Rによる階層クラスタリング
前回までで、Rのインストールからデータの導入、そして実用的な機械学習の応用として使われる頻度の高いクラスタリングについて、データの準備までを述べた。今回はその続きとして、階層クラスタリングでの学習と評価について述べる。
階層クラスタの関数hclustは以下になる。
hclust(d, method = "使用メソッド")dは距離で、methodは使用する距離測定メソッドとなる。methodとしてはsingle(最短距離法)、complete(最長距離法)、average(群平均法)、centroid(重心法)、median(メディアン法)、mcquitty(McQuitty法、ward.D2(ウォード法)となる。関数hclustの実行は以下となる。
> distance <- dist(data)
> hc <- hclust(distance, "ward.D2")
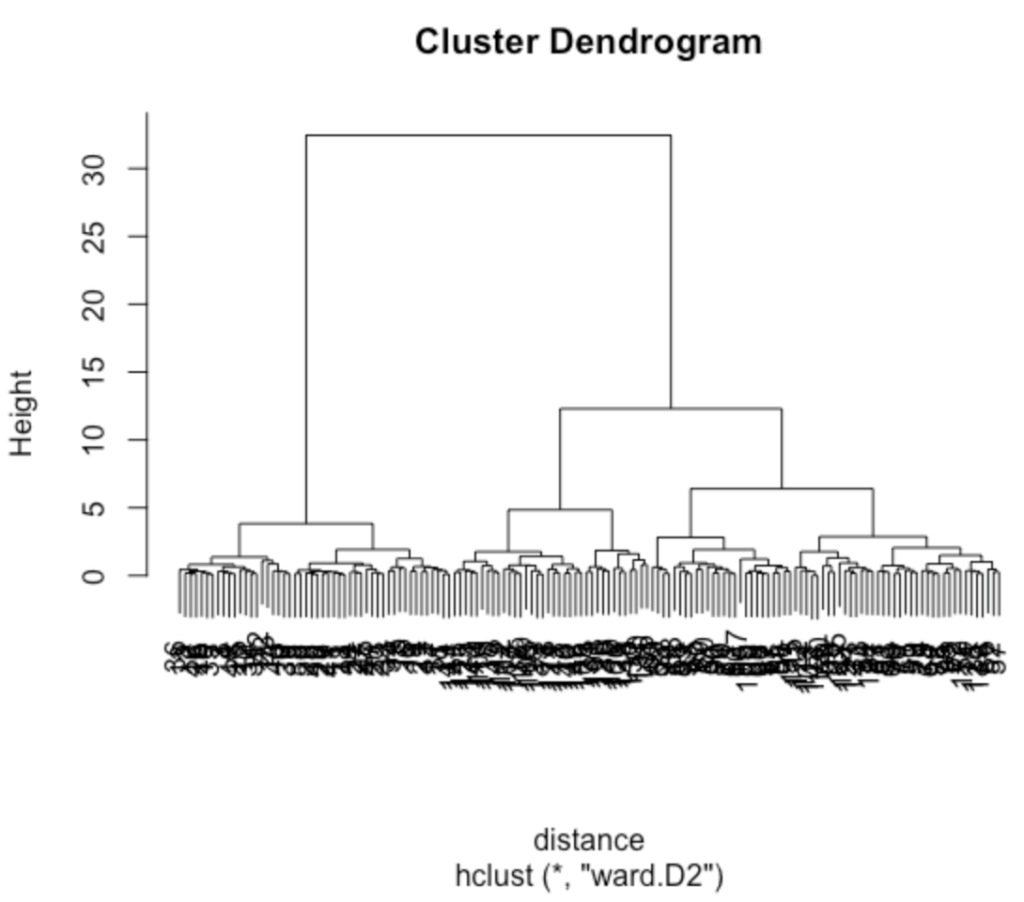
> plot(hc)distance変数に関数distで求めた距離を入れ、変数hcに関数hclustで求めたウォード法での値を入れる。そして最後にplot関数で結果を表示する。結果としてデンドグラム(樹形図)が出力される。

データの分割にはcutree関数を用いる。cutree関数は以下になる。
cutree(tree, k = NULL, h = NULL)treeは分割したいデータ(今回はhc)、kはクラスター数、hは樹形図を分割する高さとなる。3つのクラスタに分ける場合は以下となる。
> result <- cutree(hc,k=3)
> result
[1] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
[36] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
[71] 2 2 2 2 2 2 2 3 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 3 2 3 3 3
[106] 3 2 3 3 3 3 3 3 2 2 3 3 3 3 2 3 2 3 2 3 3 2 2 3 3 3 3 3 2 2 3 3 3 2 3
[141] 3 3 2 3 3 3 2 3 3 2データが1,2,3の3つに分けられていることが確認される。次にirisデータの5列目 Species のデータを 変数 answer に代入し、品種とクラスタリング結果のクロス表を作成し、分類精度を確認する。
> answer <- iris[,5]
> table <- table(answer, result)
> table
result
answer 1 2 3
setosa 50 0 0
versicolor 0 49 1
virginica 0 15 35クロス表から、150サンプル中 (50+49+35=)134サンプルを正確に分類できたことがわかる。
次回は非階層クラスタリングであるk-meansについて述べる。

AIシステム設計・意思決定構造の設計を専門としています。
Ontology・DSL・Behavior Treeによる判断の外部化、マルチエージェント構築に取り組んでいます。
Specialized in AI system design and decision-making architecture.
Focused on externalizing decision logic using Ontology, DSL, and Behavior Trees, and building multi-agent systems.
