Rによるクラスタリング – k-means
前回はRでのクラスタリングの例として、階層クラスタリングについて紹介した。今回は非階層クラスタリングであるk-meansについて紹介する。
kmeans関数は以下となる。
> kmeans(x, centers, iter.max = 10, nstart = 1,algorithm = c("Hartigan-Wong", "Lloyd", "Forgy", "MacQueen"))関数 kmeans はクラスターの分類結果 ($cluster)、クラスターの中心ベクトル ($centers)、各クラスター内の個体数 ($size) などを返す。上記の関数でxはデータ、centersはクラスターの数、または クラスターの中心で、クラスタの数であれば、 クラスターの中心はランダムに与えられる。iter.maxは処理の繰り返し数の最大。nstartはランダムに初期値を設定する時のパラメータ。algorithmは計算アルゴリズムで (“Hartigan-Wong“, “Lloyd“, “Forgy“, “MacQueen“) . デフォルトは “Hartigan-Wong“となる。irisのデータを用いてkmeanを実行し、関数 kmeans の実行後、km$cluster にクラスターの分類結果が記録されるので確認する。
> data <- iris[,1:4]
> km <- kmeans(data,3)
> result <- km$cluster
> result
[1] 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
[36] 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 2 2 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
[71] 2 2 2 2 2 2 2 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 1 2 1 1 1
[106] 1 2 1 1 1 1 1 1 2 2 1 1 1 1 2 1 2 1 2 1 1 2 2 1 1 1 1 1 2 1 1 1 1 2 1
[141] 1 1 2 1 1 1 2 1 1 2データが 1,2,3 の3つのクラスターに振り分けられていることがわかる。clusterパッケージを読み込み、 クラスタリング結果をプロットする。
> install.packages("cluster")
> library(cluster)
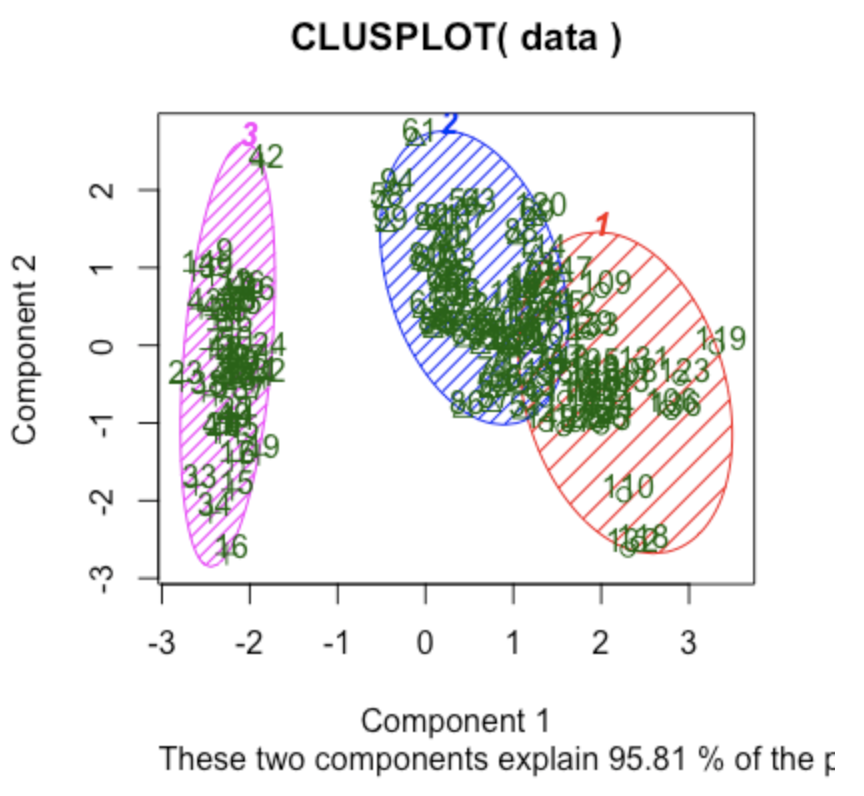
> clusplot(data, km$cluster, color=TRUE, shade=TRUE, labels=2, lines=0)
irisデータの5列目 Species のデータを 変数 answer に代入し、品種とクラスタリング結果のクロス表を作成し、分類精度を確認する。
> answer <- iris[,5]
> table <- table(answer, result)
> table
result
answer 1 2 3
setosa 0 0 50
versicolor 2 48 0
virginica 36 14 0クロス表から、150サンプル中 (50+48+36=)134サンプルを正確に分類できたことが分かる。
上記の例ではirisでの処理を紹介したが、自然言語処理のところで紹介した形態素解析のツールを使って、文章の中の単語を抽出し、それぞれの単語に番号を振ったデータをCSVとして入力してクラスタリングをする等、同様の手法で、現実世界の課題からデータを生成して処理することもできる。
今回は、教師なし学習であるk-meansを用いた分類を述べてみた。分類のタスクとしては、これら以外にも教師あり学習を用いた分類もよく使われる。
なおpythonでのk-meansに関しては”k-meansの概要と応用および実装例について“を参照のこと。
次回はこれら機械学習や自然言語処理に欠かせない前処理ツールであるopenrefineの紹介を行う。

AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.
