matching can be viewed from a completely logical perspective. That is, local and global reasoning can be replaced by entelligence tests, and synthesis and aggregration can be replaced by logical deduction. Beyond anchoring, matching can be reduced to reasoning in a network of ontologies. Thus, once the technology for reasoning in networks of ontologies is fully developed, it will be possible in principle to reduce the above seven steps to anchoring and deduction (see Section 6.5)
The difficulty with context-based matching becomes a matter of balance. Adding context provides new information, which can increase the recall rate, but this new information can also create false correspondences and reduce accuracy. There are many choices about the type of resources to use and how to connect them to the matching ontology.
In the next article, we will discuss another ontology matching, the weighting approach.

コメント