人工知能技術 ウェブ技術 知識情報処理技術 セマンティックウェブ技術 自然言語処理 機械学習技術 オントロジー技術 オントロジーマッチング技術
前回はオントロジーマッチング戦略の概略について述べた。今回はそれらのアプローチのひとつであるコンテキストベースのマッチングに対して述べる。
コンテキストベースのマッチング
2つのオントロジーをマッチングさせる場合、比較のベースとなる共通の基盤がないことが多い。オントロジーマッチングの目的は、この基盤を見つけることである。これは、オントロジーの内容を比較することで達成される場合もあれば、オントロジーのコンテキスト、つまりオントロジーが使用されている環境との関係を扱うことで達成される場合もある。
この共通点は、オントロジーを外部のリソースと関連付けることで見つかることが多い。これらのリソースは、3つの特定の次元で異なる場合がある。
広さ:一般目的のリソースとドメイン固有のリソースがあるかどうか。例えば、医学分野のFoundational Model of Anatomyのような専門的なリソースを使用すれば、文脈に沿ったリソースの概念がオントロジーの対応する概念と正確に一致することが保証される。しかし、より一般的なリソースを使用することで、整合性がすでに存在し、すぐに利用できる可能性が高くなる。
形式:形式的な言語で定義された純粋なオントロジー(外部リソースは背景知識と呼ばれる(Giunchiglia et al. 2006c))、WordNetのようなあまり形式的でないリソース、Wikipediaのような完全に非公式なリソースなど。DOLCEやFMAなどの形式的なリソースを使用すると、2つの用語の関係を推論するために、これらの形式的なモデル内またはモデル間で推論することができる。WordNetなどの用語リソースを使用することで、ある用語がカバーする意味のセットを拡張し、これらの概念を表現できる用語の数を増やすことができます。そのため、用語を一致させる機会が増えている。
状態:これらのリソースがオントロジーやシソーリーなどの参照物とみなされるか、共有されるイン スタンスや注釈付き文書のセットであるかどうか。
オントロジーのコンテクスト化は、一般的に、これらのオントロジーを共通の上位オントロジーと照合することで達成される。
上位オントロジーを背景知識として利用する例。 DOLCE 上位オントロジー(Gangemi 2004)で漁業資源(データベースやザリガニなど)を表現した例を示した。目的は、これらの資源を共通の漁業コアオントロジーに統合することである。手作業でリソースをDOLCEに準拠して表現された軽量なオントロジーに変換し、このオントロジーのエンティティ間の関係や不分離を検出するための推論機能を使用した。
背景知識としてのドメイン固有の形式的オントロジーの使用の例。CRISPディレクトリ1の解剖学的部分をMeSH2メタシソーラスの解剖学的部分と照合しなければならないとする。この場合、FMAオントロジーを背景知識として使用することで、マッチングタスクにコンテキストを与えることができる。アンカリングの結果、FMAの概念とCRISPまたはMeSHの概念との間に、=、≤、≥の3種類の関係を持つマッチのセットができあがる。
