人工知能技術 ウェブ技術 知識情報処理技術 セマンティックウェブ技術 自然言語処理 機械学習技術 オントロジー技術 オントロジーマッチング技術
前回までに紹介した基本技術とグローバル技術は、マッチングシステムを構築するためのビルディングブロックとなる。オントロジーエンティティ間の類似性または非類似性が得られれば、あとはアライメントを計算するだけでよい。これには、より包括的な処理が必要となる。本章では、実用的なマッチングシステムを構築するために、特に以下の点を検討する。
- 必要に応じて、大規模なオントロジーを処理するための準備。
- 様々な類似性やマッチングアルゴリズムの組み合わせを整理する。
- 背景知識ソースの活用。
- エンティティ間の複合的な類似性を計算するために、基本的な手法の結果を集約する。
- エンティティ間の複合的な類似性を計算するために基本的な手法の結果を集約する。
- データからマッチャーを学習し、それをチューニングする。
- 結果として得られた(非)類似性からアライメントを抽出する:実際、異なる特性を持つ異なるアラインメント実際、同じ(非)類似性から異なる特徴を持つ異なるアラインメントが抽出されることがある。
- 曖昧さの解消、デバッグ、修復によるアラインメントの改善。
オントロジーのパーティショニングと検索スペースのプルーニング
マッチャーは、数万から数十万のエンティティを含む大規模なオントロジーを扱わなければならない場合がある。これを効率的に行うためには、オントロジーをより小さなオントロジーに分割して、その小さなオントロジーをマッチングするか、マッチングの際にオントロジーの一部を動的に無視するかのどちらかとなる。
パーティショニング
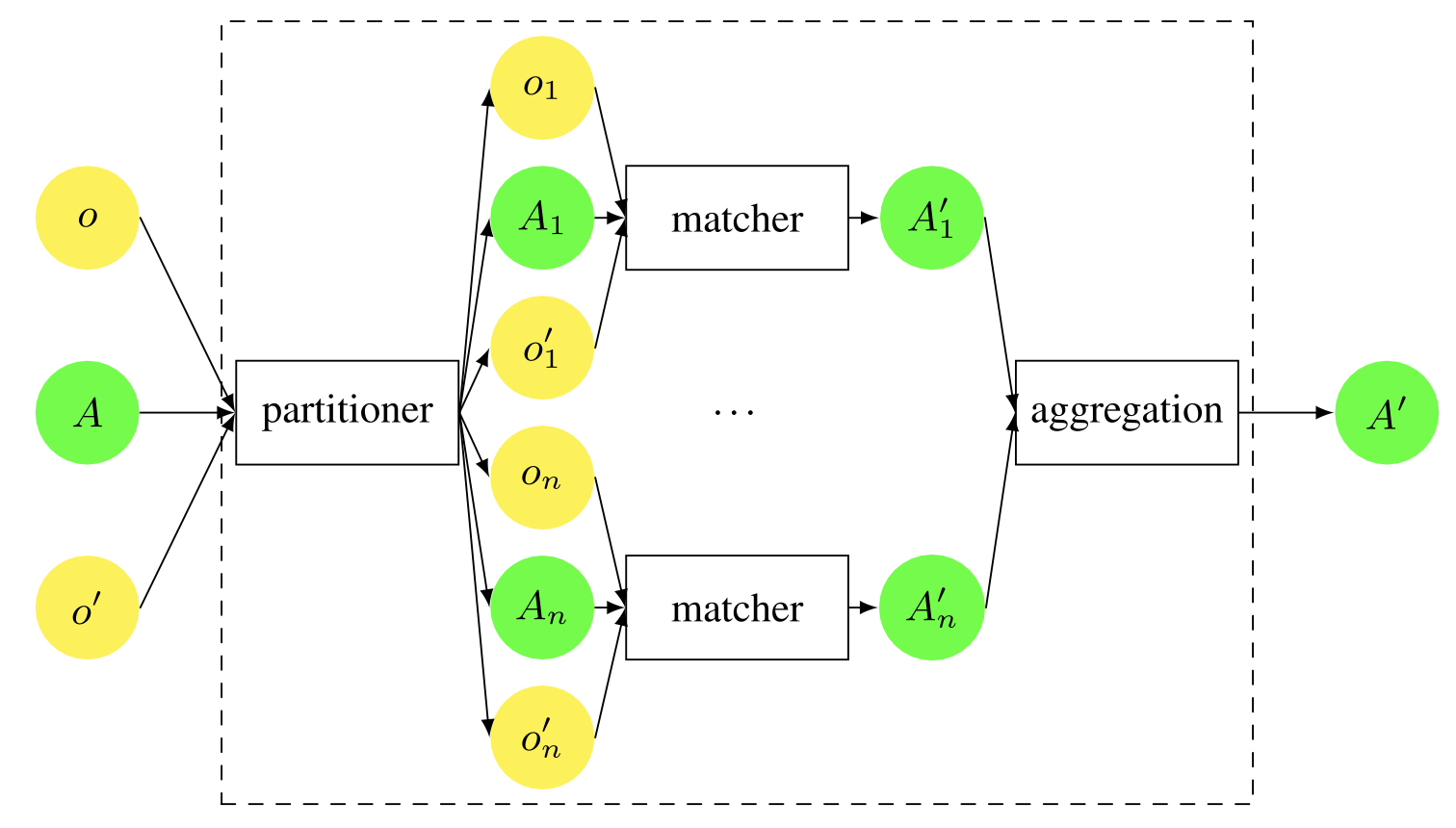
マッチングが必要なオントロジーの一部を分割して、部分的にマッチングを行い、独立したマッチングの結果を集約する(通常は生成された対応関係をすべて受け入れる)ことは、しばしば有用である。これを下図に示す。

パーティショニングの一般的な原則:マッチングするオントロジーは、より小さなオントロジーの断片に分割され、それらは独立してマッチングされ、その結果はマージされる。
このプロセスをオントロジー・パーティショニングと呼んでいるが、これは厳密な数学的パーティショニングではなく、エンティティのセットを網羅的でオーバーラップしないクラスに分割することになる。実際、あるオントロジーの一部は、他のオントロジーに対応するものがないため、単に無視されることもある。
上図は単純化しているが、システムによっては、例えば、トップレベルのエンティティから始めて、得られた結果に基づいて反復的にサブクラスを分割するなど、反復的なパーテイショニングを行う場合がある。また、リーフエンティティからルートに向かって作業することもある。
つまり、オントロジーをブロックに分割し、オントロジー間の比較のデカルト積を避けて、対応するブロックからのみエンティティをマッチングするということになる。技術的には、ブロッキングは、エンティティを多次元インデックスにマッチングさせることで実行され、類似するエンティティはインデックス内で互いに近くに配置される。ブロッキングは、考慮すべきエンティティの数が多いため、データの相互リンクによく用いられる。
パーティショニングやプルーニングの技術では、アンカーを使用することが多い。アンカーを得るための比較的高速な手法は、あるハッシュ関数に正確に一致するノードを持つエンティティを見つけることになる。そのためには、すべてのノードを比較する(複雑度O(n2))代わりに、一方のオントロジーのすべてのエンティティのインデックスを、典型的にはハッシュテーブルを介して構築し、他方のオントロジーの各エンティティについて、対応するインデックス付きの用語があるかどうかをチェックすることにより可能となる(複雑度。O(2n))。)
