Artificial Intelligence Technology Web Technology Knowledge Information Processing Technology Semantic Web Technology Ontology Technology Natural Language Processing Machine learning Ontology Matching Technology
In the previous article, we discussed the language-based approach. In this article, we will discuss an internal structure based approach.
Instead of, or in addition to, comparing names and identifiers, we can compare information about the structure of the entities in the ontology. This comparison can be subdivided into comparison of the internal structure of the entity, i.e., in addition to names and annotations, comparison of properties or, in the case of OWL ontologies, properties that take values in data types, and comparison of the entity with other entities that the entity is related to. The former is called internal structure and the latter is called relational structure. Internal structure refers to the definition of an entity without reference to other entities, while relational structure refers to the set of relationships that an entity has with other entities. As expected, internal structures are mainly used for database schema matching, while relational structures are more important for formal ontology and semantic network matching. In this article, we will only discuss methods based on internal structure, and external structure and relational methods will be discussed separately.
Internal structure-based methods are sometimes referred to as constraint-based approaches in the literature (Rahm and Bernstein 2001). These methods are based on the internal structure of the entities and use criteria such as the set of properties, the range of properties (attributes and relations), cardinality or multiplicity, and the transitivity or symmetry of properties to calculate the similarity between entities.
In two ontologies, there may be many entities with similar internal structure or properties with similar domain or scope. Therefore, these methods are often used to create clusters of correspondences, rather than to reveal the exact correspondences between entities. These methods are usually used in combination with other element-level methods, such as terminology, which serve to reduce the number of candidate correspondences. They can be used in conjunction with other approaches as a preprocessing step to eliminate most of the apparently incompatible properties.
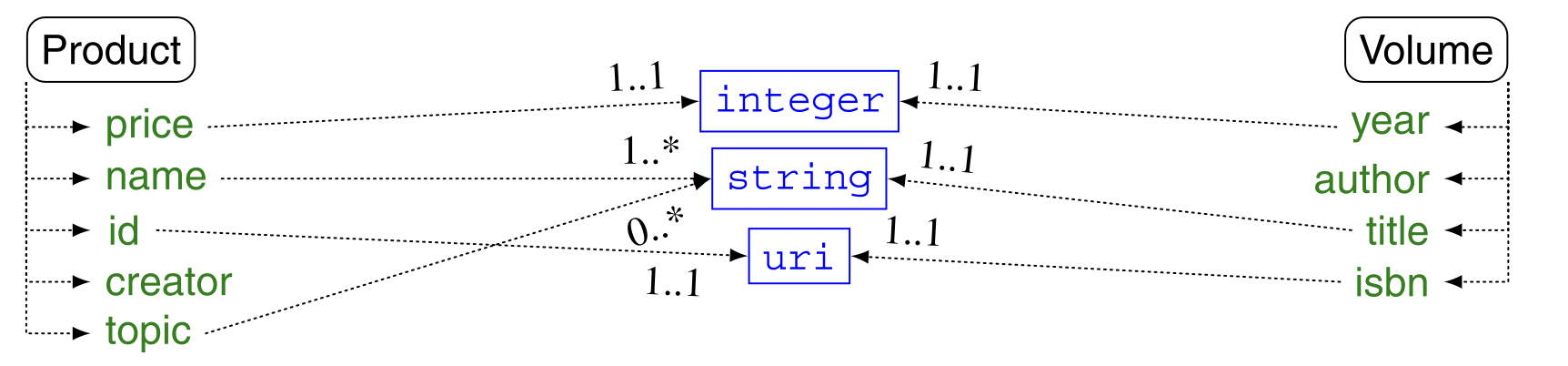
To illustrate these methods, let’s consider the properties associated with the Product and Volume entities in the example below.