例えば、BrainCRISPで示されるCRISPのbrainの概念は、BrainFMAで示されるFMAのbrainの概念に簡単にアンカリングできる。同様に、HeadMeSHで示されるMeSHのheadの概念は、HeadFMAで示される背景知識の概念に固定することができる。参照オントロジーFMAでは、BrainFMAとHeadFMAの間に関係のある部分がある。したがって、BrainCRISPはHeadMeSHの一部であると導き出すことができる。
ドメイン固有のオントロジーがマッチングタスクのコンテキストを提供しているため、Headの概念は、例えばチーフの人を意味するのではなく、人間の体の上部を意味すると正しく解釈されました。しかし、FMAをWordNetに置き換えることでわかるように、これはそれほど簡単なことではありません。WordNetでは、Headの概念は(名詞として)33の意味を持っています。最後に、例で示したように、マッチングタスクのコンテキストが確立されると、文字列ベースのテクニックなど、さまざまなヒューリスティックがアンカリングのステップを改善することができます。
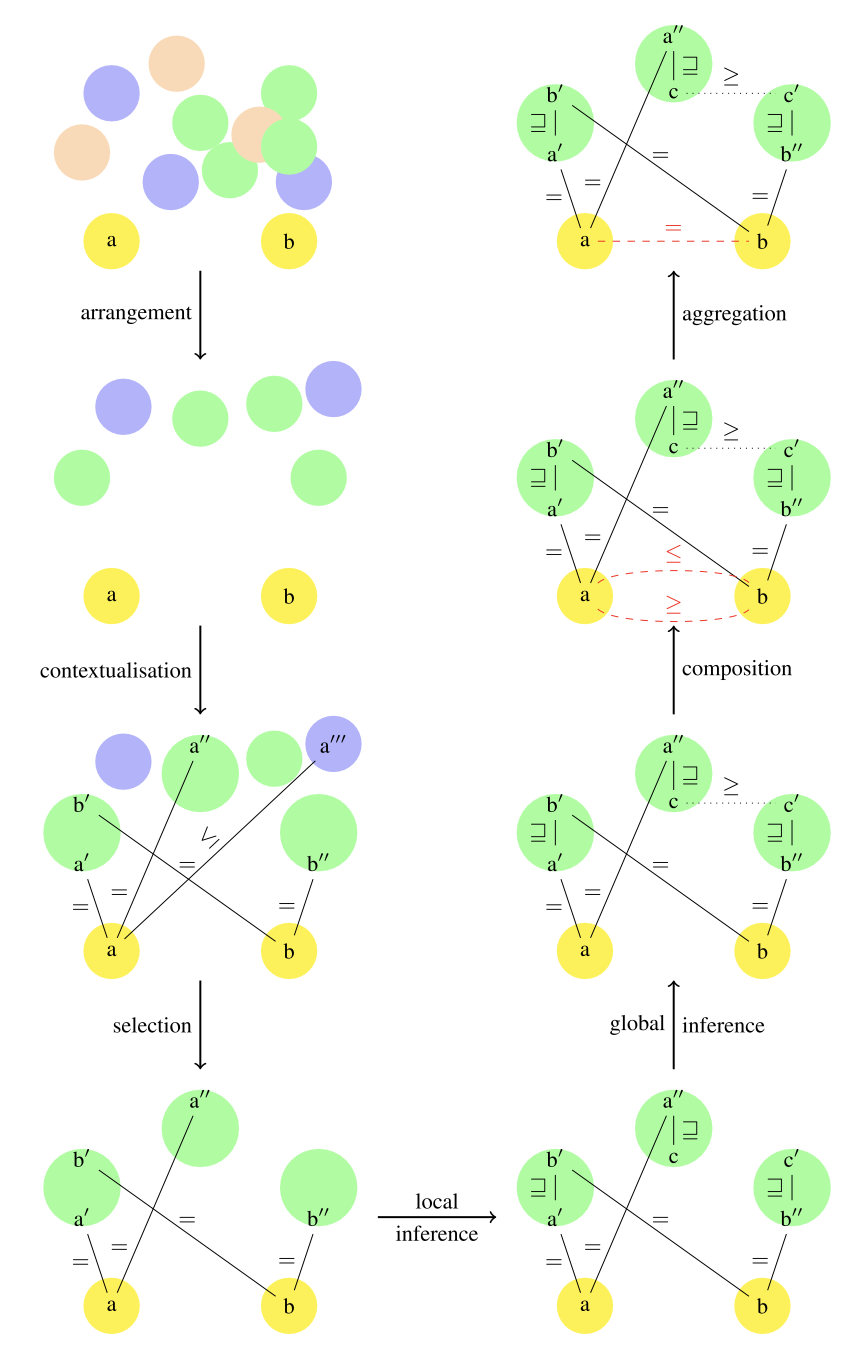
文脈ベースのマッチングは非常に汎用性が高いため、ScarletやOMviaUOなどの既存のマッチャーをカバーし、拡張することを目的とした一般化されたビューでその動作を合成する。このフレームワークでは、背景知識としての形式的なオントロジーの使用を説明しているが、例えば、非公式のリソースやリンクされたデータを扱うために適用することができる。この目的のために、コンテキストベースのマッチングを下図に示す7つのステップに分解する。
オントロジーの配置: 探索するオントロジーを事前に選択し、中間的なオントロジーとしてランク付けする。事前選択では、ウェブ上のすべてのオントロジー、または特定のタイプに属するオントロジー(上位オントロジー、ドメイン固有のオントロジー(例:医学・生物学オントロジー)、コンペティター、人気のあるオントロジー、推奨オントロジー、またはカスタマイズされたオントロジーのセットなど)を保持することができる。
順番付けは、オントロジーが有用であるかどうかの可能性に基づいて行われ、通常は距離として測定される。このような距離は、オントロジーとマッチさせるオントロジーの近さ(David and Euzenat 2008)、オントロジー間のアラインメントの存在(David et al.2010)、または迅速に計算可能なアンカーの利用可能性に基づいている。
文脈化(またはアンカリング)は、マッチングするオントロジーと中間オントロジー候補の間のアンカを見つける。これらのアンカーは、様々な関係や信頼度の測定など、あらゆるタイプの相関関係とすることができる。原則として、本書で紹介されているどのようなオントロジーマッチング手法でもアンカリングに使用することができる。実際には、アンカリングは前段階に過ぎないので、通常は文字列マッチングのような高速な手法を使用する。上図では,aはa′,a′,a′′として文脈化され,bはb′,b′′として文脈化されている。
オントロジーの選択は、実際に使用されるオントロジーの候補を制限するものである。この選択は通常、アンカーが存在するオントロジーを選択することで、計算されたアンカーに依存する。上図では、アンカーがないオントロジーと、アンカーが1つしかない青いオントロジーが除外されている。