パーティショニングにおいて、オントロジーのモジュール化のために開発された技術(Stuck- enschmidt et al. 例えば、Falcon-AO) では、ROCK凝集型クラスタリングアルゴリズム (Guha et al. 1999) を用いてオントロジーをブロック単位でクラスタリングする。このアルゴリズムでは、ブロックを設計するために2つの基準を考慮している。すなわち、ブロックの内部結合力と、ブロックと他のオントロジーの別のブロックとのペアリングとなる。これらは、2つのクラス(ブロック)のセットBとB′が与えられたときに、1つの良さの尺度にまとめられる。
リンクは2つのクラス間の正規化された類似性指標であり、迅速に得られるようになっている。次に、Falcon-AOは語彙的類似性とWu-Palmer類似性の加重和を用いて比較されるブロックをペアにする。マッチングされるブロックのペアの選択は、それらの間のアンカーの利用可能性に基づいている。これらのアンカーは、他のブロックのアンカーと比較される。この尺度が事前に定義された閾値よりも優れている場合、ブロックはマッチングされる。
TaxoMapは、Falcon-AO法を改良し、2つのパーティション間に依存性を導入しようとする2つのパーティショニング法を提供している(Hamdi et al. 2010b)。1つ目のアルゴリズムであるPartition-Anchor-Partitionは、まずオントロジーの1つをそれ自身の構造に基づいて分割し、次にオントロジー間のアンカーを計算し、そのアンカーを起点に2つ目のオントロジーを分割する。2番目の方法であるAnchor-Partition-Partitionは、構造化されていないオントロジーに適している。この方法では、2つのオントロジーに見られるアンカーから始めて、2つのオントロジーを分割し、2つ目のオントロジーでは、同じブロックに含まれるアンカーのグループを分割する。どちらの場合も、アンカーに基づいてブロックがペアになる。(Doran et al. 2009) は、マッチング検索スペースを縮小するためのさまざまなパーティショニング戦略の利点を報告している。
パーティショニングは、MapReduceのようなシンプルなパラダイムでマッチャーを並列化するために使用することができる(Dean and Ghemawat 2004; Lin and Dyer 2010)。実際、各ノードは、(1)問題をパーティショニングし、(2)各サブプロブレムをノードが利用可能になった時点で送信し、(3)結果のサブアラインメントを集約することでマップ操作を行い、2つのオントロジーを単純にマッチングしてアラインメントを返すことでリデュース操作を行うことができる。難しいのは、マッチャーに十分な情報を提供しないことでアライメントの質を変えないパーティションを見つけることになる。逆に、より少ないメモリを使用するために、冗長な情報を削除することもできる。特定されたサブプロブレムは、永続的にキャッシュすることもできる。さらに、このキャッシュをクラウド上のノードに複製することで、マッチングタスクの並列ロードを容易にすることができる。
探索空間のプルーニング(刈り込み技術)
刈り込み技術は、オントロジーを事前に分割することなく、部分的に比較することを動的に回避するものとなる。
AROMAは、一般的なものからより具体的なものへと連想ルールを学習していく。各段階で、より具体的なルールを学習することで得られる最大の含意強度を測定することができる。この値が閾値以下の場合、より具体的なルールは考慮されず、多くの比較を避けることができる(David et al.2007)。そして、以前の技術または以前の高速等号によって与えられた2つのアンカーのペアの間の更なる対応関係のみを調査する。