Starting from the elements in the diagram above, there is no possibility that a pure term similarity method would determine that they are very similar because they have completely different vocabularies. However, in the case of the edit distance method, there is a possibility that year and creator may look the same, and it may be easier to find the relationship between creator and author using linguistic methods.
Comparing the internal structure of ontology entities can be reduced to combining their properties and synthesizing the results obtained. The system can then evaluate the similarity between all considered components (names, keys, data types, domains, cardinality) or multiplicities and combine the results. The combination operation will be discussed in another article, but here we focus on the basic comparison.
Property Comparison and Keys
In a database schema, unlike a formal ontology, tables are provided with keys. This will be a combination of properties that uniquely identify an object by value. For books, this is typically the international standard book number (isbn), and for people, it is name, place of birth, and date.
This information is primarily very useful for recognizing that two individuals are the same. Thus, keys are mostly used in extension methods as a means to identify individuals and apply the method to common instances.
However, keys can also be used to identify classes. Two classes identified in the same way are likely to represent the same set of objects. Furthermore, even if two schemas use different keys for the same class, there may be secondary keys that perform the same function, for example, if you identify a Person by his social security number, the social security number is also considered a key for the other class. Therefore, when keys are provided, it is plausible for the classes to be equivalent if they are highly interchangeable (similar in name and type).
For example, if a Product has id as a key and a Volume has isbn as a key, we can assume that these properties should correspond if the classes are the same. This is considered possible because both properties have the same type (uri).
Comparing Data Types
In property comparison, we compare the data types of properties (in OWL, this would be Restriction, which applies to a range of relations and class properties). In contrast to objects, which require interpretation, data types can be considered objectively, and it is possible to determine how close one data type is to another (ideally based on interpreting the data type as a set of values and comparing these data types in a set-theoretic way). (Valtchev 1999; Valtchev and Euzenat 1997)).
Here we distinguish between data types that correspond to the way values are stored in the computer (e.g., integer, float, string, uri) and domains that characterize a subset of a particular data type (e.g., [10 12], ‘*book’). We will consider data types first, and domains will be discussed in the next section.
Data types are not completely separate, but there are rules that allow us to consider an object of one type as an object of another type, or to convert a value of one type into a memory representation of another type (called a cast in programming languages).
Ideally, the proximity between data types will be maximum when they are the same type, lower when the types are compatible (for example, integer and float are compatible because one can be cast to the other), and minimum when they are incompatible. Ideally, the comparison of domains should also be based on the comparison of data types and the set of values covered by these data types. The compatibility between property data types can be evaluated using lookup tables. The table below shows an example.

Such a table can be extracted from the type hierarchy of XML Schema data types in a language like OWL. In the example below, since uri is a subclass of string, it is possible that isbn is related to name.

In the example of comparing the data types of Product and Volume, the data type comparison results in a match between price and year, both name and topics and title, and id and isbn. creator and author are excluded because they are object-valued properties. This collation gives interesting results, as it matches as expected. However, it also finds the wrong ones (price-year and topics-title), which shows that these methods cannot be used in isolation.
Domain Comparison
Depending on the target entity, there are different things that can be obtained from a property, such as a domain for a class and a value for an individual. Furthermore, they may consist of sets or sequences. Therefore, it is important to take this fact into account when making comparisons.
The type or domain of a property can be compared based on its interpretation (set of values) (Valtchev 1999). The comparison of types is made on the basis of their respective sizes, where the size of a type is the cardinality or multiplicity of the set of values it defines. the distance between two domains is given by the difference between their sizes and the size of a common generalization. This measure is usually normalized by the size of the largest distance associated with a particular data type. The following definition gives an example of this type of measure.
Definition 32 (Relative size distance) and e′ The relative size distance δ : 2τ × 2τ → [0 1] on data type τ is as follows.
\[\delta(e,e’)=\frac{|gen_{\tau}(e∨e’)|-|gen_{\tau}(e∧e’)|}{|\tau|}\]
genτ (…) provides a generalization of the type representation, and ∨ and ∧ correspond to the union and intersection of types.
As an example of relative size distance, consider comparing the characteristic age of one class with that of three other classes (schoolchild, teenager, and grown-up). The domain of the first property is [6 12], while the domains of the other properties are represented respectively as follows. Let it be represented by [7 14], [14 22] and ≥10. All of these properties have a data type of integer. The generalization of these four domains is the domain itself, whose union set with [6 12] is [6 14], [6 22], and [6 +∞], and whose common parts are [7 12], φ, and [10 12], respectively. The resulting distances are 3/|τ|, 17/|τ|, and|τ|-3/|τ|. This corresponds to the intuition that the distance between domains depends on the difference between the values covered by the domains alone and the values covered by them in common.
This metric has three advantages. The most obvious one is that it is normalized; the second is that it is general (not expressed in integers); and the third is that it can be easily mapped to a commonly used general measure.
Usually, the generalization depends on the type. For enumerated types, it is a set; for ordered types, it is an interval (sometimes it is a set of intervals). For dense types, the size of the domain is the usual measure (Euclidean distance can be used for real and floating point numbers). The case of infinite types has to be dealt with appropriately (either by evaluating the largest possible domain on a computer or by normalizing with respect to the actual corpus) (Valtchev 1999). If possible, it is often a good idea to normalize at the largest possible distance in the corpus. Indeed, for example, it is not reasonable to normalize a person’s age by the age or size of the planet, even if the same units are used. Another advantage of this framework would be that it encompasses value comparisons, which can be thought of as co-occurrence representations and can be compared to domains as needed.
Multiplicity vs. properties
Properties can be constrained by what is called “multiplicity” in UML. The multiplicity is the acceptable radix of the set of values of a property (for a given object). As with compatibility between data types, compatibility between radixes can be established based on table lookups. An example of such a table is shown in the table below (Lee et al. 2002).