局所推論とは、1つのオントロジーのエンティティ間の関係を求めるものとなる。局所推論は、単一のオントロジーのエンティティ間の関係を得るものであり、論理的帰納法に還元することができる。また、シソーラスのように中間資源が正式な意味を持たない場合には、より弱い手順を使用することもできる。その場合は、オントロジーのアサートされた関係や、既存のオントロジーを合成して得られた関係を使用することで置き換えることができる。上図では,b′がa′を包含している。また,a′ ⊒ cやc′ ⊒ b′などの他の関係も推論されている。
グローバル推論では、ローカル推論で得られた関係と、中間オントロジー間の相関関係を連結することで、一致するオントロジーの2つの概念間の関係を見つけます。上図では,前者の推論と新しい対応関係c ≥ c′から,a′≧b′を推論することができる。
コンポジションは、ソースエンティティとターゲットエンティティをつなぐパス(関係の列)の関係をコンポジションすることで、ソースエンティティとターゲットエンティティの間にある関係を決定する。組成方法は、関数型(=-=が=)、順序型(<-≦が<)、関係型(⊥-≧が⊥)がある。上図では、a = a′ ⊑ b′ = bとa = a′ ⊒ c ≥ c′ ⊒ b′ = bという2つの合成をサポートするパスが存在し、次のようなアサーションが得られる。
集約は、同じペアのエンティティ間で得られた関係を結合するものとなる。単純にすべての対応関係を返すことも、集約された関係を持つ1つの対応関係のみを返すこともできる。集約自体は、関係集約演算子、例えば、接続、人気度(最も多くのパスから得られた関係を選択)、信頼度(最も高い信頼度を持つ関係を選択)など、様々な方法に基づいて行うことができる。上図では、2つの前者の関係がa=bとして接続により集約されている。
これらのステップは、Scarletで提供されたものを拡張したものとなる。文脈化はアンカリングと呼ばれ、選択が検討され、ローカルおよびグローバルな推論、および合成が「導出規則」のセットに集められ、集約はコンバインと呼ばれます。GeRoMeSuiteでは、配列(Se-lectionと呼ばれる)、アンカリング、ローカル推論(合成を含む)、集約の各ステップを特定し、そこに整合性チェックを加えています。この発表では、各ステップを異なる形でインスタンス化するために使用できる、コンテキストベースのマッチングのより詳細なデ・コンポジションを提供している。
文脈ベースのマッチングは、完全に論理的な観点から見ることができる。つまり、局所的および大域的な推論はエンテリジェントテストに置き換えられ、合成およびアグレガシオンは論理的な演繹法に置き換えられる。このような場合、アンカーリングを超えて、マッチングはオントロジーのネットワークにおける推論に還元される。したがって、オントロジーのネットワークにおける推論の技術が完全に開発されれば、上記の7つのステップをアンカリングと推論に縮小することが原理的には可能になるだろう(6.5節参照)
文脈ベースのマッチングの難しさは、バランスの問題となる。文脈を追加することで新しい情報が得られるため、想起率を高めることができるが、この新しい情報が誤った対応関係を生み出し、精度を低下させる可能性もある。使用するリソースのタイプや、マッチングするオントロジーとの接続方法については、多くの選択肢がある。
次回はもう一つのオントロジーマッチングである重み付けのアプローチについて述べる。

AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.