Lilyは、どの比較を避けるかを動的に決定するリダクションアンカーを定義している(Wang et al.2011)。2つのクラスが対応関係にある場合、正のアンカーは、一方のサブクラスと他方のスーパークラスの比較を禁止する。負のアンカーは、あるクラスの近傍と、それが一致しない(または類似度が低い)クラスの近傍の比較を禁止する。
Anchor-Floodも、上記と同様にアンカーから始まる。次に、両方のアンカーの近隣 (またはセグメント) を比較する。つまり、2 階層先のアンカーに接続されたエンティティのセット (親、祖父母、子、孫、兄弟など) を比較することになる。このアルゴリズムでは、このようなアンカーの付いた2つのセグメントのエンティティのみを比較し、アンカーから始まり、すべてのエンティティに到達するまで近隣に広がっていく (Hanif and Aono 2009)。一致するエンティティのペアは、同じタイプの操作(昇順、降順、兄弟)で到達可能なものとなる。
LogMapは、二重の戦略を採用している。まず、ラベルとURIに基づいて、すべてのエンティティのインデックスを作成する。リコールを高めるために、ステムメーキングやレキシコンなどの専門用語のテクニックを使用する。インデックスが付けられたエンティティの各ペアから、correspondenceの候補を抽出する。これらの候補となる冠詞のみがマッチングの対象となるため、比較を制限するのに十分な強さのプルーニングを行う必要があるが、結果として得られるアラインメントの範囲を制限しすぎない程度に弱くする必要がある。さらに、LogMapはセマンティック手法を使用しているため、オントロジーを分割し、各対応関係の候補に関連するオントロジーモジュールのみを使用して検討する。同様に、 PORSCHEと XClustは、ソースオントロジーのエンティティの検索対象領域を狭めるために、まずエンティティをクラスタリングする。
マッチャーの構成
上述したすべてのステップは、グローバルメソッドとして考えられる。グローバルメソッドの目的は、ローカルメソッド(または基本的なマッ チャー)を組み合わせて、新しいマッチングアルゴリズムを定義することになる。ここでは、戦略的なレベルで、マッチャーを組み合わせるための自然な方法をいくつか紹介する。この目的のために、新しいグラフィック要素を徐々に導入していく。
これまでは、図2.8のように、2つのオントロジーからアライメントを作成することで、マッチングプロセスの外側のみを示してきた。基本的なマッチャーを構成する自然な方法は、逐次的な構成を用いてアライメントを改善することである(図7.2参照)。例えば、ラベルに基づくマッチャー(5.2節)を使用した後に、エンティティの構造に基づくマッチャー(5.3節)やセマンティック・マッチャー(6.5節)を実行したいと思う。
 ]この連続したプロセスは、例えば、オンラインでのデータ統合に用いることができる。オントロジーのマッチングと統合は、異なるオントロジー(oとo′)で表現されたデータ(場合によってはデータストリームdとd′)を統合することである。そのためには、事前にオントロジーをマッチングさせておく必要があり、データ統合ではこのアライメントを利用することができます。これはオフラインとオンラインを組み合わせたマッチングの一例である。
]この連続したプロセスは、例えば、オンラインでのデータ統合に用いることができる。オントロジーのマッチングと統合は、異なるオントロジー(oとo′)で表現されたデータ(場合によってはデータストリームdとd′)を統合することである。そのためには、事前にオントロジーをマッチングさせておく必要があり、データ統合ではこのアライメントを利用することができます。これはオフラインとオンラインを組み合わせたマッチングの一例である。