In OWL, cardinality and polynomials are represented by the restrictions of minCardinality, maxCardinality, and cardinality. Multiplicity can be represented as an interval of a set of positive integers [0 +∞]. Therefore, it is an integer domain. two multiplicities are compatible if the intersection of the corresponding intervals is non-empty. Any measure of integer data type can be used to evaluate the similarity between multiplicities, but here we use a simpler distance inspired by the Jaccard similarity.
Values can be collected by specific structures (sets, lists, multisets) where cardinality constraints are applied. Again, these constructed data types can be compared by comparing (i) the constructed data types and (ii) the applied cardinality. For example, the set of two and three children is closer to the set of three people than to the set of 10-12 flowers (if the children are people). This technique is used in (Euzenat and Valtchev 2004).
Definition 34 (Similarity of multiplicities) Given two multiplicity representations [b e] and [b′ e′], the similarity of multiplicities is the similarity between non-negative integer intervals σ : 2τ × 2τ → [0 1] as follows.
\[\sigma([b,e],[b’,e’])=\begin{cases} 0&if\ b’>e\ or\ b>e’\\\frac{min(e,e’)-max(b,b’)}{max(e,e’)-min(b,b’)}&otherwise \end{cases} \]
For example, when comparing multiplicity [0 6] with [2 8], [8 12], and [0 +∞], the comparison results in 0.5, 0., and 6/MAXINT, respectively (the latter is a very low value but remains non-null because it is compatible with the initial multiplicity).
Example of multiplicity comparison , In the Product and Volume example, using multiplicity comparison, we can further match id and isbn because they both have cardinality of [1 1] and unfortunately price and year also match. However, since is has the same multiplicity ([1 +∞] instead of [0 +∞]), it can also be used to match names instead of topics to titles.
Other Features
Other internal structural factors are also taken into account in database schema matching. Among these additional characteristics are uniqueness, static semantic completeness constraints, dynamic semantic completeness constraints, security constraints, al-lowable operations, and scale (Navathe and Buneman 1986). Since these are internal properties, they can be highly dependent on the knowledge model.
Also, depending on the language, it may be possible to consider collection constructors such as Set, List, Bag or multiset, Array and their compatibility. In that case, it is necessary to compare sets or lists of objects, for example, an array of topics or a set of authors of a book. In this case, common techniques can be used to evaluate the similarity or distance between these sets, depending on the similarity applied to the type of elements. For sets, these techniques have been described previously in the context of extended comparisons. As for sequences, we can apply the measurement methods that consider a string as an array of characters and a path as an array of strings. Furthermore, in the next section, we will explain to the method of comparing a set of similar objects.
(Ehrig and Sure 2004) uses a set of rules to determine the similarity between ontology entities. The authors point out that several features related to the internal structure of OWL, such as symmetry and value restrictions, can be used, but are discarded because they are not widely used at this time.
Summary of methods based on internal structure
The internal structure, including the names of the entities, is very important for matching because it provides a reliable basis for the algorithm. Also, the techniques for comparing them are efficient and easy to implement.
However, the internal structure does not provide much information about the entities to be compared. Many very different types of objects may have properties of the same data type. On the one hand, they can be used to eliminate incompatible correspondences and to promote compatible ones. On the other hand, it is always possible for different models of a concept to use different, incompatible types. For these reasons, internal structure comparison should always be used in conjunction with other techniques.
This section describes the internal structure comparison approach. In the next article, we will discuss the data extension approach.


コメント