これは次のように考えられます(図7.3参照)。
 インスタンスマッチングは、データフロー(dとd′)を統合するために、事前にオントロジー(oとo′)をマッチングさせておくことを利用した、もう一つのマッチングプロセスです。これは、図1.5(データの相互リンク)で典型的に利用されているものです。
インスタンスマッチングは、データフロー(dとd′)を統合するために、事前にオントロジー(oとo′)をマッチングさせておくことを利用した、もう一つのマッチングプロセスです。これは、図1.5(データの相互リンク)で典型的に利用されているものです。
インスタンストレーニングセットを用いた第1のマッチングフェーズ(f)。
2. 最初のアラインメント(A′)を用いたデータマッチングフェーズ(f′)。
この設定では,第 2 フェーズは,第 1 アライメントのプリコンパイルの恩恵を受ける.実際,2 番目のマッ チャー f′ は,最初のアラインメントをコンパイルしたものと考えることができる.
しかし、マッチャーの逐次的な組み合わせは、より古典的にアライメントの改善に使用される。この目的のために、類似性または距離を使用する場合、マッチャーはその類似性マトリックスを介して順次構成することができる。図7.4では、行列のための新しいシンボルと、初期アラインメントまたはオントロジーのペアから初期行列を抽出するための新しいコンポーネント(最初の三角形)と、類似性または非類似性の行列からアラインメントを抽出するための別のコンポーネント(すずめの尾の三角形、詳細は7.7節で説明)を紹介している。
距離行列や類似性行列を用いた逐次的な構成は、図7.5に示されている。

マッチングされるエンティティ間の類似性または距離尺度を表す(仮想)行列の導入。最初の演算子は、2 つのオントロジー o と o′ から初期行列 M を構築する。マッチングアルゴリズムの中核となる演算子は、この初期行列とオントロジーの記述から、類似性または距離の行列M′を生成する。最後に,行列M′からアライメントA′が抽出される.

アルゴリズムを組み合わせるもう一つの方法は、複数の異なるアルゴリズムを独立して実行し、その結果を集約することとなる。(図7.6参照)。これをパーレル・コンポジションと呼ぶ。このような集計方法は非常に異なっており、ある基準に基づいて結果の1つを選択したり、何らかの演算子で結果を統合したりすることに対応している。例えば、複数のマッチングアルゴリズムを並行して実行し、すべてのマッチングアルゴリズムに含まれる対応関係を選択したり(このとき集約演算子として交点が用いられる)、最も信頼性の高い対応関係をすべて選択したりすることができる。

後者の場合は,類似性行列や距離行列(図7.7参照)に集約演算子を定義する方が便利な場合が多い。これらの技術は7.4節で紹介する。

並列合成には大きく分けて2つの種類がある。
異種並列合成では,入力が異なる種類のデータ(グラフ,文字列,文書の集合など)に分割され,集約は(結果を集約することで)それらすべてを利用するか,最も有望なものだけを利用する。
同種の並列合成では、入力が複数の競合するシステムに送られ、集約はそれらの中から最も良いものを選択するか、またはそれらの間のコンセンサスを選択する。
もちろん、この2つのクラスをさらに組み合わせることも可能となる。
これらの合成技術は、通常、特定のマッチングアルゴリズムの中に実装される。しかし、他のシステムを組み合わせる機会を提供するシステムもあり、例えばFOAM、Rondo、Alignment APIなど、他のシステムを組み合わせる機会を提供するシステムもある。
次回はコンテキストベースのマッチング戦略について述べる。

AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.
